
3.1: Comparing Sounds and Distribution
- Page ID
- 112673
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)3.1.1 From 4.1 Phonemes and Contrast, in Anderson's Essentials of Linguistics
Video Script
In the last couple of chapters, we’ve seen lots of ways that sounds can differ from each other: they can vary in voicing, in place and manner of articulation, in pitch or length. Within the mental grammar of each language, some of these variations and meaningful and some are not. Each language organizes these meaningful variations in different ways. Let’s look at some examples.
In the English word please, I could pronounce it with an ordinary voiced [l]: [phliz] it would be a little unnatural but it’s possible. Or, because of perseveratory assimilation, I could devoice that [l] and pronounce it [phl̥iz]. We’ve got two slightly different sounds here: both are alveolar lateral approximants, but one is voiced and one is voiceless. But if I pronounce the word [phliz] or [phl̥iz], it means the same thing. The voicing difference in this environment is not meaningful in English and most people never notice if the [l] is voiced or not.
In the words van and fan, each word begins with a labio-dental fricative. In van, the fricative is voiced and in fan it’s voiceless. In this case, the difference in voicing is meaningful: it leads to an entirely different word, and all fluent speakers notice this difference! Within the mental grammar of English speakers, the difference between voiced and voiceless sounds is meaningful in some environments but not in others.
Here’s another example. I could pronounce the word free with the ordinary high front tense vowel [i]. Or I could make the vowel extra long, freeeee. (Notice that we indicate a long sound with this diacritic [iː] that looks a bit like a colon.) But this difference is not meaningful: In English, both [fri] and [friː] are the same word. In Italian, a length difference is meaningful. The word fato means “fate”. But if I take that alveolar stop and make it long, the word fatto means a “fact”. The difference in the length of the stop makes [fatɔ] and [fatːɔ] two different words. (N.B., In the video there’s an error in how these two words are transcribed; it should be with the [a] vowel, not the [æ] vowel.)
So here’s the pattern that we’re observing. Sounds can vary; they can be different from each other. Some variation is meaningful within the grammar of a given language, and some variation is not.
Until now, we’ve been concentrating on phonetics: how sounds are made and what they sound like. We’re now starting to think about phonology, which looks at how sounds are organized within the mental grammar of each language: which phonetic differences are meaningful, which are predictable, which ones are possible and which ones are impossible within each language. The core principle in phonology is the idea of contrast. Say we have two sounds that are different from each other. If the difference between those two sounds leads to a difference in meaning in a given language, then we say that those two sounds contrast in that language.
So for example, the difference between fan and van is a phonetic difference in voicing. That phonetic difference leads to a substantial difference in meaning in English, so we say that /f/ and /v/ are contrastive in English. And if two sounds are contrastive in a given language, then those two sounds are considered two different phonemes in that language.
So here’s a new term in linguistics. What is a phoneme? A phoneme is something that exists in your mind. It’s a mental category, into which your mind groups sounds that are phonetically similar and gives them all the same label. That mental category contains memories of every time you’ve heard a given sound and labelled it as a member of that category. You could think of a phoneme like a shopping bag in your mind. Every time you hear the segment [f], your mental grammar categorizes it by putting it in bag labelled /f/. /v/ contrasts with /f/ — it’s a different phoneme, so every time you hear that [v], your mind puts it in a different bag, one labelled /v/.
If we look inside that shopping bag, inside the mental category, we might find some phonetic variation. But if the variation is not meaningful, not contrastive, our mental grammar does not treat those different segments as different phonemes. In English, we have a phonemic category for /l/, so whenever we hear the segment [l] we store it in our memory as that phoneme. But voiceless [l̥] is not contrastive: it doesn’t change the meaning of a word, so when we hear voiceless [l̥] we also put it in the same category in our mind. And when we hear a syllabic [l̩], that’s not contrastive either, so we put that in the same category. All of those [l]s are a little different from each other, phonetically, but those phonetic differences are not contrastive because they don’t lead to a change in meaning, so all of those [l]s are members of a single phoneme category in English.
Now, as a linguist, I can tell you that voiceless [f] and voiced [v] are two different phonemes in English, while voiceless [l̥] and voiced [l] are both different members of the same phoneme category in English. But as part of your developing skills in linguistics, you want to be able to figure these things out for yourself. Our question now is, how can we tell if two phonetically different sounds are phonemically contrastive? What evidence would we need? Remember that mental grammar is in the mind — we can’t observe it directly. So what evidence would we want to observe in the language that will allow us to draw conclusions about the mental grammar?
If we observe that a difference between two sounds — a phonetic difference — also leads to a difference in meaning, then we can conclude that the phonetic difference is also a phonemic difference in that language. So our question really is, how do we find differences in meaning?
What we do is look for a minimal pair. We want to find two words that are identical in every way except for the two segments that we’re considering. So the two words are minimally different: the only phonetic difference between them is the difference that we’re interested in. If we can find such a pair, where the minimal phonetic difference leads to a difference in meaning, it’s contrastive, then we can conclude that the phonetic difference between them is a phonemic difference.
We’ve already seen one example of a minimal pair: fan and van are identical in every way except for the first segment. The phonetic difference between [f] and [v] is contrastive; it changes the meaning of the word, so we conclude that /f/ and /v/ are two different phonemes. Can you think of other minimal pairs that give evidence for the phonemic contrast between /f/ and /v/? Take a minute, pause the video, and try to think of some.
Here are some more minimal pairs that I thought of for /f/ and /v/: vine and fine, veal and feel. Minimal pairs don’t have to have the segments that we’re considering at the beginning of the word. Here are some pairs that contrast at the end of the word: have and half, serve and surf. Or the contrast can occur in the middle of the word, like in reviews and refuse. What’s important is that the two words are minimally different: they are the same in all their segments except for the two that we’re considering. And it’s also important to notice that the minimal difference is in the IPA transcription of the word, not in its spelling.
So we’ve got plenty of evidence from all these minimal pairs in English that the phonetic difference between /f/ and /v/ leads to a meaning difference in English, so we can conclude that, in English, /f/ and /v/ are two different phonemes.
Check Yourself
- Answer
-
"Yes"
Hint: There are minimal pairs where the only difference is the nasal: mine [maɪn] and nine [naɪn].
- Answer
-
"No"
Hint: [pʰ] is a variant of [p]
- Answer
-
"No"
Hint: They have different meanings, and they have the exact same IPA transcriptions: [saɪt].
3.1.2: From 4.2 Allophones and Predictable Variation, in Anderson's Essentials of Linguistics
Video Script
In our last unit, we learned about the notion of a phoneme. Remember that a phoneme is something that exists in your mind: it’s like a shopping bag in which your mind stores memories of examples of phonetically similar sounds that are all members of one category. Not all the sounds that you store in one phoneme category have to be identical; in fact, your mental category has room for a lot of variation. Any variants that are not contrastive, that don’t lead to a meaning change, are members of that same phoneme category and are called allophones.
We’ve already seen some examples of allophones of English phonemes as we’ve been learning to transcribe sounds. We know that the alveolar lateral approximant [l] has a voiceless variant [l̥] and a syllabic variant [l̩], but our minds categorize all of them as members of the same phoneme. This shopping-bag metaphor is going to get a little unwieldy, so let’s look at another notation that we can use to represent this phoneme category.
We say that /l/ is the label for the phoneme category itself, it’s the most general form of the phoneme. Notice that instead of using square brackets, for the symbol that represents the whole category we use slashes. In any given word, the phoneme /l/ might get spoken as any one of its allophones, each of which gets represented in square brackets. But where does each allophone appear? Which allophones do we use in which words? One of the big things that phonology is concerned with is the distribution of allophones: that is, what phonetic environments each allophone appears in. The distribution of allophones is a key part of the mental grammar of each language — it’s something that all speakers know unconsciously.
Some allophones appear in free variation, which means that it’s pretty much random which variant appears in any environment. But most allophones are entirely predictable: linguists say that allophonic variation is phonetically conditioned because it depends on what other sounds are nearby within the word.
Let’s start by looking at free variation because it’s the simpler case. Take our phoneme /l/, as in the words lucky and lunch. Most of the time you pronounce these words with a plain old ordinary voiced alveolar lateral approximant. But sometimes you might be speaking extra clearly — maybe you’re trying to talk to a relative who’s hard of hearing, or maybe you’re concentrating on teaching some speech sounds to a language learner. So instead of making the /l/ sound at the alveolar ridge, you stick your tongue right out between your teeth and say lucky or lunch. Now you’re making a dental [l̪], not an alveolar [l], but it’s still a member of the phoneme category for /l/ — it doesn’t change the meaning of the word so this phonetic difference is not contrastive. It’s just free variation within the category.
But most allophonic variation is predictable: different allophones show up in different environments. Let’s look at a few words. If we look at this set of words: plow, clap, clear, play, we can see that whenever /l/ follows a [p] or [k], it is devoiced. But now look at this other set of words (blue, gleam, leaf, fall, silly), when /l/ appears in any other environment, like following a voiced stop, or at the beginning of a word, at the end of a word, or in the middle of a word, it’s the ordinary [l]. If we looked at a whole lot more words and recorded a lot of English speakers, we’d find that whenever /l/ is in a consonant cluster following a voiceless aspirated stop, it also becomes voiceless, but when /l/ is in other environments, it stays voiced. We never find voiceless [l̥] in other environments, and we almost never find voiced [l] following a voiceless stop. That pattern is called complementary distribution.
That’s an important phrase, and it’s going to come up a lot in the next few units. It means that there’s no overlap in where we find the allophones: We see voiceless [l̥] following voiceless stops, but never anywhere else, and we never see voiced [l] in that environment. Likewise, we see voiced [l] in lots of different environments, but we never see voiceless [l̥] in any of those places. When we see complementary distribution, that’s good evidence that the two segments we’re considering are allophones of one phoneme. Can you think of any other examples of English phonetic segments that are in complementary distribution? Think about what happens when you’re transcribing voiceless stops.
So let’s sum up. If we have two phonetic segments that are related but different from each other, and we find some minimal pairs to show that this phonetic difference is contrastive, then we conclude that those two segments are two different phonemes.
And if we have two phonetic segments that are related but different, and they’re not contrastive, then we look to see what the distribution of these segments is, that is, what environments we see them in. If they’re not contrastive and they’re in complementary distribution, then we conclude that they’re allophones of the same phoneme.
Check Yourself
- Answer
-
"Complementary distribution"
Hint: This describes a scenario where a sound only occurs in a specific environment, and that if you swapped it with the other 'option' or 'variant' it wouldn't change the meaning.
- Answer
-
"[l] and [l̴] are in complementary distribution in English."
Hint: This describes a scenario where a sound only occurs in a specific environment, and that if you swapped it with the other 'option' or 'variant' it wouldn't change the meaning.
3.1.3: From 4.3 Phonetic Segments and Features, in Anderson's Essentials of Linguistics
Video Script
In our thinking about speech sounds so far, we’ve focused almost entirely on segments. Segments are the individual speech sounds, each of which gets transcribed with an individual symbol in the IPA. We’ve seen that any given segment can influence the segments that come before and after it, through coarticulation and other articulatory processes. And we’ve also seen that segments can be grouped together into syllables, which we look at in more detail in another unit. Within the grammar of any language, two different segments might contrast with each other or might not.
So we’ve been talking as if segments are the smallest unit in speech, but in fact, each speech segment is made up of smaller components called features. Each feature is an element of a sound that we can control independently. To see how features work, let’s look at a couple of examples. We can describe the segment [b], for example, as being made up of this set of features. First, [b] is a consonant (meaning it has some obstruction in the vocal tract), so it gets the feature consonant indicated with a plus sign to show that the consonant feature is present. Looking at the next feature, sonorant, notice that it’s indicated with a minus sign, meaning that [b] is not a sonorant. The feature sonorant, of course, has to do with sonority. We know that stops have very low sonority because the vocal tract is completely closed for stops, so stops are all coded as [-sonorant]. The next feature, syllabic, tells us whether a given segment is the nucleus of a syllable or not. Remember that the most common segments that serve as the nucleus of a syllable are vowels, but stops certainly cannot be the nucleus, so [b] gets labelled as [-syllabic]. These first three features, consonant, sonorant, and syllabic allow us to group all speech segments into the major classes of consonants, vowels, and glides. We’ll see how in a couple of minutes.
This next set of features has to do with the manner of articulation. The feature continuant tells us how long a sound goes on. Stops are very short sounds; they last for only a brief moment, so [b] gets a minus sign for continuant. We also know that [b] is not made by passing air through the nasal cavity, so it also gets a minus sign for the feature nasal. And [b] is a voiced sound, made with vocal folds vibrating, so it is [+voice].
The last feature we list for [b] is [LABIAL] because it’s made with the lips. (Stay tuned for an explanation of why some features are listed in lower-case and some in upper-case.)
This whole list of features is called a feature matrix; it’s the list of the individual features that describe the segment [b], in quite a lot of detail! Because features are at the phonetic level of representation, we use square brackets when we list them. You often see a feature matrix listed with a large pair of square brackets, like this, but we’ll just use individual square brackets on each feature.
Now I want you to notice something. If we take this whole feature matrix and change the value of just one feature, changing the feature voice from plus to minus, now we’re describing a different segment, [p]: [p] has every feature in common with [b] except for voicing. Likewise, if we take the feature matrix for [b] and change the value of the feature continuant from minus to plus, now we’re describing the segment [v], which has all the same features as [b] except that it can continue for a long time because it’s a fricative. Or if we take the feature matrix for [b] and change the feature nasal from minus to plus, this has the effect of also changing the sonorant feature to plus as well, because circulating air through the nasal cavity adds sonority. Now, this feature matrix describes the properties of the segment [m].
So each feature is something that we can control independently of the others with our articulators. And changing just one feature is enough to change the properties of a segment. That change might lead to a phonemic contrast within the mental grammar of a language, or it might just result in an allophone of the same phoneme.
It turns out that segments that have a lot of features in common tend to behave the same way within the mental grammar of a language. And we can use these features to group segments into natural classes that capture some of these similarities in their behaviour.
Let’s look again at the feature matrix for [b]. If we take away the feature that describes its place of articulation, we end up with a smaller list of features. This smaller list describes not just a single segment, but a class of segments: all the voiced stops. By not mentioning the place feature, we’ve allowed this matrix to include segments from any place of articulation, as long as they share all these other features. These three segments have all these features in common: they’re a natural class. If we remove another feature, the voicing feature, the natural class gets bigger: now we’ve got a feature matrix that describes all the stops in English, including those that are [+voice] and those that are [-voice]. So you can see that this system of features is very powerful for describing classes of segments that have things in common. We’ll learn more about natural classes in the next unit.
Check Yourself
- Answer
-
"[consonant]"
Hint: One is on the consonant chart, the other is on the vowel chart.
- Answer
-
"[continuant]"
Hint: [p] is a stop, meaning that the airflow is stopped. [f] is a fricative, meaning that the airflow is continuous.
- Answer
-
"[voice]"
Hint: These sounds are the same, just that one has the vocal cords moving/vibrating.
3.1.4: From 4.5 Phonological Derivations, in Anderson's Essentials of Linguistics
Video Script
Earlier in this chapter, we talked about the difference between phonemic and phonetic representations. Remember that when we talk about a phonemic representation, we’re referring to how a sound or a word is represented in our mind. At the phonemic level, the mind stores segmental information, but not details about allophonic variation. But the phonetic representation is how we actually speak words, and because of coarticulation and various articulatory processes, when we speak a given phoneme, it gets produced as the particular allophone that’s conditioned by the surrounding environment. For example, the word clean is represented phonemically like this /klin/ in our minds but when we speak, these particular phonetic details [khl̥in] are part of what we say. We speak in allophones but we hear in phonemes.
The systematic, predictable relationship between the phonemic and phonetic representations is part of the mental grammar of every fluent speaker of a language. Phonologists have developed a notation for depicting this relationship, which is sometimes known as a derivation or a rule. Remember of course that when we talk about rules in linguistics, we don’t mean those prescriptive rules that your high school English teacher wanted you to follow. We mean the principles that our mental grammar uses to link the underlying phonemic representation to the surface form. Our mental grammar keeps track of every predictable phonetic change that happens to a given natural class of sounds in a given phonetic environment.
Let’s think about that now familiar process of liquid devoicing. We’ve seen lots of English examples like clean where the voiced [l] becomes voiceless following the voiceless [kh] because of perseveratory assimilation. In fact, we’ve seen enough data from English to observe that this doesn’t just happen to one segment; it happens to the natural class of liquids in the environment of another natural class: voiceless stops.
The way that we write a derivation takes a particular form that looks like this. This notation is read as “A becomes B in the environment between X and Y”. The left side represents the phonetic change that happens: a particular phoneme or natural class of phonemes becomes a given allophone or undergoes a change to one or more features. The right-hand side shows the phonetic environment that the change occurs in.
So how would we use this notation to represent the predictable process of liquid devoicing? Let’s start by describing the pattern in words. The change happens to the liquids [l] and [ɹ]. What happens to them is that they go from voiced to voiceless. And where it happens is following voiceless stops. So now let’s describe the pattern using a feature matrix.
We start with the feature matrix for the liquids. They’re consonants that are sonorant but not nasal and by default, they’re [+voice]. The change that happens is that their voice feature goes from plus to minus. The other features stay the same so we don’t list them in the feature matrix that describes the change.
Now we have to say where this change happens. The big slash just means “in the environment” and we know that this change happens following something, so we put the horizontal line that indicates the location of the change following the feature matrix that represents the environment and then we fill in the details of the particular environment. Voiceless stops are consonants that are [-continuant] and [-voice].
We could say that [l] becomes voiceless [l] in the environment following [p] or [k] and [ɹ] becomes voiceless [ɹ] in the environment following [p] or [t] or [k] but using feature matrices captures the broader generalization that this allophonic variation happens to an entire natural class in the environment of another natural class.
Check Yourself
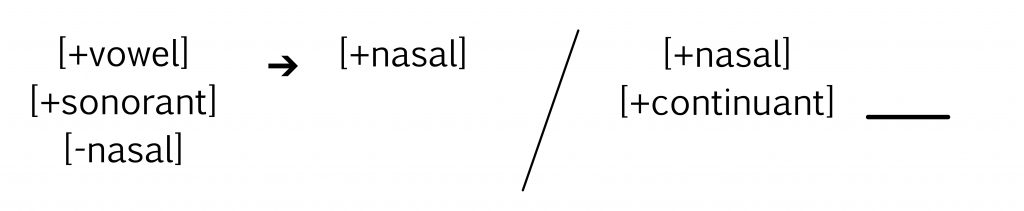
- Answer
-
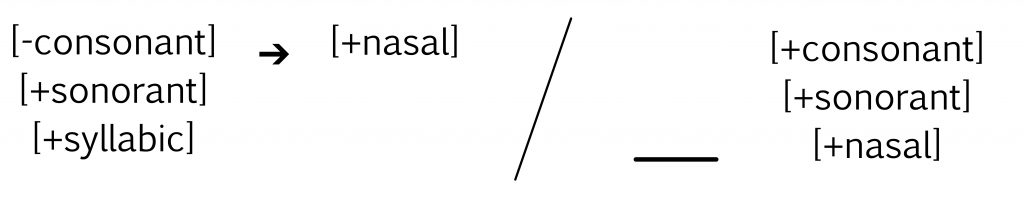
Hint: Look for the attribute [+nasal] in the right-most portion of the equation.

- Answer
-
"Voiceless fricatives become voiced between voiced sonorants."
Hint: Look for the attribute [+continuant] in the left-most portion of the equation.

- Answer
-
"The segment [ə] is epenthesized following a strident consonant."
Hint: The left-most element of the equation is a 'null', meaning that you're starting with nothing in that position.