
7.1: Morphemes
- Last updated
- Save as PDF
- Page ID
- 7038

The Lexical-grammatical Continuum
Let's compare some of the kinds of words we have encountered so far. A common noun like apple refers to a relatively specific category of things, with a narrow range of values on a number of dimensions (shape, size, consistency, taste, reflectivity, etc.). This category is one of thousands of categories of things that people know about and that all languages have words for (though not all languages agree on which specific categories of course). A verb like run refers to a relative specific category of move event with a characteristic set of semantic roles, a specified manner (in the most basic sense of the word, a characteristic pattern of movement of the legs resulting in a relatively rapid movement). This category is one of at least hundreds of categories of events and states that people know about and that all languages have words for.
Compare these words with a word like he. Very little is specified with this word — a gender, a person, a number, and a case (nominative) — and it can potentially refer to a very wide range of things, nearly half of the people in the world in fact, as well as some animals under the right circumstances. The word he belongs not to a set of hundreds or thousands of words but to a set of about 12 words, the personal pronouns of English. Likewise, consider the preposition on, which designates a spatial relation between two things (the book is on the table) or between an event and a thing (Lois put the book on the table). This relation is one of a very small set of spatial relations that English has words for; other words in this set include in, at, over, under, and beside.
The point is that words differ in terms of how abstract and general their meanings are. On the relatively specific, concrete end of this continuum, we have nouns, verbs, and adjectives, each designating a quite particular category of thing, situation, or attribute. There are not only many such words; the sets of these words are also relatively open-ended. Speakers can freely add new words to the "list". Within the last 100 years, English speakers have created nouns such as nerd and grunge; verbs such as diss and zap; and adjectives such as icky and PC.
On the relatively general, abstract end of the continuum, we have pronouns such as he and prepositions such as on. Each of these words has a very general meaning and so designates a very wide variety of things or situations. The words belong to small sets such as personal pronouns and prepositions which are not often extended in the history of the language. Imagine the strangeness of creating a new preposition for a particular spatial relation, say, agrope for being partly inside and partly outside of something (the pencil is agrope the cup). But there are even more abstract words. Take the or a, for example. Such words seem almost to have no meaning at all. (Of course they do have a meaning, but it is very abstract and difficult to describe.)
I will call this continuum that extends from words like apple on one end to words like the on the other the lexical-grammatical continuum. In this chapter and the next chapter, we'll be focusing on the grammatical end of the continuum. It is probably in this area of abstract meanings that languages differ most from one another. One language may pick up on an aspect of meaning that is ignored in the grammar of another language. In fact if there is place where the language you know influences the way you think or perceive the world, it is here.
Grammatical Morphemes
Exercise \(\PageIndex{1}\)
What is the difference in meaning between apple and apples? What is the difference in form? What does this tell you about these two words?
Words Can Have an Internal Structure Much Like the Syntax of Phrases
Because words on the grammatical end of the lexical-grammatical continuum have such vague meanings, they do not contribute as much to the overall meaning of a sentence as nouns, verbs, and adjectives do. For this reason, they tend to get less emphasis from speakers. They tend to be short and to receive no stress. Over time, this may lead them to lose the character of words altogether and become "attached" in some sense to nouns, verbs, or adjectives. Here are a few English examples.
- pencils
- walked
- unnecessarily
- reconnecting
In each case there is a basic word on the lexical end of the continuum: pencil, walk, necessary, connect. In addition there are one or more elements attached to the beginnings or ends of these words to make longer, more complex words. These elements include -s, -ed, un-, -ly, re-, and -ing, where the hyphens indicate which side these elements attach to. In each case, these elements also contribute some meaning to the larger word. For example, in reconnecting, the re- indicates a repetition of the connecting. But in this section I'll have little more to say about the meanings of such elements. The focus for the moment is on their form.
In what sense are these elements not words? It turns out that "wordhood" is a matter of degree, like so many other concepts in linguistics. And like some other concepts, it is multi-dimensional; there are different criteria for being a word. First, a word should be pronounceable. In the most extreme cases, for example, -s in pencils(pronounced /z/) and -ed in walked (pronounced /t/), these elements that we're considering are not even legitimate English syllables. So on grounds of pronounceability, these make very bad words.
Second, a word should have a coherent form that does not depend much on its neighbors. In this sense the element that we write "ed" is not a good word because it is pronounced /t/ in words such as walked, /d/ in words such as lived, and /@d/ in words such as needed.
Third, a word should be relatively independent of the other words around it; that is, it should be possible to separate it from them with other words. In this sense -ed is not a good word since there is normally nothing that can separate it from the verb it follows; we can't say things like walk away ed or walk alone ed. By the same token, re- does not make a good word since it cannot be separated from the verb it precedes; it is impossible to say things like re carefully connect or re don't connect.
Since forms like -s, -ed, and re- are not words, we need another name for them. Each of these forms has a meaning (though as we'll see later in this chapter, the meaning may be so abstract that it is difficult to describe), and it can't be further subdivided into smaller pieces that have meaning. Such a unit is called a morpheme. Note that by this definition a full-fledged word like cat is also a morpheme because it has a meaning and cannot be broken into smaller meaningful units.
Morphemes near the lexical end of the lexical-grammatical continuum are called lexical morphemes; morphemes such as the, -s, and re- near the grammatical end of the continuum are called grammatical morphemes. Note that grammatical morphemes include forms that we can consider to be words like the, a, and, and ofand others that make up parts of words like -s, -ed, un-, and re-.
In a word consisting of more than one morpheme, there is normally at least one lexical morpheme. Thus the word walking consists of two morphemes, a lexical morpheme, walk, and a grammatical morpheme, -ing. The word cropduster consists of three morphemes, two lexical morphemes, crop and dust, and a grammatical morpheme, -er. In this section we'll only be looking at words with a single lexical morpheme and one more grammatical morphemes. In these cases we'll call the lexical morpheme the root of the word. So in the word walking, the root is walk, and in the word carefully, the root is care.
Kinds of Morphological Combination
Exercise \(\PageIndex{2}\)
How many morphemes do you think the word feet contains? If more than one, what are they?
A root combines with one or more grammatical morphemes in various ways. In this section, we'll look at the different possibilities that exist in the world's languages.
Affixation
Grammatical Morphemes Can Be Added Before, After, and Within Roots
The examples we've seen so far involve adding grammatical morphemes before or after the root. When they precede the root, they are called prefixes; when they follow it, they are called suffixes. We can also speak of the processes of adding these morphemes; these are called prefixation and suffixation. Prefixation and suffixation are the most common ways in which grammatical morphemes combine with roots in the world's languages. Note that a single word can include more than one suffix and more than one prefix. For example, the word muddier includes two suffixes, -y (spelled "i" in this word) and -er.
In English the root of a word with one or more prefixes or suffixes is usually a word in its own right. Thus the root of walked, walk, is a word, and the root of taller, tall, is a word. This is not always true in other languages. In Japanese, Spanish, Lingala, and Inuktitut for example, every verb must have a grammatical suffix of one sort or another; the root cannot occur by itself. The Japanese verb yobu means 'call + present'; that is, 'call' in the present time. It consists of the root yob- 'sing' and the grammatical morpheme -u 'present', but yob- cannot occur by itself as a word; in fact it is not even a pronounceable Japanese syllable.
There are also two less common ways to add a grammatical morpheme. One is a single morpheme that combines a part before the root and a part after the root. For example, the Amharic verb alhedεm means 'he didn't go'. In this word the part that makes the negative, that is, that corresponds to English not consists of two parts, al-and -m. Such a morpheme is called a circumfix.
Another possibility is a morpheme that gets inserted within a root, breaking up the phonemes of the root. Such a morpheme is called an infix. In Tzeltal infixation can apply to some verbs for human actions to yield a form used for counting the actions. For example, lotz is a verb root meaning 'strike with the hand', and the word lojtz is used for counting blows of the hand. This word consists of the root lotz and the infix -j-, which is inserted right after the vowel in the root.
Suffixes, prefixes, circumfixes, and infixes are all types of affixes, morphemes that are added to a root.
Mutation
Additional Morphemes Don't Necessarily Mean Longer Words
Rather than add material, a grammatical morpheme can change some part of the root; this is called mutation. English examples include the past forms of some verbs. From the verb root sing, there is the past form sang; from the verb root take the past form took. In sang, the vowel in the root, /I/, has been changed to /æ/. In took, the vowel in the root, /e/, has been changed to /U/.
In sign languages it is relatively simple to produce separate morphemes simultaneously. In this sort of case, we can see a grammatical morpheme as modifying the lexical morpheme that it is superimposed on, a kind of mutation. For example, the basic sign for 'give' is shown below; it can be produced with either one or two hands.
However, the direction of the movement is modified to reflect who is the agent and who is the recipient of the giving. If the signer is the recipient, for example, the movement is toward rather than away from the signer. Such signs can be seen as a combination of the root sign for 'give' and a grammatical morpheme which "mutates" the root by modifying the direction of the movement.
Template
So far all morphemes have consisted of segments (sounds) which appear consecutively in a particular sequence (unless they are interrupted by an infix). But a morpheme may also be discontinuous; that is, its segments may normally be separated by segments from other morphemes. This process is best known from Semitic languages like Arabic, Hebrew, and Amharic. Here are some Amharic verb examples.
- mεsbεr 'to break'
- sεbbεrε 'he broke'
- yIsεbral 'he breaks'
- sIbεr 'break!'
What all of these words share is sequence of segments sbr. This sequence makes up the root of the verb that means 'break' in Amharic. These three consonants never actually appear in sequence, however. In fact, they are not even pronounceable as a sequence in Amharic. Instead they combine with another morpheme specifying the time of the breaking and various other meanings to form a pronounceable form, called the "stem" of the word, to which prefixes and or suffixes are added. This morpheme that combines with the root is a kind of template for making the stem. It consists of vowels and positions in the stem for the root consonants. In addition, it sometimes specifies that the root consonants are lengthened. Here is how the root sbr combines with the past morpheme to make the stem for the word 6 above, sεbbεr-.
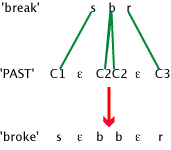
To make word 6 above, a suffix meaning 'he', -ε is added to the stem. Word 7, yIsεbral, has both a prefix, yI-, and a suffix, -al. These are added to the stem for that word, -sεbr-, which means 'break + present'.
Reduplication
Another common way to combine lexical and grammatical morphemes, though not common in the languages of Europe, is by copying some portion of the root. The copied part is placed before, after, or within the root, as if it were an affix. It differs from an affix in that its form depends entirely on the root. Here are some examples from Amharic.
- get' 'jewel'; get'aget' 'jewelry'
- bIrεt 'iron'; bIrεtabIrεt 'hardware'
- sεbbεrε 'he broke'; sεbabbεrε 'he repeatedly broke'
- lεk'k'εmε 'he picked up'; lεk'ak'k'εmε 'he picked up multiple things'
In the first two examples, a noun root (which is also a word in its own right) is given first. In the complex form given second, there are two morphemes. The grammatical morpheme takes the form of the complete reduplication of the noun separated by -a-. This morpheme extends the meaning of the root noun to a general category of merchandise including the category that the original noun designates.
The second two examples are more complicated. Recall from the discussion of template morphology above that an Amharic verb root can consist of three consonants. From the examples there, you know that the root for the verb meaning 'break' is sbr. In 11, sεbabbεrε includes a copy of the second consonant of the root and an additional vowel, -a-, separating that consonant from the root consonant: sεbabbεrε. Notice that the same pattern appears in the last example. The verb root for these words is lk'm 'pick up'. The reduplication morpheme in the last two examples means 'repeatedly' or 'with multiple objects'.
Solving Morphology Problems
Exercise \(\PageIndex{3}\)
What would be required for a language learner to figure out that words like apples, tigers, and caves consist of two morphemes?
The combination of grammatical morphemes with a root is normally a productive process. That is, given knowledge of the morphemes and a rule for how to combine them, a Speaker can produce novel words and a Hearer can understand novel words. For example, as an English speaker, you could learn a new noun vorg referring to some category of object, and you could then produce the form of the noun to refer to more than one vorg, vorgs. You would not have to be told how to do this.
The morphology of a language is the set of conventions that govern how words in the language are made up out of morphemes. Morphological conventions concern both the forms of words and the meanings of words. Just as learning a language involves learning the lexical, phonological, and syntactic conventions that were discussed in previous chapters, it involves learning morphological conventions. And a linguist analyzing a language will also want to figure out the language's morphology, both in order to describe the language adequately and to discover what universal principles apply to morphology.
Languages Differ Greatly in Terms of the Number and Type of Grammatical Morphemes that Combine with Lexical Morphemes
To learn morphology, you need examples of words along with their meanings. If you are a second language learner or a linguist, in place of meanings, you may be given a translation of the words into a language you already know. The translation may be deceptive in one way. The number of morphemes in a word in one language will often not correspond to the number of morphemes in a translation of that word into another language. The Japanese word tabemashita means 'ate', that is, 'eat + past', but it also includes a morpheme which conveys the formality of the situation where it is used, a morpheme that would not normally be translated at all in English. To make things simpler, in what follows I will give a gloss for each word that makes it clear how many morphemes the word contains.
Three other factors can also make morphology complicated to figure out. First, within a given category of words such as verbs, there may be subcategories with different morphological behavior. In Spanish, and other Romance languages, there are three different categories of verbs, each with its own suffixes. Second, the form of a morpheme may depend on what other morphemes it combines with. For example, in needed, the suffix is pronounced /@d/ whereas it is pronounced /t/ in walked. You'll learn more about this in a later section. Third, a single grammatical morpheme may combine several different meanings. This is common with Spanish verbs. For example, in the verb cantó 'he sang', the morpheme ó (the accent mark indicates stress on this vowel) means 'he + past'. In this section, all of the examples will avoid difficulties of these three types.
Let's consider an Amharic example. You already know from the section on template morphology above how the past form of at least one verb is produced. Here are some more examples of verbs in the past, together with their glosses in English. Where items are separated by a colon, they represent the meaning of one Amharic morpheme.
- mεkkεrεŋ 'he advised me'
- mεkkεrεš 'he advised you:feminine'
- mεkkεrε 'he advised'
- mεkkεrkuh 'I advised you:masculine'
- mεkkεrkuš 'I advised you:feminine'
- sεddεbu 'they insulted'
- sεddεbun 'they insulted us'
- sεddεbku 'I insulted'
- sεddεbεš 'he insulted you:feminine'
- sεddεbεn 'he insulted us'
- k'εt't'εrεŋ 'he hired me'
- k'εt't'εrεh 'he hired you:masculine'
- k'εt't'εrkuh 'I hired you:masculine'
- k'εt't'εruš 'they hired you:feminine'
- k'εt't'εruŋ 'they hired me'
First, examine all of the glosses to get an idea of what the range of morphemes is. You can see that every word includes either three or four morphemes, that every word includes the past morpheme and a verb root, that every word includes a morpheme representing the subject of the verb, and that some of the words include a morpheme representing the direct object of the verb.
Next, look for pairs of words that differ by only one morpheme. One example is sεddεbu 'they insulted' and sεddεbun 'they insulted us'. The glosses indicate that these two words share the morphemes meaning 'they', 'insult', and 'past', and that the second word has an additional morpheme meaning 'us'. Examining the forms, try to figure out what is added or changed in the form to give the second; whatever this is should mean 'us'. It's easy to see that the second form has the suffix -n, so we can assign this suffix the meaning 'us'. At this point, we should note the position of this morpheme because we not only expect it to always occur in the same position, but it is also likely that other direct object morphemes will occur in this position.
Another pair differing by only one morpheme is mεkkεrεŋ 'he advised me' and mεkkεrεš 'he advised you:feminine'. These two words share the morphemes meaning 'he', 'advise', and 'past', and they differ in the fourth morpheme, which means 'me' in the first word and 'you:feminine' in the second word. Note that this is 'you:feminine' as direct object. From the two forms we see that they share mεkkεrε, so this must mean 'he advised'. The remaining parts of the words are '-ŋ' and '-š', so these must mean 'me' and 'you:feminine'.
Continuing in this way, and given what you already know about the past of Amharic verbs, you should be able to figure out the following.
- mkr 'advise'
- sdb 'insult'
- k't'r 'hire'
- C1 ε C2C2 ε C3 'past'
- -ε 'he'
- -ku 'I'
- -u 'they'
- -ŋ 'me'
- -n 'us'
- -h 'you:masculine'
- -š 'you:feminine'
You should also know that the order of the morphemes is the following.
verb_stem subject direct_object
Given this knowledge and a new verb root, you should be able to predict some words. For example, say you're told that the root for the verb meaning 'resemble' is msl. You would then guess that the word for 'I resembled you:masculine' is mεssεlεh.