
4.1: Phonetic Contexts
- Last updated
- Save as PDF
- Page ID
- 7017

Lexical and Phonological Knowledge
Exercise \(\PageIndex{1}\)
I've been claiming that the sounds of a human language are clustered into categories called phonemes. As a speaker of English, then, what do you have to know to be able to pronounce an English word, say, the word fun? Hint: some of what you know is about just that word and some of what you know is more general.
The main point of what I said about the sounds of spoken language in the last chapter was to show what phonemes are. Let's review this concept.
- They are specific to particular spoken languages (or dialects actually); that is, learning a language means in part learning the phonemes of the language.
- They are categories, with all of the familiar properties that categories have.
- Phonemes are realized as individual sounds (phones), instances of the categories, that may differ from one another but are centered on aprototypical member. That is, a phoneme is not really a phone, but an abstraction over a collection of phones.
- Phonemes divide a continuous space (one or more continuous dimensions) into a small set of types.
- Individual phones are categorized by hearers as belonging to one or another of the phonemes of the hearers' language. Phones that are closer to the prototypical member are easier to categorize. Phones that are within a phoneme are perceived as closer to each other than phones that belong to different phonemes, even when the real difference is the same (categorical perception).
- Phonemes provide a kind of "alphabet" in terms of which speakers and hearers remember the pronunciations of words.
Let's focus on the last point for now. I tried to argue in the section on phonemes that phonemes provide a more efficient way of remembering a large number of words than the alternative. How might this memory system work? We'll concentrate on what the Speaker has to remember. Let's take the English word fun, which we assume is stored in the Speaker's (and the Hearer's) memory as the sequence of phonemes that we have been writing as /fʌn/. (Of course the claim is not that anything like these symbols is written in the person's brain, only that there is some representation of the three phoneme categories and their order.)
Remembering How to Pronounce an English Word Involves Specific Knowledge About that Word and General Knowledge About the Pronunciation of English.
Now how would the Speaker use this representation in memory to actually pronounce the word fun? Another sort of knowledge is needed: knowledge about how each phoneme is realized in terms of articulation. So for /f/ the Speaker would need to know to bring the lower lip in contact with the upper teeth and pass air through the opening without vibration of the vocal cords. And for /ʌ/ the Speaker would need to know to open the mouth a certain extent and raise the body of the tongue somewhat while causing the vocal cords to vibrate. Finally for /n/ the Speaker would need to know to bring the tongue tip in contact with the alveolar ridge, to lower the velum, and again to cause the vocal cords to vibrate.
I'll refer to this knowledge about how phonemes are produced as realization rules. This is our first use of the term rule, which you'll meet a lot later in this book. It refers to general knowledge about what to do in a particular kind of situation. Notice how this differs from the way the word rule is used outside of social science; realization rules are learned but not taught, and speakers are not conscious of the rules they know. And calling the knowledge a "rule" should not make us think that it takes the form of some sort of explicit statement in the brain of the Speaker. In fact little is known about the precise form that rules take; this is currently an area of great controversy in cognitive science.
Just as the Speaker needs to know how to produce each phoneme, the Hearer (who of course is also a Speaker) needs comparable knowledge for how to perceive each phoneme, knowledge about what the phonemes sound like. However, since I have had little to say about the acoustic or auditory properties of phonemes, I'm not in a position to spell out in more detail what this knowledge is.
The two kinds of knowledge, knowledge about the form of a particular word in terms of a sequence of phonemes and knowledge about how particular phonemes are articulated or recognized, differ in one very important way. Knowledge about the form of particular words must be memorized for each word; none of this is general knowledge. This knowledge belongs in the lexicon, the storehouse of knowledge about particular words. On the other hand, knowledge about how phonemes are produced or perceived is general; it applies to all words containing the phonemes. This knowledge is part of the Speaker's and Hearer's phonology, that is, general knowledge about the form that words can take in the language. The figure below illustrates these two types of knowledge.
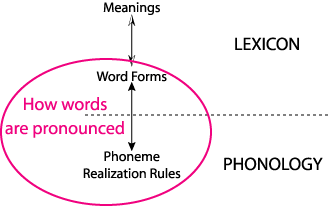
The fact that phonological knowledge is general means that it applies to other words as well. For example, the word laugh /læf/ also contains the phoneme /f/, so the realization rule for /f/ applies to this word as well. And the word no /no/ also contains the phoneme /n/, so the realization rule for /n/ applies here too. These examples are illustrated in the figure below. The arrows below the phonemes indicate that each phoneme gets spelled out as a set of articulatory actions and an auditory pattern. The arrows all go in both directions because the knowledge has to be usable by both speakers (down in the figure) and hearers (up in the figure).
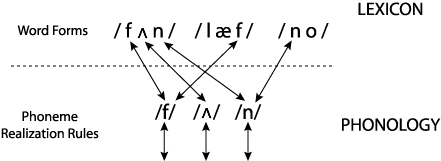
The same would hold true for other languages, except that the phonemes would be different (so the knowledge about how they are produced and perceived would be different), and of course the words would also be different.
Realization rules may also specify how combinations of phonemes are pronounced. One confusing area in English is the behavior of the sonorants /m, n, ŋ, l, r/ in unstressed syllables, in words like prizm (/m/), happen (/n/), incredible (/ŋ, l/), under (/r/). One possibility is to see these in each case as a vowel, /ə/ or /ɪ/, followed by one of the sonorant consonants. So prizm is /'prɪzəm/, and incredible is /ɪŋ'krɛdəbəl/. But, as we saw in the section on English sonorants, the unstressed vowel is sometimes not pronounced; instead the sonorant is syllabic, behaving almost like a vowel. Sometimes this is the only natural pronunciation; sometimes it depends on the speed and informality of the situation. So a relatively casual pronunciation of incredible is [ŋ̩'krɛdəbl̩] (recall that a short line under a consonant symbol indicates a syllabic consonant). Since this knowledge about how to realize combinations like /əl/ is general knowledge about English, we can put it in the realization rules in the phonological component.
Phonemes in Context
Exercise \(\PageIndex{2}\)
Listen to the sound represented by the letter "t" in the word put in the following sentences.
- Put something on.
- Put me down.
- Put it on the table.
- Put this on.
- Put your shirt on.
If you listen carefully, you may hear as many as five different "t" sounds. What does this mean? Should we assume that English speakers have five different phonemes in place of the single /t/ that we discussed in the section on English consonants? Keep in mind what phonemes are and what function they serve in language.
But the picture is not this simple. Remember point 2a about phonemes above: the actual instances of a given phoneme will differ from one another. So one /f/ will not necessarily be the same as another /f/. But are the differences just random? Let's consider /t/, where the variations are quite striking. Take the word at, which in terms of the phonemes that have been proposed would be represented in the lexicon as /æt/. Given what we've said so far about English /t/, the realization rule for this phoneme would have to include specifications that the speaker place the tip of the tongue against the alveolar ridge and produce the sound without vibration of the vocal cords. (The specification is intentionally somewhat vague about how the consonant is released so that it can apply to /t/ at both the beginnings and the ends of syllables.)
English /t/ has a Number of Different Pronunciations
This works fine for the /t/ in at when the word appears before a word beginning with /f/ (at four o'clock) or /s/ (at six o'clock), say. But when it appears before a word beginning with /θ/ (at three o'clock), and we say it in a natural way, we see that the tongue tip is not against the alveolar ridge, but against the teeth, as for a dental stop ([t̪]). And when it appears before a vowel (at eight o'clock), the consonant, as pronounced by North Americans anyway, is voiced and articulated as a tap rather than a stop. In fact it is very similar to the Spanish /r/, that is, the phone that is more accurately represented in our notation by [ɾ]. So we see that not only does the final consonant in at take different forms, there is a regularity to the forms it takes; the pronunciation depends on what phoneme follows that consonant.
How are we to deal with this kind of variability in our theory of how the pronunciation of words is represented? One possibility would be multiple representations of the word at in the lexicon: /æt/, /æt̪/, /æɾ/. Since we would now be using /t̪/ and /ɾ/ to represent words in the lexicon, these would have to be seen as English phonemes, in addition to /t/. But note that this wouldn't be enough; a list of different pronunciations of the word would have to say something about when each one was appropriate, for example, use /æɾ/ when the next word begins with a vowel. And of course the phonological component of memory would need to specify how /t̪/ and /ɾ/ are produced and perceived, as well as /t/.
But this would be a strange way for language to work. Why should speakers be forced to remember more than one form for a word? The whole point of phonemes (at least that is what I'm trying to argue) is to make words easy to remember. Recall also that the lexicon is supposed to be for knowledge about specific words, notgeneral knowledge about how words are pronounced. If the information about different ways to pronounce at applies to more than just the pronunciation of at, then it does not belong in the lexicon; it belongs in the phonological component. If we examine a lot of English words, we discover that many of them (for example, put and let, as illustrated in the box above) end in consonants that behave exactly like the consonant at the end of at. In each case the different pronunciations of that consonant depend on the first phoneme in the next word.
The English Phonological Component Tells How to Pronounce /t/ in Different Contexts
So now consider a second alternative. The lexicon records only one pronunciation of at, /æt/, and the phonological component specifies how the /t/ is to be pronounced (or perceived). The difference from the simple picture described in the last subsection is that this specification has to refer to what comes after the /t/. So it would include something like the following: if /t/ is followed by a dental fricative, place the tongue against the upper teeth, and a corresponding statement for each of the other variant pronunciations. Now the realization rule for /t/ is really a set of rules, one for each type of following phone and the corresponding realization of /t/. The different realizations of a phoneme are called its allophones. We'll come back later to a more detailed statement of what the realization rules and allophones for English /t/ are. For now, there are these important points to note.
- An allophone is always an allophone of some phoneme; it makes no sense to say simply that a particular phone is an allophone in a language. So in English we've seen that [t], [t̪], and [ɾ] are all allophones of the English phoneme /t/.
- This sort of knowledge about how a phoneme is realized as different allophones is general knowledge that speakers have about English, not about particular English words. It is in fact part of the knowledge of what the different English phonemes are.
- The different ways in which a phoneme such as /t/ is pronounced, that is, the allophones of /t/, are similar. They differ at most in one or two features from each other. In fact /t/ is a rather extreme example for English; a phoneme such as /f/ varies relatively little.
- The realization of the phoneme pronounced as one or another allophone usually depends on what other sounds are near the phoneme in question, that is, on the phonetic context of the phoneme. In the section on assimilation, we'll learn more about how contexts determine allophones, and in the section on distribution, we'll learn about how you can use the different contexts that phones appear in to decide whether they're allophones of a single phoneme or separate phonemes.
- Allophones are not categories. This means that speakers and hearers do not need to categorize the different allophones of English /t/. The only category they need among these variants is /t/. It also means that hearers may not even notice the difference between the different allophones of a phoneme. As far as they are concerned, they all belong to the same category. This fact is often reflected in writing systems, which almost never assign different characters to different allophones of a phoneme. So English uses a single letter "t" for all of the allophones of the phoneme /t/.
Let's look at a Spanish example of the same phenomenon. Consider the word de 'of, from'. If we listen to this word spoken in isolation or at the beginning of a sentence, for example in the expression de nada 'don't mention it', we would conclude that its form consists of the two Spanish phonemes /d/ and /e/. As in the English example above, the actual pronunciation of the word would require knowledge about how /d/ and /e/ are articulated, that is, realization rules for these phonemes. This is a different language, so the realization rules would not be the same as for the English phonemes that we write with /d/ and /e/. Thus Spanish /d/ is a dental, not an alveolar, stop ([d̪]), but the basic principle still applies: phonological knowledge is general; it applies to many words.
But consider now how the word de sounds when it appears in a phrase following a vowel, for example, in un vaso de leche 'a glass of milk'. Here the consonant in deinvolves no complete closure between the tongue and upper teeth, so this is not a stop. Some people refer to this sound as a fricative, but since the closure is usually not close enough to allow for any of the turbulence associated with fricatives, it's better seen as an approximant. However, since the difference won't matter for our purposes, I'll use the same symbol that was used for the English voiced dental fricative, [ð], for this sound.
Like English /t/, Spanish /d/ Varies in a Predictable Way
As in the example of English /t/, we need to ask whether this variability in the initial consonant is a special property of the word de or whether it's true of Spanish words in general. A brief examination of words containing the voiced dental stop ([d̪]) and the voiced dental approximant ([ð]) in Spanish reveals that this is a general feature of Spanish phonology. So the word de has one form in the lexicon, /de/, and the phonological component spells out how /d/ is realized in terms of specific articulations in different phonetic contexts, that is, as different allophones. Here is rough statement of how Spanish /d/ is pronounced.
- When /d/ appears at the beginning of a word following a break, or when it appears following /n/ or /l/, it is pronounced as the voiced dental stop [d̪].
- Otherwise /d/ is pronounced as the voiced dental approximant [ð].
The Spanish example should make two more points clear. First, the relevant context for determining how a phoneme is pronounced can be before as well as after the phoneme in question. Second, the sort of general knowledge about how phonemes are pronounced is specific to particular languages; it is general within the language, but it is not general enough to apply to all languages. We can see this by looking at the English phonemes /t/, /d/, and /ð/, and the Spanish phonemes /d/ and /r/. The English phoneme /t/ can be realized as [ɾ], but in Spanish, /t/ (dental, not alveolar as in English) and /r/ (pronounced as [ɾ]) are separate phonemes. Spanish /t/ is never voiced and never pronounced as a tap. The Spanish phoneme /d/ can be realized as [ɾ], but in English /d/ (alveolar, not dental as in Spanish) and /ɾ/ (always a dental fricative) are separate phonemes. English /d/ is never pronounced as a fricative or approximant.
However, as we will see in the next section, the rules that specify how phonemes in a given language are to be produced or perceived in different contexts are not completely arbitrary. There are good reasons for all of the rules, and, although almost none of them are universal, we can expect many of them to turn up in multiple languages.