
4.2: Assimilation
- Last updated
- Save as PDF
- Page ID
- 7018

Anticipatory Assimilation
Exercise \(\PageIndex{1}\)
The syllable un- means roughly 'not' in a word like unhappy, in which it is pronounced [ʌn]. Say the following words beginning with this syllable rapidly, and listen to how the nasal consonant in the syllable is pronounced: unbelievable, unpretentious, unkind, ungrateful. Assuming they did not sound like [n], what pattern do you notice in how the pronunciation of the nasal consonant depends on the following consonant?
Why would a phoneme have multiple realizations (allophones) in different contexts? Let's start with a simple example, the realization of /t/ as a dental, rather than an alveolar, stop, that is, as [t̪]. We saw this happening when /t/ comes before a dental fricative, for example, the first /t/ in at the top. Compare your pronunciation of this phrase with what it would be like if you pronounced the /t/ as an alveolar stop. (I'm assuming the alveolar prounciation is the prototypical articulation for /t/ because it's the most common place of articulation for this consonant.) You would have to slide your tongue forward from the alveolar ridge to the upper teeth as you go from the /t/ to the dental fricative /ð/ in the. It is simply easier to put the tongue behind the teeth for both the stop and the fricative.
This is illustrated in the figure below. The lines labeled "tongue tip contact" and "voicing" represent the relative timing of the articulatory actions that are required for the production of the sequence /æ/, /t/, /ð/ at the beginning of the phrase at the top. The two lines at the top illustrate the positions of the tongue for the two possible ways of pronouncing the sequence. The top line shows the movements for the normal pronunciation with a dental stop, [t̪]. The second line shows the movements that would be necessary if the /t/ were alveolar instead. There is an extra movement of the tongue tip to the alveolar ridge before it moves to the front teeth. That is, pronouncing the /t/ this way involves more movements.
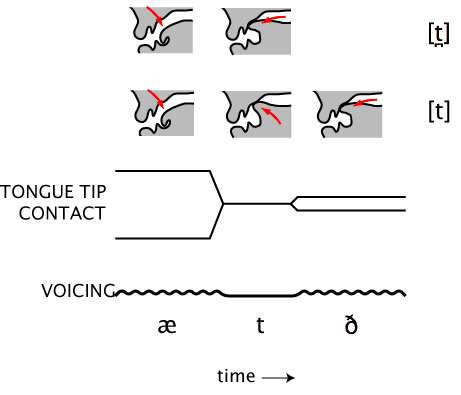
If the first stop in at the top is really an example of the phoneme /t/, we need an account for why this stop isn't produced in the prototypical way in this word. In this case the speaker anticipates the place of articulation (dental) of the following fricative. For English /t/ this appears to be quite general. That is, if we examine a lot of English words, looking for voiceless alveolar stops, we'll see that, in unaffected speech anyway, they don't occur right before dental fricatives. Instead they're replaced in that context by voiceless dental stops. The generalization holds not only for cases where the fricative following the /t/ comes in a separate word, as in at the top, but also when both phones are in the same word. One example is in the word eighth. Note that in this case the /t/ is not reflected in the spelling, but it is there, at least in my accent. Another example is the /t/ in width (spelled "d").
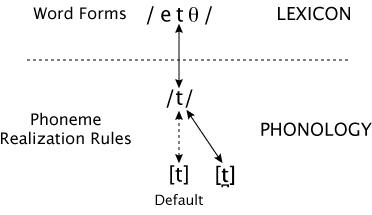
How do we represent words like eighth and width in the lexicon? The stops in these words are a little different from the stop in at because they are always pronounced as dental stops (in natural speech anyway). But it's easy to see why this is so: they are always followed by a dental fricative. So, just as with at, we will represent these words in the lexicon using /t/, and a realization rule in the phonological component will specify that the /t/ is realized as a dental rather than an alveolar stop. So the phonemic representation of eighth (in my accent) is /etθ/, and a more detailed phonetic representation showing the place of articulation of the /t/ (and the diphthongization of the /e/) would be [eɪt̪θ]. Likewise, the phonemic representation of width (in my accent) is /wɪtθ/, and the detailed phonetic representation is [wɪt̪θ].
This is illustrated in the figure below. The prototypical pronunciation of /t/ is shown in bold and designated the "default", that is, the allophone that is used unless there is some reason to use another allophone. The arrow connecting the phoneme to the default allophone is dashed in the figure to indicate that it isn't the one used for this word.
But what we see with /t/ is even more general in English. Consider the /n/ in on the top and the /d/ in hide the money. In both cases, the natural articulation is dental, rather than alveolar. If we take the prototypical articulation of /t/, /d/, and /n/ to be alveolar, we can see what is going on here as a change or process: the prototypical articulation is modified when the phoneme is realized in a particular context. So the realization rules for English can include the general rule:
- Alveolar stops and nasals become dental when they precede a dental fricative.
The figure below illustrates the rule for /t/ only. The label on the arrow connecting the phoneme to its dental allophone means that that allophone is appropriate when the phoneme occurs before a dental consonant. The "_" represents the position of the phoneme, that is, directly before the dental consonant.
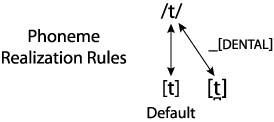
Assimilation Applying to One Phoneme Often Generalizes to Other, Similar Phonemes
This rule makes sense because it makes articulation easier; one phone, the alveolar stop or nasal, agrees with another, the dental fricative. A process in which one phone comes to agree with one or more others in its context is called assimilation. Assimilation is a Speaker-oriented process because it makes articulation easier. But notice that the change from an alveolar to a dental consonant should not interfere seriously with comprehension because the resulting sounds are quite similar to the original ones and because English has no dental stop or dental nasal phonemes that could be confused with the sounds that result. In simplifying things for the Speaker, a Speaker-oriented process should not make things too difficult for the Hearer.
Let's look at an example with vowels. Listen carefully to the vowels in the following words as you produce them: tad, tan; sag, sang; jab, jam.
The vowels in the first word in each pair are probably not quite the same as those in the second word in each pair. The vowels in tan, sang, and jam are normallynasalized; that is, the velum is lowered during the production of these vowels, allowing air to pass through the nasal cavity as well as the oral cavity. But this makes sense because it is what will be required for the following nasal consonant (/n/, /ŋ/, /m/) in each case. The speaker anticipates the nasal articulation of the consonant during the production of the vowel. It is of course possible to keep the velum up during the vowel and then simultaneously make the oral closure and lower the velum for the consonant, but it is apparently easier to get the velum lowering out of the way during the relatively long vowel production. This avoids the need to perfectly coordinate the lowering of the velum with the contact in the oral cavity (bilabial for /m/, alveolar for /n/, velar for /ŋ/).
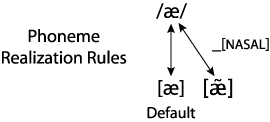
Note that the nasalization of the vowel in tan, sang, and jam is completely predictable from the vowel's context, specifically, the following nasal consonant. This means that there is no need to record the vowel's nasalization in the lexicon; this is a general property of the phoneme /æ/. So jam is /jæm/ in the lexicon, and a realization rule specifies that the /æ/ should be nasal because a nasal consonant follows.
This rule is illustrated in the figure below. [~] above the vowel symbol is used to indicate nasalization. As before there is a label on one of the realization arrows indicating the context for the rule, in this case, before a nasal consonant.
Not surprisingly the same holds in English for other vowels, though how much the velum is lowered depends on the particular vowel. We can include something like the following in the phonological component for English:
- Vowels tend to be nasalized when they precede nasal consonants.
We can illustrate this more general rule as in the figure below. Here "V" means any English vowel.
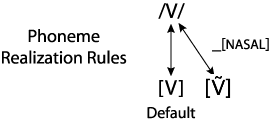
This means that all English vowels have a nasalized (at least to some degree) allophone, which occurs when the vowels precede a nasal consonant. As before, this Speaker-oriented process should not interfere too seriously with comprehension; Hearers should have no difficulty recognizing the phonemes for the nasalized vowels.
Perseverative Assimilation
Exercise \(\PageIndex{2}\)
One rapid, informal pronunciation of the word something is ['sʌmʔm̩]. (Recall that [m̩] indicates a syllabic nasal). Why do you think the final nasal, [ŋ] in the careful pronunciation in many accents, has become [m]?
Each Language Has its Own Assimilation Rules
In the examples we've seen so far, the assimilation is anticipatory; a phoneme changes its pronunciation in order to agree with a following phone on some dimension. Assimilation can work in the other direction as well. Let's look at Spanish /d/ again. Recall that this has an approximant allophone, [ð], when it follows any phone other than /n/ or /l/. For Spanish the only other possible previous phones are the others that can end a syllable: vowels, semivowels (/w/, /y/), /r/, /s/, or another /d/ (realized as the approximant). None of these is a stop; that is, there is no complete and sustained closure of the oral cavity (for /r/, a tap, there is a rapid closure followed by a release). Following any of these phones, pronouncing the /d/ as a stop would interrupt the open oral cavity. The approximant [ð] preserves this opening, and in this sense it is an example of assimilation: the consonant takes on one of the features of the previous phone (in the case of /r/ it is the open state of the oral cavity following the tap itself ). In this case the assimilation is perseverative; a feature of one phone "perseveres" during a following phone.
The figure below illustrates this Spanish rule, though just for the case where /d/ follows a vowel. In this case, the "_" symbol follows the relevant context ("vowel") because it is what precedes /d/ that determines which allophone to use.
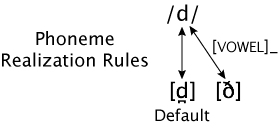
But why wouldn't this happen when the /d/ follows /n/ or /l/? Note that both of these Spanish consonants do involve contact of the tip of the tongue with the teeth, precisely the place where the stop [d̪] has its contact. Thus in these cases pronouncing the /d/ as the approximant would involve releasing the contact that has already been made for the previous consonant. So it makes some sense that /d/ does not change its manner of articulation in these contexts.
As with the English assimilation of alveolar to dental place of articulation, this process in Spanish applies more generally than to just /d/. Let's look at what happens to words beginning with voiced bilabial stops and voiced velar stops. I'll use the symbols [β] and [γ] to represent voiced bilabial and velar approximants.
- blanco, caballo blanco
- gordo, caballo gordo
In these examples, [b] occurs when the phone appears at the beginning of a word following a pause, and [β] occurs when the phone follows a vowel. Similarly, for [g] and [γ], the stop occurs following a pause and the approximant occurs following a vowel. This is exactly what we saw with /d/, so it appears that Spanish also has /b/ and /g/ phonemes, each with (at least) two allophones and that a general rule applies to change the default stop manner of articulation to approximant manner of articulation when the phoneme follows a vowel.
However, unlike for /d/, /b/ and /g/ also become approximants following /l/, as in these examples:
- el blanco
- el gordo
Why would /d/ remain a stop following /l/ while /b/ and /g/ become approximants? Recall that the behavior or /d/ following /l/ made sense because the tongue makes contact with the teeth for /l/ as it does for the dental stop [d̪]. But the articulator for [b] is the lips and for [g] the back of the tongue (making contact with the velar region of the roof of the mouth). Since neither of these gaps is closed during the production of /l/, leaving them open for a following /b/ or /g/ would represent the same sort of perseverative assimilation we see when these consonants follow vowels.
That leaves the situation with /b/ and /g/ following nasal consonants, which is a bit more complicated and more interesting. I will leave it for one of the problems for this section.
Let's look at one more English example, another of the allophones of English /t/, which illustrates both perseverative and anticipatory assimilation. But before we consider /t/, let's look at one of the allophones of English /d/. Listen to what happens to the [d] in do when it is preceded by a vowel and not stressed.
- How do we go?
- Who do you like?
- Why do I think that?
When do is pronounced in isolation, it starts with a stop, but when it follows a vowel and is not stressed, the [d] becomes a tap. The difference is not very great since there is still a contact at the alveolar ridge (as well as voicing), but the contact in the case of the tap is made by a quick gesture of the tongue tip and the contact is very brief. If we look at a lot of English words, we see that this is generally true for North American English /d/. For example, /d/ is pronounced like a tap in words like rider,muddy, and needed. The realization rule is something like the following:
- When /d/ begins an unstressed syllable, follows a vowel, and precedes a vowel (including /ər/ but excluding [n̩] and [l̩], that is, the variants of /ən/ and /əl/ without the vowel), it is realized as a tap ([ɾ]).
Why might this be? Though we probably cannot call it assimilation because the oral cavity is open before and after the consonant and closed as the consonant is produced, this does appear to be a Speaker-oriented process. To pronounce the /d/ like a stop, the tongue tip must make contact with the alveolar ridge and remain there for some time. For the tap articulation, it must only make brief contact with the alveolar ridge. Thus in general the tap appears to be easier to execute in this environment.
Both English and Spanish Have Examples of Consonants Becoming More Vowel-like Following Vowels
Now let's consider /t/ in the same context. We already saw in the section on contexts that /t/ may also be realized as a voiced tap. We saw this with the word at, but we can also see it in the middle of words such as butter, city, and Italy. If the default (prototypical) pronunciation of /t/ is as a voiceless stop, there are two changes here: the /t/ becomes a tap and it becomes voiced as well. We have just seen (for /d/) how pronouncing a stop as a tap when it comes between two vowels may simplify articulation for the speaker. The voicing of the /t/ is an example of assimilation. Both the phone before and the phone after the /t/ in these words are voiced, so allowing the voicing to continue through the articulation of the /t/ simplifies matters somewhat for the speaker. Because the assimilation points in both directions, it is both perseverative and anticipatory. The figure below illustrates this process. It shows the third allophone of /t/ that we have seen, [R], and an indication of the context where it is used. The "_" appears between two vowels ("V"), the second of which is unstressed.
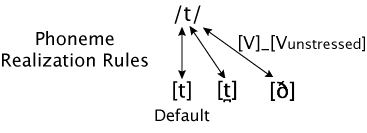
While assimilation makes good sense from the perspective of the Speaker, we can't use it in general to predict how phonemes in different languages will behave. First, particular assimilation rules that operate in one language or dialect may not operate in another. For example, English does not have a rule like the Spanish rule that causes voiced stops to become approximants (although something like this may happen in English in very rapid, casual speech), and in most English accents /t/ is not voiced when it comes between vowels as it is in North American accents. In other words, there is an arbitrary aspect to assimilation; which kinds of assimilation apply to a particular language and dialect must be learned. Second, some of the allophonic variation that is exhibited by phonemes seems to have nothing to do with assimilation. We will see examples of this type next.
Non-assimilative Allophonic Variation
Let's go back once more to the most complicated consonant in English, /t/. Compare the /t/ in till with the /t/ in still. As described when we discussed consonant voicing and voice onset time, the /t/ in till is aspirated. That is, there is a significant lag between the release of the contact and the beginning of voicing, and you can feel a puff of air being expelled during this lag. To show this detailed pronunciation, we can write [th]. But note that this is not the way the /t/ in still is pronounced. For this sound the release and the beginning of voicing roughly coincide.
But why not treat these two kinds of t-sounds as two different phonemes? Recall once again that different phonemes are used to distinguish words from one another. Can these two kinds of English t-sounds distinguish words from each other? If we could have the aspirated t ([th]) in a word like still, then we could have one word pronounced [stɪl] (with unaspirated t) and another word pronounced [sthɪl] (with aspirated t). But the aspirated sound never appears in this position, and if it did (and this is important), English hearers would still hear the word as still. The same would be true if we used the unaspirated sound in the word till. English hearers would still hear the word as till, or perhaps as dill, but not as some other word with neither /t/ nor /d/ at the beginning.
So it seems that the distinction between [t] and [th] cannot be used in English to distinguish one word from another. Since these two sounds are very similar to each other and they cannot be used to distinguish words from each other, we conclude that they belong to the same phoneme, that they are both allophones of /t/. But notice that the realization of /t/ as (unaspirated) [t] or (aspirated) [th] is a regular phenomenon, something that English speakers know how to do. This means that we need realization rules in the phonological component telling when [t] is appropriate and when [th] is appropriate. Here's a stab at what they would look like.
- When /t/ appears at the beginning of a stressed syllable, it is aspirated. (The details of its pronunciation depend on what follows it.)
- Otherwise /t/ is unaspirated. (The details of its pronunciation depend on what precedes and what follows it.)
But we can be even more general than this. Consider the words pot and spot. The /p/ sounds in the words show exactly the same alternatives as the /t/ sounds in till and still. And the same is true for the /k/ sounds in the words car and scar. If we examine a lot of words containing /p/ and /k/, we see that the alternation is just as general as it is for /t/. So the realization rule can apply to all three phonemes:
- When a voiceless stop appears at the beginning of a stressed syllable, it is aspirated.
- Otherwise a voiceless stop is unaspirated.
Speakers of a Language Know How and When to Produce the Allophones of a Phoneme, But They May Not be Aware of Any of the Differences
It is usually not surprising for English speakers to learn that the [th] in till and the [t] in still belong to the same category. In fact they probably were not even aware that there were these two different sounds, and some English speakers cannot hear the difference even after it is described to them. The difference between these two allophones of /t/ in one sense doesn't matter for English in the way that the difference between /t/ and /d/ does matter. English hearers do not have to identify a sound as being [t] or [th] because what they care about is what words they are hearing, and the difference between these two sounds never matters for the words. However, they do have to identify a sound as being /t/ or /d/ because it can make a difference, say, between till and dill or between bat and bad. Learning English apparently includes learning to emphasize the differences between sounds such as [t] and [d] and de-emphasize the differences between sounds such as [t] and [th].
But why would these English stops behave this way? These are not examples of assimilation: the /t/ in stop cannot be said to agree with the /s/ that precedes it or the /ɑ/ that follows it any more than it would if it were aspirated. If we view the unaspirated stops as the default (prototypical) allophone, then why would these stops get aspirated when they come at the beginning of stressed syllables? The origin of this process is probably more Hearer-oriented than Speaker-oriented. For the Hearer, what matters is that /t/ sounds different enough from nearby phonemes, namely, /d/ and /θ/. In terms of voice-onset time, [th] is further from [d] than [t] is, especially at the beginning of a syllable. The gap between the release and voicing is longer, and there is the (possibly audible) puff of breath. Since aspiration requires more breath, it is easier to achieve in stressed syllables, which are executed with a greater effort. Thus English has settled on a set of realization rules for voiceless stops that maximize the distinctions between voiced and voiceless stops at the beginning of stressed syllables.
Note, however, that in some other contexts, the distinction between voiced and voiceless stops disappears altogether in English. Following an /s/ in the same syllable, only voiceless stops are possible; that is, there are no words like /sdɪl/ or /sbɪn/. And in North American English, the distinction between /t/ and /d/ disappears at the beginning of an unstressed syllable between vowels; both are realized as the voiced tap [ɾ], as we have seen. (Most speakers, however, make a distinction between the vowels preceding these consonants, so writer and rider do not sound quite the same for these speakers.)
As with the examples of assimilation that we discussed, we've seen aspiration of voiceless stops in English makes some sense, at least from the perspective of the Hearer. But it is still a convention of English, something that we should not necessarily expect in other languages. In Spanish, voiceless stops are never aspirated; in Amharic, they are weakly aspirated in all contexts. In Mandarin Chinese, the relevant distinction is between voiceless stops that are always aspirated and voiceless stops that are never aspirated; that is, there are no real voiced stops. And in Hindi, there is a three-way distinction, between stops that are voiced, stops that are voiceless and always unaspirated, and stops that are voiceless and always aspirated. Finally, even when voiceless stops are aspirated in some contexts but not in others in a language, the pattern may be different from in English. In Tzeltal, voiceless stops are aspirated at the ends of syllables, but not at the beginnings.