
8.3: The Poverty of Stimulus
- Page ID
- 21252

Some researchers have noted a striking tension between experience and science (Varela, Thompson, & Rosch, 1991). On the one hand, our everyday experience provides a compelling and anchoring sense of self-consciousness. On the other hand, cognitive science assumes a fundamental self-fragmentation, because much of thought is putatively mediated by mechanisms that are modular, independent, and completely incapable of becoming part of conscious experience. “Thus cognitivism challenges our conviction that consciousness and the mind either amount to the same thing or [that] there is an essential or necessary connection between them” (p. 49).
The tension between experience and science is abundantly evident in vision research. It is certainly true that the scientific study of visual perception relies heavily on the analysis of visual experience (Pylyshyn, 2003c). However, researchers are convinced that this analysis must be performed with caution and be supplemented by additional methodologies. This is because visual experience is not complete, in the sense that it does not provide direct access to or experience of visual processing. Pylyshyn (2003b) wrote,
what we do [experience] is misleading because it is always the world as it appears to us that we see, not the real work that is being done by the mind in going from the proximal stimuli, generally optical patterns on the retina, to the familiar experience of seeing (or imagining) the world. (Pylyshyn, 2003b, p. xii)
Vision researchers have long been aware that the machinery of vision is not a part of our visual experience. Helmholtz noted that “it might seem that nothing could be easier than to be conscious of one’s own sensations; and yet experience shows that for the discovery of subjective sensations some special talent is needed” (Helmholtz & Southall, 1962b, p. 6). Cognitive psychologist Roger Shepard observed that,
we do not first experience a two-dimensional image and then consciously calculate or infer the three-dimensional scene that is most likely, given that image. The first thing we experience is the three-dimensional world—as our visual system has already inferred it for us on the basis of the two-dimensional input. (Shepard, 1990, p. 168)
In the nineteenth century, Hermann von Helmholtz argued that our visual experience results from the work of unconscious mechanisms. “The psychic activities that lead us to infer that there in front of us at a certain place there is a certain object of a certain character, are generally not conscious activities, but unconscious ones” (Helmholtz & Southall, 1962b, p. 4). However, the extent and nature of this unconscious processing was only revealed when researchers attempted to program computers to see. It was then discovered that visual processes face a difficult problem that also spurred advances in modern linguistic theory: the poverty of the stimulus.
Generative linguistics distinguished between those theories of language that were descriptively adequate and those that were explanatorily adequate (Chomsky, 1965). A descriptively adequate theory of language provided a grammar that was capable of describing the structure of any possible grammatical sentence in a language and incapable of describing the structure of any sentence that did not belong to this language. A more powerful explanatorily adequate theory was descriptively adequate but also provided an account of how that grammar was learned. “To the extent that a linguistic theory succeeds in selecting a descriptively adequate grammar on the basis of primary linguistic data, we can say that it meets the condition of explanatory adequacy” (p. 25).
Why did Chomsky use the ability to account for language learning as a defining characteristic of explanatory adequacy? It was because Chomsky realized that language learning faced the poverty of the stimulus. The poverty-of-the-stimulus argument is the claim that primary linguistic data—that is, the linguistic utterances heard by a child—do not contain enough information to uniquely specify the grammar used to produce them.
It seems that a child must have the ability to ‘invent’ a generative grammar that defines well-formedness and assigns interpretations to sentences even though the primary linguistic data that he uses as a basis for this act of theory construction may, from the point of view of the theory he constructs, be deficient in various respects. (Chomsky, 1965, p. 201)
The poverty of the stimulus is responsible for formal proofs that text learning of a language is not possible if the language is defined by a complex grammar (Gold, 1967; Pinker, 1979; Wexler & Culicover, 1980).
Language acquisition can be described as solving the projection problem: determining the mapping from primary linguistic data to the acquired grammar (Baker, 1979; Peters, 1972). When language learning is so construed, the poverty of the stimulus becomes a problem of underdetermination. That is, the projection from data to grammar is not unique, but is instead one-to-many: one set of primary linguistic data is consistent with many potential grammars.
For sighted individuals, our visual experience makes us take visual perception for granted. We have the sense that we simply look at the world and see it. Indeed, the phenomenology of vision led artificial intelligence pioneers to expect that building vision into computers would be a straightforward problem. For instance, Marvin Minsky assigned one student, as a summer project, the task of programming a computer to see (Horgan, 1993). However, failures to develop computer vision made it apparent that the human visual system was effortlessly solving, in real time, enormously complicated information processing problems. Like language learning, vision is dramatically underdetermined. That is, if one views vision as the projection from primary visual data (the proximal stimulus on the retina) to the internal interpretation or representation of the distal scene, this projection is one-to-many. A single proximal stimulus is consistent with an infinite number of different interpretations (Gregory, 1970; Marr, 1982; Pylyshyn, 2003c; Rock, 1983; Shepard, 1990).
One reason that vision is underdetermined is because the distal world is arranged in three dimensions of space, but the primary source of visual information we have about it comes from patterns of light projected onto an essentially two dimensional surface, the retina. “According to a fundamental theorem of topology, the relations between objects in a space of three dimensions cannot all be preserved in a two-dimensional projection” (Shepard, 1990, pp. 173–175).
This source of underdetermination is illustrated in Figure 8-1, which illustrates a view from the top of an eye observing a point in the distal world as it moves from position X1 to position Y1 over a given interval of time.
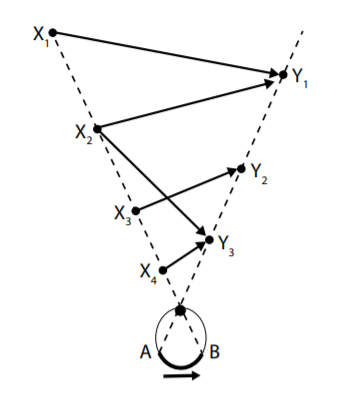
Figure 8-1. Underdetermination of projected movement.
The primary visual data caused by this movement is the motion, from point A to point B, of a point projected onto the back of the retina. The projection from the world to the back of the eye is uniquely defined by the laws of optics and of projective geometry.
However, the projection in the other direction, from the retina to the distal world, is not unique. If one attempts to use the retinal information alone to identify the distal conditions that caused it, then infinitely many possibilities are available. Any of the different paths of motion in the world (occurring over the same duration) that are illustrated in Figure 8-1 are consistent with the proximal information projected onto the eye. Indeed, movement from any position along the dashed line through the X-labelled points to any position along the other dashed line is a potential cause of the proximal stimulus.
One reason for the poverty of the visual stimulus, as illustrated in Figure 8-1, is that information is necessarily lost when an image from a three-dimensional space is projected onto a two-dimensional surface.
We are so familiar with seeing, that it takes a leap of imagination to realize that there are problems to be solved. But consider it. We are given tiny distorted upsidedown images in the eyes, and we see separate solid objects in surrounding space. From the patterns of stimulation on the retinas we perceive the world of objects, and this is nothing short of a miracle. (Gregory, 1978, p. 9)
A second reason for the poverty of the visual stimulus arises because the neural circuitry that mediates visual perception is subject to the limited order constraint (Minsky & Papert, 1969). There is no single receptor that takes in the entire visual stimulus in a glance. Instead, each receptor processes only a small part of the primary visual data. This produces deficiencies in visual information. For example, consider the aperture problem that arises in motion perception (Hildreth, 1983), illustrated in Figure 8-2.
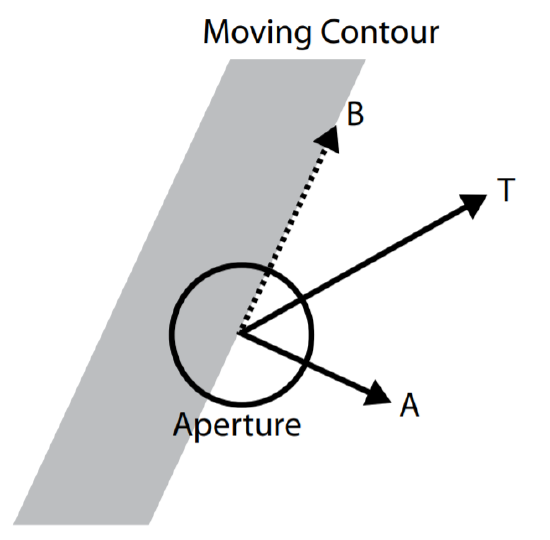
Figure 8-2. The aperture problem in motion perception.
In this situation, a motion detector’s task is to detect the movement of a contour, shown in grey. However, the motion detector is of limited order: its window on the moving contour is the circular aperture in the figure, an aperture that is much smaller than the contour it observes.
Because of its small aperture, the motion detector in Figure 8-2 can only be sensitive to the component of the contour’s motion that is perpendicular to the edge of the contour, vector A. It is completely blind to any motion parallel to the contour, the dashed vector B. This is because movement in this direction will not change the appearance of anything within the aperture. As a result, the motion detector is unable to detect the true movement of the contour, vector T.
The limited order constraint leads to a further source of visual underdetermination. If visual detectors are of limited order, then our interpretation of the proximal stimulus must be the result of combining many different (and deficient) local measurements together. However, many different global interpretations exist that are consistent with a single set of such measurements. The local measurements by themselves cannot uniquely determine the global perception that we experience.
Consider the aperture problem of Figure 8-2 again. Imagine one, or many, local motion detectors that deliver vector A at many points along that contour. How many true motions of the contour could produce this situation? In principle, one can create an infinite number of different possible vector Ts by choosing any desired length of vector B—to which any of the detectors are completely blind—and adding it to the motion that is actually detected, i.e., vector A.
Pylyshyn (2003b, 2007) provided many arguments against the theory that vision constructs a representation of the world, which is depictive in nature. However, the theory that Pylyshyn opposed is deeply entrenched in accounts of visual processing.
For years the common view has been that a large-scope inner image is built up by superimposing information from individual glances at the appropriate coordinates of the master image: as the eye moves over a scene, the information on the retina is transmitted to the perceptual system, which then projects it onto an inner screen in the appropriate location, thus painting the larger scene for the mind side to observe. (Pylyshyn, 2003b, pp. 16–17)
Proponents of this view face another source of the poverty of the visual stimulus. It is analogous to the limited order constraint, in the sense that it arises because vision proceeds by accessing small amounts of information in a sequence of fragmentary glimpses.
Although we experience our visual world as a rich, stable panorama that is present in its entirety, this experience is illusory (Dennett, 1991; Pylyshyn, 2003c, 2007). Evidence suggests that we only experience fragments of the distal world a glance at a time. For instance, we are prone to change blindness, where we fail to notice a substantial visual change even though it occurs in plain sight (O’Regan et al., 2000). A related phenomenon is inattentional blindness, in which visual information that should be obvious is not noticed because attention is not directed to it (even though the gaze is!). In one famous experiment (Simons & Chabris, 1999), subjects watched a video of a basketball game and were instructed to count the number of times that the teams changed possession of the ball. In the midst of the game a person dressed in a gorilla suit walked out onto the court and danced a jig. Amazingly, most subjects failed to notice this highly visible event because they were paying attention to the ball.
If the visual system collects fragments of visual information a glance at a time, then our visual experience further suggests that these different fragments are “stitched together” to create a stable panorama. In order for this to occur, the fragments have to be inserted in the correct place, presumably by identifying components of the fragment (in terms of visible properties) in such a way that it can be asserted that “object x in one location in a glimpse collected at time t + 1 is the same thing as object y in a different location in a glimpse collected at an earlier time t.” This involves computing correspondence, or tracking the identities of objects over time or space, a problem central to the study of binocular vision (Marr, Palm, & Poggio, 1978; Marr & Poggio, 1979) and motion perception (Dawson, 1991; Dawson & Pylyshyn, 1988; Ullman, 1978, 1979).
However, the computing of correspondence is a classic problem of underdetermination. If there are N different elements in two different views of a scene, then there are at least N! ways to match the identities of elements across the views. This problem cannot be solved by image matching—basing the matches on the appearance or description of elements in the different views—because the dynamic nature of the world, coupled with the loss of information about it when it is projected onto the eyes, means that there are usually radical changes to an object’s proximal stimulus over even brief periods of time.
How do we know which description uniquely applies to a particular individual and, what’s more important, how do we know which description will be unique at some time in the future when we will need to find the representation of that particular token again in order to add some newly noticed information to it? (Pylyshyn, 2007, p. 12)
To summarize, visual perception is intrinsically underdetermined because of the poverty of the visual stimulus. If the goal of vision is to construct representations of the distal world, then proximal stimuli do not themselves contain enough information to accomplish this goal. In principle, an infinite number of distal scenes could be the cause of a single proximal stimulus. “And yet we do not perceive a range of possible alternative worlds when we look out at a scene. We invariably see a single unique layout. Somehow the visual system manages to select one of the myriad logical possibilities” (Pylyshyn, 2003b, p. 94). Furthermore, the interpretation selected by the visual system seems—from our success in interacting with the world—to almost always be correct. “What is remarkable is that we err so seldom” (Shepard, 1990, p. 175).
How does the visual system compensate for the poverty of the stimulus as well as generate unique and accurate solutions to problems of underdetermination? In the following sections we consider two very different answers to this question, both of which are central to Pylyshyn’s theory of visual cognition. The first of these, which can be traced back to Helmholtz (Helmholtz & Southall, 1962b) and which became entrenched with the popularity of the New Look in the 1950s (Bruner, 1957, 1992), is that visual perception is full-fledged cognitive processing. “Given the slenderest clues to the nature of surrounding objects we identify them and act not so much according to what is directly sensed, but to what is believed” (Gregory, 1970, p. 11).