
2.2: Towards a definition of corpus linguistics
- Last updated
- Save as PDF
- Page ID
- 81906

Having characterized the linguistic corpus in its ideal form, we can now reformulate the definition of corpus linguistics cited at the beginning of this chapter as follows:
Definition (First attempt)
Corpus linguistics is the investigation of linguistic phenomena on the basis of linguistic corpora.
This definition is more specific with respect to the data used in corpus linguistics and will exclude certain variants of discourse analysis, text linguistics, and other fields working with authentic language data (whether such a strict exclusion is a good thing is a question we will briefly return to at the end of this chapter).
However, the definition says nothing about the way in which these data are to be investigated. Crucially, it would cover a procedure in which the linguistic corpus essentially serves as a giant citation file, that the researcher scours, more or less systematically, for examples of a given linguistic phenomenon.
This procedure of basing linguistic analysis on citations has a long tradition in descriptive English linguistics, going back at least to Otto Jespersen’s seven-volume Modern English Grammar on Historical Principles (Jespersen 1909). It played a particularly important role in the context of dictionary making. The Oxford English Dictionary (Simpson & Weiner 1989) is the first and probably still the most famous example of a citation-based dictionary of English. For the first two editions, it relied on citations sent in by volunteers (cf. Winchester 2003 for a popular account). In its current third edition, its editors actively search corpora and other text collections (including the Google Books index) for citations.
A fairly stringent implementation of this method is described in the following passage from the FAQ web page of the Merriam-Webster Online Dictionary:
Each day most Merriam-Webster editors devote an hour or two to reading a cross section of published material, including books, newspapers, magazines, and electronic publications; in our office this activity is called “reading and marking.” The editors scour the texts in search of [...] anything that might help in deciding if a word belongs in the dictionary, understanding what it means, and determining typical usage. Any word of interest is marked, along with surrounding context that offers insight into its form and use. [...] The marked passages are then input into a computer system and stored both in machine-readable form and on 3″× 5″slips of paper to create citations. (Merriam-Webster 2014)
The “cross-section of published material” referred to in this passage is heavily skewed towards particular varieties of formal written language. Given that people will typically consult dictionaries to look up unfamiliar words they encounter in writing, this may be a reasonable choice to make, although it should be pointed out that modern dictionaries are often based on more diverse linguistic corpora.
But let us assume, for the moment, that the cross-section of published material read by the editors of Merriam Webster’s dictionary counts as a linguistic corpus. Given this assumption, the procedure described here clearly falls under our definition of corpus linguistics. Interestingly, the publishers of Merriam Webster’s even refer to their procedure as “study[ing] the language as it’s used” (Merriam-Webster 2014), a characterization that is very close to McEnery and Wilson’s definition of corpus linguistics as the “study of language based on examples of ‘real life’ language use”.
Collecting citations is perfectly legitimate. It may serve to show that a particular linguistic phenomenon existed at a particular point in time – one reason for basing the OED on citations was and is to identify the first recorded use of each word. It may also serve to show that a particular linguistic phenomenon exists at all, for example, if that phenomenon is considered ungrammatical (as in the case of [it doesn’t matter the N], discussed in the previous chapter).
However, the method of collecting citations cannot be regarded as a scientific method except for the purpose of proving the existence of a phenomenon, and hence does not constitute corpus linguistics proper. While the procedure described by the makers of Merriam Webster’s sounds relatively methodical and organized, it is obvious that the editors will be guided in their selection by many factors that would be hard to control even if one were fully aware of them, such as their personal interests, their sense of esthetics, the intensity with which they have thought about some uses of a word as opposed to others, etc.
This can result in a substantial bias in the resulting data base even if the method is applied systematically, a bias that will be reflected in the results of the linguistic analysis, i.e. the definitions and example sentences in the dictionary. To pick a random example: The word of the day on Merriam-Webster’s website at the time of writing is implacable, defined as “not capable of being appeased, significantly changed, or mitigated” (Merriam-Webster, sv. implacable). The entry gives two examples for the use of this word (cf. 4a, b), and the word-of-the-day message gives two more (shown in 4c, d in abbreviated form):
(4) a. He has an implacable hatred for his political opponents.
b. an implacable judge who knew in his bones that the cover-up extended to the highest levels of government
c. ...the implacable laws of the universe are of interest to me.
d. Through his audacity, his vision, and his implacable faith in his future success...
Except for hatred, the nouns modified by implacable in these examples are not at all representative of actual usage. The lemmas most frequently modified by implacable in the 450-million-word Corpus of Contemporary American English (COCA) are enemy and foe, followed at some distance by force, hostility, opposition, will, and the hatred found in (4a). Thus, it seems that implacable is used most frequently in contexts describing adversarial human relationships, while the examples that the editors of the Merriam-Websters selected as typical deal mostly with adversarial abstract forces. Perhaps this distortion is due to the materials the editors searched, perhaps the examples struck the editors as citation-worthy precisely because they are slightly unusual, or because they appealed to them esthetically (they all have a certain kind of rhetorical flourish).2
Contrast the performance of the citation-based method with the more strictly corpus-based method used by the Longman Dictionary of English, which illustrates the adjective implacable with the representative examples in (5a,b):
(5) a. implacable enemies
b. The government faces implacable opposition on the issue of nuclear waste. (LDCE, s.v. implacable)
Obviously, the method of citation collection becomes worse the more opportunistically the examples are collected: the researcher will not only focus on examples that they happen to notice, they may also selectively focus on examples that they intuitively deem particularly relevant or representative. In the worst case, they will consciously perform an introspection-based analysis of a phenomenon and then scour the corpus for examples that support this analysis; we could call this method corpus-illustrated linguistics (cf. Tummers et al. 2005). In the case of spoken examples that are overheard and then recorded after the fact, there is an additional problem: researchers will write down what they thought they heard, not what they actually heard.3
The use of corpus examples for illustrative purposes has become somewhat fashionable among researchers who largely depend on introspective “data” otherwise. While it is probably an improvement over the practice of simply inventing data, it has a fundamental weakness: it does not ensure that the data selected by the researcher are actually representative of the phenomenon under investigation. In other words, corpus-illustrated linguistics simply replaces introspectively invented data with introspectively selected data and thus inherits the fallibility of the introspective method discussed in the previous chapter.
Since overcoming the fallibility of introspective data is one of the central motivations for using corpora in the first place, the analysis of a given phenomenon must not be based on a haphazard sample of instances that the researcher happened to notice while reading or, even worse, by searching the corpus for specific examples. The whole point of constructing corpora as representative samples of a language or variety is that they will yield representative samples of particular linguistic phenomena in that language or variety. The best way to achieve this is to draw a complete sample of the phenomenon in question, i.e. to retrieve all instances of it from the corpus (issues of retrieval are discussed in detail in Chapter 4). These instances must then be analyzed systematically, i.e., according to a single set of criteria. This leads to the following definition (cf. Biber & Reppen 2015: 2, Cook 2003: 78):
Definition (Second attempt)
Corpus linguistics is the complete and systematic investigation of linguistic phenomena on the basis of linguistic corpora.
As was mentioned in the preceding section, linguistic corpora are currently between one million and half a billion words in size, while web-based corpora can contain up to a trillion words. As a consequence, it is usually impossible to extract a complete sample of a given phenomenon manually, and this has lead to a widespread use of computers and corpus linguistic software applications in the field.4
In fact, corpus technology has become so central that it is sometimes seen as a defining aspect of corpus linguistics. One corpus linguistics textbook opens with the sentence “The main part of this book consists of a series of case studies which involve the use of corpora and corpus analysis technology” (Partington 1998: 1), and another observes that “[c]orpus linguistics is [...] now inextricably linked to the computer” (Kennedy 1998: 5); a third textbook explicitly includes the “extensive use of computers for analysis, using both automatic and interactive techniques” as one of four defining criteria of corpus linguistics Biber et al. (1998: 4). This perspective is summarized in the following definition:
Definition (Third attempt, Version 1)
Corpus linguistics is the investigation of linguistic phenomena on the basis of computer-readable linguistic corpora using corpus analysis software.
However, the usefulness of this approach is limited. It is true that there are scientific disciplines that are so heavily dependent upon a particular technology that they could not exist without it – for example, radio astronomy (which requires a radio telescope) or radiology (which requires an x-ray machine). However, even in such cases we would hardly want to claim that the technology in question can serve as a defining criterion: one can use the same technology in ways that do not qualify as belonging to the respective discipline. For example, a spy might use a radio telescope to intercept enemy transmissions, and an engineer may use an x-ray machine to detect fractures in a steel girder, but that does not make the spy a radio astronomer or the engineer a radiologist.
Clearly, even a discipline that relies crucially on a particular technology cannot be defined by the technology itself but by the uses to which it puts that technology. If anything, we must thus replace the reference to corpus analysis software by a reference to what that software typically does.
Software packages for corpus analysis vary in capability, but they all allow us to search a corpus for a particular (set of) linguistic expression(s) (typically word forms), by formulating a query using query languages of various degrees of abstractness and complexity, and they all display the results (or hits) of that query. Specifically, most of these software packages have the following functions:
- they produce KWIC (Key Word In Context) concordances, i.e. they display the hits for our query in their immediate context, defined in terms of a particular number of words or characters to the left and the right (see Figure 2.6 for a KWIC concordance of the noun time) – they are often referred to as concordancers because of this functionality;
- they identify collocates of a given expression, i.e. word forms that occur in a certain position relative to the hits; these words are typically listed in the order of frequency with which they occur in the position in question (see Table 2.4 for a list of collocates of the noun time in a span of three words to the left and right);
- they produce frequency lists, i.e. lists of all character strings in a given corpus listed in the order of their frequency of occurrence (see Table 2.5 for the forty most frequent strings (word forms and punctuation marks) in the BNC Baby).
Note that concordancers differ with respect to their ability to deal with annotation – there are few standards in annotation, especially in older corpora and even the emerging XML-based standards, or wide-spread conventions like the column format shown in Figure 2.5 above are not implemented in many of the widely available software packages.
Let us briefly look at why the three functions listed above might be useful in corpus linguistic research (we will discuss them in more detail in later chapters).
A concordance provides a quick overview of the typical usage of a particular (set of) word forms or more complex linguistic expressions. The occurrences are presented in random order in Figure 2.6, but corpus-linguistic software packages typically allow the researcher to sort concordances in various ways, for example, by the first word to the left or to the right; this will give us an even better idea as to what the typical usage contexts for the expression under investigation are.
Collocate lists are a useful way of summarizing the contexts of a linguistic expression. For example, the collocate list in the column marked L1 in Table 2.4 will show us at a glance what words typically directly precede the string time. The determiners the and this are presumably due to the fact that we are dealing with a noun, but the adjectives first, same, long, some, last, every and next are related specifically to the meaning of the noun time; the high frequency of the prepositions at, by, for and in in the column marked L2 (two words to the left of the node word time) not only gives us additional information about the meaning and phraseology associated with the word time, it also tells us that time frequently occurs in prepositional phrases in general.
Finally, frequency lists provide useful information about the distribution of word forms (and, in the case of written language, punctuation marks) in a particular corpus. This can be useful, for example, in comparing the structural properties or typical contents of different language varieties (see further Chapter 10). It is also useful in assessing which collocates of a particular word are frequent only because they are frequent in the corpus in general, and which collocates actually tell us something interesting about a particular word.
Table 2.4: Collocates of time in a span of three words to the left and to the right
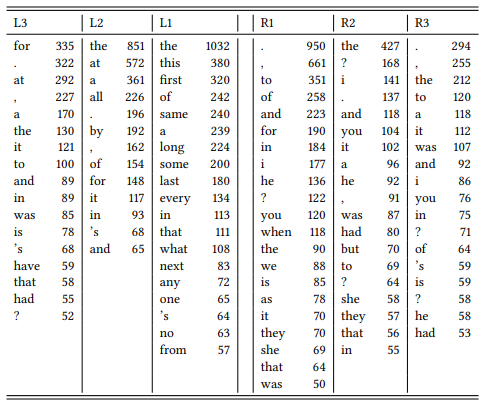
Table 2.5: The forty most frequent strings in the BNC Baby
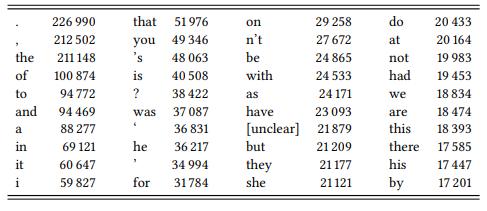
Figure 2.6: KWIC concordance (random sample) of the noun time (BNC Baby)

Note, for example, that the collocate frequency lists on the right side of the word time are more similar to the general frequency list than those on the left side, suggesting that the noun time has a stronger influence on the words preceding it than on the words following it (see further Chapter 7).
Given the widespread implementation of these three techniques, they are obviously central to corpus linguistics research, so we might amend the definition above as follows (a similar definition is implied by Kennedy (1998: 244–258)):
Definition (Third attempt, Version 2)
Corpus linguistics is the investigation of linguistic phenomena on the basis of concordances, collocations, and frequency lists.
Two problems remain with this definition. The first problem is that the requirements of systematicity and completeness that were introduced in the second definition are missing. This can be remedied by combining the second and third definition as follows:
Definition (Combined second and third attempt)
Corpus linguistics is the complete and systematic investigation of linguistic phenomena on the basis of linguistic corpora using concordances, collocations, and frequency lists.
The second problem is that including a list of specific techniques in the definition of a discipline seems undesirable, no matter how central these techniques are. First, such a list will necessarily be finite and will thus limit the imagination of future researchers. Second, and more importantly, it presents the techniques in question as an arbitrary set, while it would clearly be desirable to characterize them in terms that capture the reasons for their central role in the discipline.
What concordances, collocate lists and frequency lists have in common is that they are all ways of studying the distribution of linguistic elements in a corpus. Thus, we could define corpus linguistics as follows:
Definition (Fourth attempt)
Corpus linguistics is the complete and systematic investigation of the distribution of linguistic phenomena in a linguistic corpus.
On the one hand, this definition subsumes the previous two definitions: If we assume that corpus linguistics is essentially the study of the distribution of linguistic phenomena in a linguistic corpus, we immediately understand the central role of the techniques described above: (i) KWIC concordances are a way of displaying the distribution of an expression across different syntagmatic contexts; (ii) collocation tables summarize the distribution of lexical items with respect to other lexical items in quantitative terms, and (iii) frequency lists summarize the overall quantitative distribution of lexical items in a given corpus.
On the other hand, the definition is not limited to these techniques but can be applied open-endedly on all levels of language and to all kinds of distributions. This definition is close to the understanding of corpus linguistics that this book will advance, but it must still be narrowed down somewhat.
First, it must not be misunderstood to suggest that studying the distribution of linguistic phenomena is an end in itself in corpus linguistics. Fillmore (1992: 35) presents a caricature of a corpus linguist who is “busy determining the relative frequencies of the eleven parts of speech as the first word of a sentence versus as the second word of a sentence”. Of course, there is nothing intrinsically wrong with such a research project: when large electronically readable corpora and the computing power to access them became available in the late 1950s, linguists became aware of a vast range of stochastic regularities of natural languages that had previously been difficult or impossible to detect and that are certainly worthy of study. Narrowing our definition to this stochastic perspective would give us the following:
Definition (Fourth attempt, stochastic interpretation)
Corpus linguistics is the investigation of the statistical properties of language.
However, while the statistical properties of language are a worthwhile and actively researched area, they are not the primary object of research in corpus linguistics. Instead, the definition just given captures an important aspect of a discipline referred to as statistical or stochastic natural language processing (Manning & Schütze 1999 is a good, if somewhat dense introduction to this field).
Stochastic natural language processing and corpus linguistics are closely related fields that have frequently profited from each other (see, e.g., Kennedy 1998: 5); it is understandable, therefore, that they are sometimes conflated (see, e.g., Sebba & Fligelstone 1994: 769). However, the two disciplines are best regarded as overlapping but separate research programs with very different research interests.
Corpus linguistics, as its name suggests, is part of linguistics and thus focuses on linguistic research questions that may include, but are in no way limited to the stochastic properties of language. Adding this perspective to our definition, we get the following:
Definition (Fourth attempt, linguistic interpretation)
Corpus linguistics is the investigation of linguistic research questions based on the complete and systematic analysis of the distribution of linguistic phenomena in a linguistic corpus.
This is a fairly accurate definition, in the sense that it describes the actual practice of a large body of corpus-linguistic research in a way that distinguishes it from similar kinds of research. It is not suitable as a final characterization of corpus linguistics yet, as the phrase “distribution of linguistic phenomena” is still somewhat vague. The next section will explicate this phrase.
2 This kind of distortion means that it is dangerous to base analyses on examples included in citation-based dictionaries; but Mair (cf. 2004), who shows that, given an appropriately constrained research design, the dangers of an unsystematically collected citation base can be circumvented (see Section 8.2.5.3 below).
3 As anyone who has ever tried to transcribe spoken data, this implicit distortion of data is a problem even where the data is available as a recording: transcribers of spoken data are forever struggling with it. Just record a minute of spoken language and try to transcribe it exactly – you will be surprised how frequently you transcribe something that is similar, but not identical to what is on the tape.
4 Note, however, that sometimes manual extraction is the only option – cf. Colleman (2006; 2009), who manually searched a 1-million word corpus of Dutch in order to extract all ditransitive clauses. To convey a rough idea of the work load involved in this kind of manual extraction: it took Colleman ten full work days to go through the entire corpus (Colleman, pers. comm.), which means his reading speed was fairly close to the 200 words typical for an average reader, an impressive feat given that he was scanning the corpus for a particular phenomenon.