
2.1: The linguistic corpus
- Last updated
- Save as PDF
- Page ID
- 81905

Although corpus-based studies of language structure can look back on a tradition of at least a hundred years, there is no general agreement as to what exactly constitutes corpus linguistics. This is due in part to the fact that the hundred-year tradition is not an unbroken one. As we saw in the preceding chapter, corpora fell out of favor just as linguistics grew into an academic discipline in its own right and as a result, corpus-based studies of language were relegated to the margins of the field. While the work on corpora and corpus-linguistic methods never ceased, it has returned to a more central place in linguistic methodology only relatively recently. It should therefore come as no surprise that it has not, so far, consolidated into a homogeneous methodological framework. More generally, linguistics itself, with a tradition that reaches back to antiquity, has remained notoriously heterogeneous discipline with little agreement among researchers even with respect to fundamental questions such as what aspects of language constitute their object of study (recall the brief remarks at the beginning of the preceding chapter). It is not surprising, then, that they do not agree how their object of study should be approached methodologically and how it might be modeled theoretically. Given this lack of agreement, it is highly unlikely that a unified methodology will emerge in the field any time soon.
On the one hand, this heterogeneity is a good thing. The dogmatism that comes with monolithic theoretical and methodological frameworks can be stifling to the curiosity that drives scientific progress, especially in the humanities and social sciences which are, by and large, less mature descriptively and theoretically than the natural sciences. On the other hand, after more than a century of scientific inquiry in the modern sense, there should no longer be any serious disagreement as to its fundamental procedures, and there is no reason not to apply these procedures within the language sciences. Thus, I will attempt in this chapter to sketch out a broad, and, I believe, ultimately uncontroversial characterization of corpus linguistics as an instance of the scientific method. I will develop this proposal by successively considering and dismissing alternative characterizations of corpus linguistics. My aim in doing so is not to delegitimize these alternative characterizations, but to point out ways in which they are incomplete unless they are embedded in a principled set of ideas as to what it means to study language scientifically.
Let us begin by considering a characterization of corpus linguistics from a classic textbook:
Corpus linguistics is perhaps best described for the moment in simple terms as the study of language based on examples of “real life” language use. (McEnery & Wilson 2001: 1).
This definition is uncontroversial in that any research method that does not fall under it would not be regarded as corpus linguistics. However, it is also very broad, covering many methodological approaches that would not be described as corpus linguistics even by their own practitioners (such as discourse analysis or citation-based lexicography). Some otherwise similar definitions of corpus linguistics attempt to be more specific in that they define corpus linguistics as “the compilation and analysis of corpora.” (Cheng 2012: 6, cf. also Meyer 2002: xi), suggesting that there is a particular form of recording “real-life language use” called a corpus.
The first chapter of this book started with a similar definition, characterizing corpus linguistics as “as any form of linguistic inquiry based on data derived from [...] a corpus”, where corpus was defined as “a large collection of authentic text”. In order to distinguish corpus linguistics proper from other observational methods in linguistics, we must first refine this definition of a linguistic corpus; this will be our concern in Section 2.1. We must then take a closer look at what it means to study language on the basis of a corpus; this will be our concern in Section 2.2.
2.1 The linguistic corpus
The term corpus has slightly different meanings in different academic disciplines. It generally refers to a collection of texts; in literature studies, this collection may consist of the works of a particular author (e.g. all plays by William Shakespeare) or a particular genre and period (e.g. all 18th century novels); in theology, it may be (a particular translation of) the Bible. In field linguistics, it refers to any collection of data (whether narrative texts or individual sentences) elicited for the purpose of linguistic research, frequently with a particular research question in mind (cf. Sebba & Fligelstone 1994: 769).
In corpus linguistics, the term is used differently – it refers to a collection of samples of language use with the following properties:
- the instances of language use contained in it are authentic;
- the collection is representative of the language or language variety under investigation;
- the collection is large.
In addition, the texts in such a collection are often (but not always) annotated in order to enhance their potential for linguistic analysis. In particular, they may contain information about paralinguistic aspects of the original data (intonation, font style, etc.), linguistic properties of the utterances (parts of speech, syntactic structure), and demographic information about the speakers/writers.
To distinguish this type of collection from other collections of texts, we will refer to it as a linguistic corpus, and the term corpus will always refer to a linguistic corpus in this book unless specified otherwise.
Let us now discuss each of these criteria in turn, beginning with authenticity.
2.1.1 Authenticity
The word authenticity has a range of meanings that could be applied to language – it can mean that a speaker or writer speaks true to their character (He has found his authentic voice), or to the character of the group they belong to (She is the authentic voice of her generation), that a particular piece of language is correctly attributed (This is not an authentic Lincoln quote), or that speech is direct and truthful (the authentic language of ordinary people).
In the context of corpus linguistics (and often of linguistics in general), authenticity refers much more broadly to what McEnery & Wilson (2001) call “real life language use”. As Sinclair puts it, an authentic corpus is one in which
[a]ll the material is gathered from the genuine communications of people going about their normal business. Anything which involves the linguist beyond the minimum disruption required to acquire the data is reason for declaring a special corpus. (Sinclair 1996a)
In other words, authentic language is language produced for the purpose of communication, not for linguistic analysis or even with the knowledge that it might be used for such a purpose. It is language that is not, as it were, performed for the linguist based on what speakers believe constitutes “good” or “proper” language. This is a very broad view of authenticity, since people may be performing inauthentic language for reasons other than the presence of a linguist – but such performances are regarded by linguists as something people will do naturally from time to time and that can and must be studied as an aspect of language use. In contrast, performances for the linguist are assumed to distort language behavior in ways that makes them unsuitable for linguistic analysis.
In the case of written language, the criterion of authenticity is easy to satisfy. Writing samples can be collected after the fact, so that there is no way for the speakers to know that their language will come under scientific observation. In the case of spoken language, the “minimum disruption” that Sinclair mentions becomes relevant. We will return to this issue and its consequences for authenticity presently, but first let us discuss some general problems with the corpus linguist’s broad notion of authenticity.
Widdowson (2000), in the context of discussing the use of corpora in the language classroom, casts doubt on the notion of authenticity for what seems, at first, to be a rather philosophical reason:
The texts which are collected in a corpus have a reflected reality: they are only real because of the presupposed reality of the discourses of which they are a trace. This is decontexualized language, which is why it is only partially real. If the language is to be realized as use, it has to be recontextualized. (Widdowson 2000: 7)
In some sense, it is obvious that the texts in a corpus (in fact, all texts) are only fully authentic as long as they are part of an authentic communicative situation. A sample of spoken language is only authentic as part of the larger conversation it is part of, a sample of newspaper language is only authentic as long as it is produced in a newsroom and processed by a reader in the natural context of a newspaper or news site for the purposes of informing themselves about the news, and so on. Thus, the very act of taking a sample of language and including it in a corpus removes its authenticity.
This rather abstract point has very practical consequences, however. First, any text, spoken or written, will lose not only its communicative context (the discourse of which it was originally a part), but also some of its linguistic and paralinguistic properties when it becomes part of a corpus. This is most obvious in the case of transcribed spoken data, where the very act of transcription means that aspects like tone of voice, intonation, subtle aspects of pronunciation, facial expressions, gestures, etc. are replaced by simplified descriptions or omitted altogether. It is also true for written texts, where, for example, visual information about the font, its color and size, the position of the text on the page, and the tactile properties of the paper are removed or replaced by descriptions (see further Section 2.1.4 below).
The corpus linguist can attempt to supply the missing information introspectively, “recontextualizing” the text, as Widdowson puts it. But since they are not in an authentic setting (and often not a member of the same cultural and demographic group as the original or originally intended hearer/reader), this recontextualization can approximate authenticity at best.
Second, texts, whether written or spoken, may contain errors that were present in the original production or that were introduced by editing before publication or by the process of preparing them for inclusion in the corpus (cf. also Emons 1997). As long as the errors are present in the language sample before it is included in the corpus, they are not, in themselves, problematic: errors are part of language use and must be studied as such (in fact, the study of errors has yielded crucial insights into language processing, cf., for example, Fromkin 1973 and Fromkin 1980). The problem is that the decision as to whether some bit of language contains an error is one that the researcher must make by reconceptualizing the speaker and their intentions in the original context, a reconceptualization that makes authenticity impossible to determine.
This does not mean that corpora cannot be used. It simply means that limits of authenticity have to be kept in mind. With respect to spoken language, however, there is a more serious problem – Sinclair’s “minimum disruption”.
The problem is that in observational studies no disruption is ever minimal – as soon as the investigator is present in person or in the minds of the observed, we get what is known as the “observer’s paradox”: we want to observe people (or other animate beings) behaving as they would if they were not observed – in the case of gathering spoken language data, we want to observe speakers interacting linguistically as they would if no linguist was in sight.
In some areas of study, it is possible to circumvent this problem by hiding (or installing hidden recording devices), but in the case of human language users this is impossible: it is unethical as well as illegal in most jurisdictions to record people without their knowledge. Speakers must typically give written consent before the data collection can begin, and there is usually a recording device in plain view that will constantly remind them that they are being recorded.
This knowledge will invariably introduce a degree of inauthenticity into the data. Take the following excerpts from the Bergen Corpus of London Teenage Language (COLT). In the excerpt in (1), the speakers are talking about the recording device itself, something they would not do in other circumstances:
(1) A: Josie?
B: Yeah. [laughs] I’m not filming you, I’m just taping you. [...]
A: Yeah, I’ll take your little toy and smash it to pieces!
C: Mm. Take these back to your class. [COLT B132611]
In the excerpt in (2), speaker A explains to their interlocutor the fact that the conversation they are having will be used for linguistic research:
(2) A: Were you here when I got that?
B: No what is it?
A: It’s for the erm, [...] language course. Language, survey. [...]
B: Who gave it to you?
A: Erm this lady from the, University of Bergen.
B: So how d’ya how does it work?
A: Erm you you speak into it and erm, records, gotta record conversations between people. [COLT B141708]
A speaker’s knowledge that they are being recorded for the purposes of linguistic analysis is bound to distort the data even further. In example (3), there is evidence for such a distortion – the speakers are performing explicitly for the recording device:
(3) C: Ooh look, there’s Nick!
A: Is there any music on that?
B: A few things I taped off the radio.
A: Alright then. Right. I wa..., I just want true things. He told me he dumped you is that true?
C: [laughs]
B: No it is not true. I protest. [COLT B132611]
Speaker A asks for “true things” and then imitates an interview situation, which speaker B takes up by using the somewhat formal phrase I protest, which they presumably would not use in an authentic conversation about their love life.
Obviously, such distortions will be more or less problematic depending on our research question. Level of formality (style) may be easier to manipulate in performing for the linguist than pronunciation, which is easier to manipulate than morphological or syntactic behavior. However, the fact remains that spoken data in corpora are hardly ever authentic in the corpus-linguistic sense (unless it is based on recordings of public language use, for example, from television or the radio), and the researcher must rely, again, on an attempt to recontextualize the data based on their own experience as a language user in order to identify possible distortions. There is no objective way of judging the degree of distortion introduced by the presence of an observer, since we do not have a sufficiently broad range of surreptitiously recorded data for comparison.
There is one famous exception to the observer’s paradox in spoken language data: the so-called Nixon Tapes – illegal surreptitious recordings of conversation in the executive offices of the White House and the headquarters of the opposing Democratic Party produced at the request of the Republican President Richard Nixon between February 1971 and July 1973. Many of these tapes are now available as digitized sound files and/or transcripts (see, for example, Nichter 2007). In addition to the interest they hold for historians, they form the largest available corpus of truly authentic spoken language.
However, even these recordings are too limited in size and topic area as well as in the diversity of speakers recorded (mainly older white American males), to serve as a standard against which to compare other collections of spoken data.
The ethical and legal problems in recording unobserved spoken language cannot be circumvented, but their impact on the authenticity of the recorded language can be lessened in various ways – for example, by getting general consent from speakers, but not telling them when precisely they will be recorded.
Researchers may sometimes deliberately choose to depart from authenticity in the corpus-linguistic sense if their research design or the phenomenon under investigation requires it. A researcher may be interested in a phenomenon that is so rare in most situations that even the largest available corpora do not contain a sufficient number of cases. These may be structural phenomena (like the pattern [It doesn’t matter the N] or transitive croak, discussed in the previous chapter), or unusual communicative situations (for example, human-machine interaction).
In such cases, it may be necessary to switch methods and use some kind of grammaticality judgments after all, but it may also be possible to elicit these phenomena in what we could call semi-authentic settings. For example, researchers interested in motion verbs often do not have the means (or the patience) to collect these verbs from general corpora, or corpora may not contain a sufficiently broad range of descriptions of motion events with particular properties. Such descriptions are sometimes elicited by asking speakers to describe movie snippets or narrate a story from a picture book (cf. e.g. Berman & Slobin 1994; Strömqvist & Verhoeven 2003). Human-machine interaction is sometimes elicited in so-called “Wizard of Oz” experiments, where people believe they are talking to a robot, but the robot is actually controlled by one of the researchers (cf. e.g. Georgila et al. 2010).
Such semi-structured elicitation techniques may also be used where a phenomenon is frequent enough in a typical corpus, but where the researcher wants to vary certain aspects systematically, or where the researcher wants to achieve comparability across speakers or even across languages.
These are sometimes good reasons for eliciting a special-purpose corpus rather than collecting naturally occurring text. Still, the stimulus-response design of elicitation is obviously influenced by experimental paradigms used in psychology. Thus, studies based on such corpora must be regarded as falling somewhere between corpus linguistics and psycholinguistics and they must therefore meet the design criteria of both corpus linguistic and psycholinguistic research designs.
2.1.2 Representativeness
Put simply, a representative sample is a subset of a population that is identical to the population as a whole with respect to the distribution of the phenomenon under investigation. Thus, for a corpus (a sample of language use) to be representative of a particular language, the distribution of linguistic phenomena (words, grammatical structures, etc.) would have to be identical to their distribution in the language as a whole (or in the variety under investigation, see further below).
The way that corpus creators typically aim to achieve this is by including in the corpus different manifestations of the language it is meant to represent in proportions that reflect their incidence in the speech community in question. Such a corpus is sometimes referred to as a balanced corpus.
Before we can discuss this in more detail, a terminological note is in order. You may have noted that in the preceding discussion I have repeatedly used terms like language variety, genre, register and style for different manifestations of language. The precise usage of these terms notoriously vary across subdisciplines of linguistics and individual researchers, including the creators of corpora.
In this book, I use language variety to refer to any form of language delineable from other forms along cultural, linguistic or demographic criteria. In other words, I use it as a superordinate term for text-linguistic terms like genre, register, style, and medium as well as sociolinguistic terms like dialect, sociolect, etc. With respect to what I am calling text-linguistic terms here, I follow the usage suggestions synthesized by Lee (2001) and use genre for culturally defined and recognized varieties, register for varieties characterized by a particular “functional configuration” (roughly, a bundle of linguistic features associated with a particular social function), style to refer to the degrees of formality (e.g. formal, informal, colloquial, humorous, etc.), and medium to refer to the material manifestation (essentially, spoken and written with subtypes of these). I use the term topic (area) to refer to the content of texts or the discourse domain from which they come. When a particular variety, defined by one or more of the dimensions just mentioned, is included in a given corpus, I refer to it as a text category of that corpus.
For a corpus to be representative (or “balanced”), its text categories should accurately reflect both quantitatively and qualitatively the language varieties found in the speech community whose language is represented in the corpus. However, it is clear that this is an ideal that is impossible to achieve in reality for at least four reasons.
First, for most potentially relevant parameters we simply do not know how they are distributed in the population. We may know the distribution of some of the most important demographic variables (e.g. sex, age, education), but we simply do not know the overall distribution of spoken vs. written language, press language vs. literary language, texts and conversations about particular topics, etc.
Second, even if we did know, it is not clear that all manifestations of language use shape and/or represent the linguistic system in the same way, simply because we do not know how widely they are received. For example, emails may be responsible for a larger share of written language produced in a given time span than news sites, but each email is typically read by a handful of people at the most, while some news texts may be read by millions of people (and others not at all).
Third, in a related point, speech communities are not homogeneous, so defining balance based on the proportion of language varieties in the speech community may not yield a realistic representation of the language even if it were possible: every member of the speech community takes part in different communicative situations involving different language varieties. Some people read more than others, and among these some read mostly newspapers, others mostly novels; some people watch parliamentary debates on TV all day, others mainly talk to customers in the bakery where they work. In other words, the proportion of language varieties that speakers encounter varies, requiring a notion of balance based on the incidence of language varieties in the linguistic experience of a typical speaker. This, in turn, requires a definition of what constitutes a typical speaker in a given speech community. Such a definition may be possible, but to my knowledge, does not exist so far.
Finally, there are language varieties that are impossible to sample for practical reasons – for example, pillow talk (which speakers will be unwilling to share because they consider it too private), religious confessions or lawyer-client conversations (which speakers are prevented from sharing because they are privileged), and the planning of illegal activities (which speakers will want to keep secret in order to avoid lengthy prison terms).
Representativeness or balancedness also plays a role if we do not aim at investigating a language as a whole, but are instead interested in a particular variety. In this case, the corpus will be deliberately skewed so as to contain only samples of the variety under investigation. However, if we plan to generalize our results to that variety as a whole, the corpus must be representative of that variety. This is sometimes overlooked. For example, there are studies of political rhetoric that are based on speeches by just a handful of political leaders (cf., e.g., CharterisBlack 2006; 2005) or studies of romantic metaphor based on a single Shakespeare play (Barcelona Sánchez 1995). While such studies can be insightful with respect to the language of the individuals included in the corpus, their results are unlikely to be generalizable even within the narrow variety under investigation (political speeches, romantic tragedies). Thus, they belong to the field of literary criticism or stylistics much more clearly than to the field of linguistics.
Given the problems discussed above, it seems impossible to create a linguistic corpus meeting the criterion of representativeness. In fact, while there are very well-thought out approaches to approximating representativeness (cf., e.g., Biber 1993), it is fair to say that most corpus creators never really try. Let us see what they do instead.
The first linguistic corpus in our sense was the Brown University Standard Corpus of Present-Day American English (generally referred to as BROWN). It is made up exclusively of edited prose published in the year 1961, so it clearly does not attempt to be representative of American English in general, but only of a particular kind of written American English in a narrow time span. This is legitimate if the goal is to investigate that particular variety, but if the corpus were meant to represent the standard language in general (which the corpus creators explicitly deny), it would force us to accept a very narrow understanding of standard.
The BROWN corpus consists of 500 samples of approximately 2000 words each, drawn from a number of different language varieties, as shown in Table 2.1.

The first level of sampling is, roughly, by genre: there are 286 samples of nonfiction, 126 samples of fiction and 88 samples of press texts. There is no reason to believe that this corresponds proportionally to the total number of words produced in these language varieties in the USA in 1961. There is also no reason to believe that the distribution corresponds proportionally to the incidence of these language varieties in the linguistic experience of a typical speaker. This is true all the more so when we take into account the second level of sampling within these genres, which uses a mixture of sub-genres (such as reportage or editorial in the press category or novels and short stories in the fiction category), and topic areas (such as Romance, Natural Science or Sports). Clearly the number of samples included for these categories is not based on statistics of their proportion in the language as a whole. Intuitively, there may be a rough correlation in some cases: newspapers publish more reportage than editorials, people (or at least academics like those that built the corpus) generally read more mystery fiction than science fiction, etc. The creators of the BROWN corpus are quite open about the fact that their corpus design is not a representative sample of (written) American English. They describe the collection procedure as follows:
The selection procedure was in two phases: an initial subjective classification and decision as to how many samples of each category would be used, followed by a random selection of the actual samples within each category. In most categories the holding of the Brown University Library and the Providence Athenaeum were treated as the universe from which the random selections were made. But for certain categories it was necessary to go beyond these two collections. For the daily press, for example, the list of American newspapers of which the New York Public Library keeps microfilms files was used (with the addition of the Providence Journal). Certain categories of chiefly ephemeral material necessitated rather arbitrary decisions; some periodical materials in the categories Skills and Hobbies and Popular Lore were chosen from the contents of one of the largest second-hand magazine stores in New York City. (Francis & Kučera 1979)
If anything, the BROWN corpus is representative of the holdings of the libraries mentioned, although even this representativeness is limited in two ways. First, by the unsystematic additions mentioned in the quote, and second, by the sampling procedure applied.
Although this sampling procedure is explicitly acknowledged to be “subjective” by the creators of the BROWN corpus, their description suggests that their design was guided by a general desire for balance:
The list of main categories and their subdivisions was drawn up at a conference held at Brown University in February 1963. The participants in the conference also independently gave their opinions as to the number of samples there should be in each category. These figures were averaged to obtain the preliminary set of figures used. A few changes were later made on the basis of experience gained in making the selections. Finer subdivision was based on proportional amounts of actual publication during 1961. (Francis & Kučera 1979)
This procedure combines elements from both interpretations of representativeness discussed above. First, it involves the opinions (i.e., intuitions) of a number of people concerning the proportional relevance of certain sub-genres and/or topic areas. The fact that these opinions were “averaged” suggests that the corpus creators wanted to achieve a certain degree of intersubjectivity. This idea is not completely wrongheaded, although it is doubtful that speakers have reliable intuitions in this area. In addition, the participants of the conference mentioned did not exactly constitute a group of typical speakers or a cross-section of the American English speech community: they consisted of six academics with backgrounds in linguistics, education and psychology – five men and one woman; four Americans, one Brit and one Czech; all of them white and middle-aged (the youngest was 36, the oldest 59). No doubt, a different group of researchers – let alone a random sample of speakers – following the procedure described would arrive at a very different corpus design.
Second, the procedure involves an attempt to capture the proportion of language varieties in actual publication – this proportion was determined on the basis of the American Book Publishing Record, a reference work containing publication information on all books published in the USA in a given year. Whether this is, in fact, a comprehensive source is unclear, and anyway, it can only be used in the selection of excerpts from books. Basing the estimation of the proportion of language varieties on a different source would, again, have yielded a very different corpus design. For example, the copyright registrations for 1961 suggest that the category of periodicals is severely underrepresented relative to the category of books – there are roughly the same number of copyright registrations for the two language varieties, but there are one-and-a-half times as many excerpts from books as from periodicals in the BROWN corpus.
Despite these shortcomings, the BROWN corpus set standards, inspiring a host of corpora of different varieties of English using the same design – for example, the Lancaster-Oslo/Bergen Corpus (LOB) containing British English from 1961, the Freiburg Brown (FROWN) and Freiburg LOB (FLOB) corpora of American and British English respectively from 1991, the Wellington Corpus of Written New Zealand English, and the Kolhapur Corpus (Indian English). The success of the BROWN design was partly due to the fact that being able to study strictly comparable corpora of different varieties is useful regardless of their design. However, if the design had been widely felt to be completely off-target, researchers would not have used it as a basis for the substantial effort involved in corpus creation.
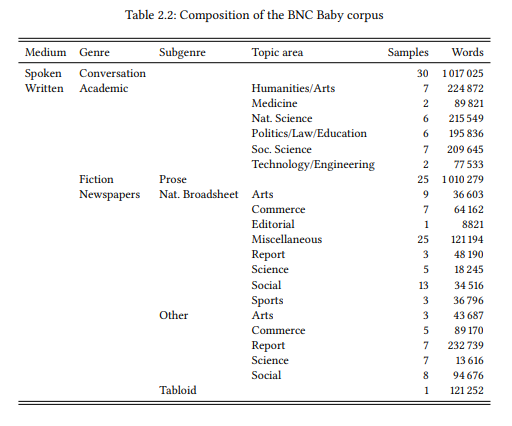
More recent corpora at first glance appear to take a more principled approach to representativeness or balance. Most importantly, they typically include not just written language, but also spoken language. However, a closer look reveals that this is the only real change. For example, the BNC Baby, a four-million-word subset of the 100-million-word British National Corpus (BNC), includes approximately one million words each from the text categories spoken conversation, written academic language, written prose fiction and written newspaper language (Table 2.2 shows the design in detail). Obviously, this design does not correspond to the linguistic experience of a typical speaker, who is unlikely to be exposed to academic writing and whose exposure to written language is unlikely to be three times as large as their exposure to spoken language. The design also does not correspond in any obvious way to the actual amount of language produced on average in the four categories or the subcategories of academic and newspaper language. Despite this, the BNC Baby, and the BNC itself, which is even more drastically skewed towards edited written language, are extremely successful corpora that are still widely used a quarter-century after the first release of the BNC.
Even what I would consider the most serious approach to date to creating a balanced corpus design, the sampling schema of the International Corpus of English (ICE), is unlikely to be substantially closer to constituting a representative sample of English language use (see Table 2.3).
It puts a stronger emphasis on spoken language – sixty percent of the corpus are spoken text categories, although two thirds of these are public language use, while for most of us private language use is likely to account for more of our linguistic experience. It also includes a much broader range of written text categories than previous corpora, including not just edited writing but also student writing and letters.
Linguists would probably agree that the design of the ICE corpora is “more representative” than that of the BNC Baby, which is in turn “more representative” than that of the BROWN corpus and its offspring. However, in light of the above discussion of representativeness, there is little reason to believe that any of these corpora, or the many others that fall somewhere between BROWN and ICE, even come close to approximating a random sample of (a given variety of) English in terms of the text categories they contain and the proportions with which they are represented.
This raises the question as to why corpus creators go to the trouble of attempting to create representative corpora at all, and why some corpora seem to be more successful attempts than others.
It seems to me that, in fact, corpus creators are not striving for representativeness at all. The impossibility of this task is widely acknowledged in corpus linguistics. Instead, they seem to interpret balance in terms of the related but distinct property diversity. While corpora will always be skewed relative to the overall population of texts and language varieties in a speech community, the undesirable effects of this skew can be alleviated by including in the corpus as broad a range of varieties as is realistic, either in general or in the context of a given research project.
Unless language structure and language use are infinitely variable (which, at a given point in time, they are clearly not), increasing the diversity of the sample will increase representativeness even if the corpus design is not strictly proportional to the incidence of text varieties or types of speakers found in the speech community. It is important to acknowledge that this does not mean that diversity and representativeness are the same thing, but given that representative corpora are practically (and perhaps theoretically) impossible to create, diversity is a workable and justifiable proxy.

2.1.3 Size
Like diversity, corpus size is also assumed, more or less explicitly, to contribute to representativeness (e.g. McEnery & Wilson 2001: 78; Biber 2006: 251). The extent of the relationship is difficult to assess. Obviously, sample size does correlate with representativeness to some extent: if our corpus were to contain the totality of all manifestations of a language (or variety of a language), it would necessarily be representative, and this representativeness would not drop to zero immediately if we were to decrease the sample size. However, it would drop rather rapidly – if we exclude one percent of the totality of all texts produced in a given language, entire language varieties may already be missing. For example, the Library of Congress holds around 38 million print materials, roughly half of them in English. A search for cooking in the main catalogue yields 7638 items that presumably include all cookbooks in the collection. This means that cookbooks make up no more than 0.04 percent of printed English (7638/19000000 = 0.000402). Thus, they could quickly be lost in their entirety when the sample size drops substantially below the size of the population as a whole. And when a genre (or a language variety in general) goes missing from our sample, at least some linguistic phenomena will disappear along with it – such as the expression [bring NPLIQUID [PP to the/a boil]], which, as discussed in Chapter 1, is exclusive to cookbooks.1
In the age of the World Wide Web, corpus size is practically limited only by technical considerations. For example, the English data in the Google N-Grams data base are derived from a trillion-word corpus (cf. Franz & Brants 2006). In quantitative terms, this represents many times the linguistic input that a single person would receive in their lifetime: an average reader can read between 200 and 250 words per minute, so it would take them between 7500 and 9500 years of non-stop reading to get through the entire corpus. However, even this corpus contains only a tiny fraction of written English, let alone of English as a whole. Even more crucially, in terms of language varieties, it is limited to a narrow section of published written English and does not capture the input of any actual speaker of English at all.
There are several projects gathering very large corpora on a broader range of web-accessible text. These corpora are certainly impressive in terms of their size, even though they typically contain mere billions rather than trillions of words. However, their size is the only argument in their favor, as their creators and their users must not only give up any pretense that they are dealing with a representative corpus, but must contend with a situation in which they have no idea what texts and language varieties the corpus contains and how much of it was produced by speakers of English (or by human beings rather than bots).
These corpora certainly have their uses, but they push the definition of a linguistic corpus in the sense discussed above to their limit. To what extent they are representative cannot be determined. On the one hand, corpus size correlates with representativeness only to the extent that we take corpus diversity into account. On the other hand, assuming (as we did above) that language structure and use are not infinitely variable, size will correlate with the representativeness of a corpus at least to some extent with respect to particular linguistic phenomena (especially frequent phenomena, such as general vocabulary, and/or highly productive processes such as derivational morphology and major grammatical structures).
There is no principled answer to the question “How large must a linguistic corpus be?”, except, perhaps, an honest “It is impossible to say” (Renouf 1987: 130). However, there are two practical answers. The more modest answer is that it must be large enough to contain a sample of instances of the phenomenon under investigation that is large enough for analysis (we will discuss what this means in Chapters 5 and 6). The less modest answer is that it must be large enough to contain sufficiently large samples of every grammatical structure, vocabulary item, etc. Given that an ever increasing number of texts from a broad range of language varieties is becoming accessible via the web, the second answer may not actually be as immodest as it sounds.
Current corpora that at least make an honest attempt at diversity currently range from one million (e.g. the ICE corpora mentioned above) to about half a billion (e.g. the COCA mentioned in the preceding chapter). Looking at the published corpus-linguistic literature, my impression is that for most linguistic phenomena that researchers are likely to want to investigate, these corpus sizes seem sufficient. Let us take this broad range as characterizing a linguistic corpus for practical purposes.
2.1.4 Annotations
Minimally, a linguistic corpus consists simply of a large, diverse collection of files containing authentic language samples as raw text, but more often than not, corpus creators add one or more of three broad types of annotation:
- information about paralinguistic features of the text such as font style, size and color, capitalization, special characters, etc. (for written texts), and intonation, overlapping speech, length of pauses, etc. (for spoken text);
- information about linguistic features, such as parts of speech, lemmas or grammatical structure;
- information about the producers of the text (speaker demographics like age, sex, education) or the circumstances of its production (genre, medium, situation)
In this section, we will illustrate these types of annotation and discuss their practical implications as well as their relation to the criterion of authenticity, beginning with paralinguistic features, whose omission was already hinted at as a problem for authenticity in Section 2.1.1 above.
For example, Figure 2.1 shows a passage of transcribed speech from the Santa Barbara Corpus of Spoken American English (SBCSAE).

Figure 2.1: Paralinguistic features of spoken language in the SBCSAE
The speech is transcribed more or less in standard orthography, with some paralinguistic features indicated by various means. For example, the beginning of a passage of “attenuated” (soft, low-volume) speech is indicated by the sequence . Audible breathing is transcribed as (H), lengthening is indicated by an equals sign (as in u=m in the seventh line) and pauses are represented as sequences of dots (two for a short pause, three for a long pause). Finally, overlapping speech, a typical feature of spoken language, is shown by square brackets, as in the third and fourth line. Other features of spoken language are not represented in detail in (this version of) the SBCSAE. Most notably, intonation is only indicated to the extent that each line represents one intonation unit (i.e. a stretch of speech with a single, coherent intonation contour), and that a period and a comma at the end of a line indicate a “terminative” and a “continuative” prosody respectively.
In contrast, consider the London-Lund Corpus of Spoken English (LLC), an excerpt from which is shown in Figure 2.2.

Figure 2.2: Paralinguistic features of spoken language in the LLC
Like the SBCAE, the LLC also indicates overlapping speech (enclosing it in plus signs as in lines 1430 and 1440 or in asterisks, as in lines 1520 and 1530), pauses (a period for a “brief” pause, single hyphen for a pause the length of one “stress unit” and two hyphens for longer pauses), and intonation units, called “tone units” by the corpus creators (with a caret marking the onset and the number sign marking the end).
In addition, however, intonation contours are recorded in detail preceding the vowel of the prosodically most prominent syllable using the equals sign and rightward and leftward slashes: = stands for “level tone”, / for “rise”, \ for “fall”, \/ for “(rise-)fall-rise” and /\ for “(fall-)rise-fall”. A colon indicates that the following syllable is higher than the preceding one, an exclamation mark indicates that it is very high. Occasionally, the LLC uses phonetic transcription to indicate an unexpected pronunciation or vocalizations that have no standard spelling (like the [@:] in line 1410 which stands for a long schwa).
The two corpora differ in their use of symbols to annotate certain features, for example:
- the LLC indicates overlap by asterisks and plus signs, the SBCSAE by square brackets, which, in turn, are used in the LLC to mark “subordinate tone units” or phonetic transcriptions;
- the LLC uses periods and hyphens to indicate pauses, the SBCSAE uses only periods, with hyphens used to indicate that an intonation unit is truncated;
- intonation units are enclosed by the symbols ^ and # in the LLC and by line breaks in the SBCSAE;
- lengthening is shown by an equals sign in the SBCSAE and by a colon following a vowel in the LLC.
Thus, even where the two corpora annotate the same features of speech in the transcriptions, they code these features differently.
Such differences are important to understand for anyone working with the these corpora, as they will influence the way in which we have to search the corpus (see further Section 4.1.1 below) – before working with a corpus, one should always read the full manual. More importantly, such differences reflect different, sometimes incompatible theories of what features of spoken language are relevant, and at what level of detail. The SBCSAE and the LLC cannot easily be combined into a larger corpus, since they mark prosodic features at very different levels of detail. The LLC gives detailed information about pitch and intonation contours absent from the SBCSAE; in contrast, the SBCSAE contains information about volume and audible breathing that is absent from the LLC.
Written language, too, has paralinguistic features that are potentially relevant to linguistic research. Consider the excerpt from the LOB corpus in Figure 2.3.

Figure 2.3: Paralinguistic features of written language in the LOB corpus
The word anything in line 100 was set in italics in the original text; this is indicated by the sequences *1, which stands for “begin italic” and *0, which stands for “begin lower case (roman)” and thus ends the stretch set in italics. The original text also contained typographic quotes, which are not contained in the ASCII encoding used for the corpus. Thus, the sequence *" in line 100 stands for “begin double quotes” and the sequence **" in line 101 stands for “end double quotes”. ASCII also does not contain the dash symbol, so the sequence *- indicates a dash. Finally, paragraph boundaries are indicated by a sequence of three blank spaces followed by the pipe symbol | (as in lines 96 and 99), and more complex text features like indentation are represented by descriptive tags, enclosed in square brackets preceded by two asterisks (as in line 98 and 102, which signal the beginning and end of an indented passage).
Additionally, the corpus contains markup pertaining not to the appearance of the text but to its linguistic properties. For example, the word Mme in line 94 is an abbreviation, indicated in the corpus by the sequence \0 preceding it. This may not seem to contribute important information in this particular case, but it is useful where abbreviations end in a period (as they often do), because it serves to disambiguate such periods from sentence-final ones. Sentence boundaries are also marked explicitly: each sentence begins with a caret symbol ^.
Other corpora (and other versions of the LOB corpus) contain more detailed linguistic markup. Most commonly, they contain information about the word class of each word, represented in the form of a so-called “part-of-speech (or POS) tags”. Figure 2.4 shows a passage from the BROWN corpus, where these POS tags take the form of sequences of uppercase letters and symbols, attached to the end of each word by an underscore (for example, _AT for articles, _NN for singular nouns, _* for the negative particle not, etc.). Note that sentence boundaries are also marked, in this case by a pipe symbol (used for paragraph boundaries in the LOB) followed by the sequence SN and an id number.

Figure 2.4: Structural features in the BROWN corpus
Other linguistic features that are sometimes recorded in (written and spoken) corpora are the lemmas of each word and (less often) the syntactic structure of the sentences (corpora with syntactic annotation are sometimes referred to as treebanks). When more than one variable is annotated in a corpus, the corpus is typically structured as shown in Figure 2.5, with one word per line and different columns for the different types of annotation (more recently, the markup language XML is used in addition to or instead of this format).
Annotations of paralinguistic or linguistic features in a corpus impact its authenticity in complex ways.
On the one hand, including information concerning paralinguistic features makes a corpus more authentic than it would be if this information was simply discarded. After all, this information represents aspects of the original speech events from which the corpus is derived and is necessary to ensure a reconceptualization of the data that approximates these events as closely as possible.

Figure 2.5: Example of a corpus with complex annotation (SUSANNE corpus)
On the other hand, this information is necessarily biased by the interests and theoretical perspectives of the corpus creators. By splitting the spoken corpora into intonation units, for example, the creators assume that there are such units and that they are a relevant category in the study of spoken language. They will also identify these units based on particular theoretical and methodological assumptions, which means that different creators will come to different decisions. The same is true of other aspects of spoken and written language. Researchers using these corpora are then forced to accept the assumptions and decisions of the corpus creators (or they must try to work around them).
This problem is even more obvious in the case of linguistic annotation. There may be disagreements as to how and at what level of detail intonation should be described, for example, but it is relatively uncontroversial that it consists of changes in pitch. In contrast, it is highly controversial how many parts of speech there are and how they should be identified, or how the structure even of simple sentences is best described and represented. Accepting (or working around) the corpus creators’ assumptions and decisions concerning POS tags and annotations of syntactic structure may seriously limit or distort researcher’s use of corpora.
Also, while it is clear that speakers are at some level aware of intonation, pauses, indentation, roman vs. italic fonts, etc., it is much less clear that they are aware of parts of speech and grammatical structures. Thus, the former play a legitimate role in reconceptualizing authentic speech situations, while the latter arguably do not. Note also that while linguistic markup is often a precondition for an efficient retrieval of data, error in markup may hide certain phenomena systematically (see further Chapter 4, especially Section 4.1.1).
Finally, corpora typically give some information about the texts they contain – so-called metadata. These may be recorded in a manual, a separate computerreadable document or directly in the corpus files to which they pertain. Typical metadata are language variety (in terms of genre, medium topic area, etc., as described in Section 2.1.2 above), the origin of the text (for example, speaker/writer, year of production and or publication), and demographic information about the speaker/writer (sex, age, social class, geographical origin, sometimes also level of education, profession, religious affiliation, etc.). Metadata may also pertain to the structure of the corpus itself, like the file names, line numbers and sentence or utterance ids in the examples cited above.
Metadata are also crucial in recontextualizing corpus data and in designing certain kinds of research projects, but they, too, depend on assumptions and choices made by corpus creators and should not be uncritically accepted by researchers using a given corpus.
1 The expression actually occurs once in the BROWN corpus, which includes one 2000 word sample from a cookbook, over-representing this genre by a factor of five, but not at all in the LOB corpus. Thus, someone investigating the LOB corpus might not include this expression in their description of English at all, someone comparing the two corpora would wrongly conclude that it is limited to American English.