
6.2: The Standard Normal Distribution
- Page ID
- 19059

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Z-Scores
The standard normal distribution is a normal distribution of standardized values called z-scores. A z-score is measured in units of the standard deviation.
Definition: Z-Score
If \(X\) is a normally distributed random variable and \(X \sim N(\mu, \sigma)\), then the z-score is:
\[z = \dfrac{x=\mu}{\sigma} \label{zscore}\]
The z-score tells you how many standard deviations the value \(x\) is above (to the right of) or below (to the left of) the mean, \(\mu\). Values of \(x\) that are larger than the mean have positive \(z\)-scores, and values of \(x\) that are smaller than the mean have negative \(z\)-scores. If \(x\) equals the mean, then \(x\) has a \(z\)-score of zero. For example, if the mean of a normal distribution is five and the standard deviation is two, the value 11 is three standard deviations above (or to the right of) the mean. The calculation is as follows:
\[ \begin{align*} x &= \mu + (z)(\sigma) \\[5pt] &= 5 + (3)(2) = 11 \end{align*}\]
The z-score is three.
Since the mean for the standard normal distribution is zero and the standard deviation is one, then the transformation in Equation \ref{zscore} produces the distribution \(Z \sim N(0, 1)\). The value \(x\) comes from a normal distribution with mean \(\mu\) and standard deviation \(\sigma\).
A z-score is measured in units of the standard deviation.
Example \(\PageIndex{1}\)
Suppose \(X \sim N(5, 6)\). This says that \(x\) is a normally distributed random variable with mean \(\mu = 5\) and standard deviation \(\sigma = 6\). Suppose \(x = 17\). Then (via Equation \ref{zscore}):
\[z = \dfrac{x-\mu}{\sigma} = \dfrac{17-5}{6} = 2 \nonumber\]
This means that \(x = 17\) is two standard deviations (2\(\sigma\)) above or to the right of the mean \(\mu = 5\). The standard deviation is \(\sigma = 6\).
Notice that: \(5 + (2)(6) = 17\) (The pattern is \(\mu + z \sigma = x\))
Now suppose \(x = 1\). Then:
\[z = \dfrac{x=\mu}{\sigma} = \dfrac{1-5}{6} = -0.67 \nonumber\]
(rounded to two decimal places)
This means that \(x = 1\) is \(0.67\) standard deviations (\(–0.67\sigma\)) below or to the left of the mean \(\mu = 5\). Notice that: \(5 + (–0.67)(6)\) is approximately equal to one (This has the pattern \(\mu + (–0.67)\sigma = 1\))
Summarizing, when \(z\) is positive, \(x\) is above or to the right of \(\mu\) and when \(z\) is negative, \(x\) is to the left of or below \(\mu\). Or, when \(z\) is positive, \(x\) is greater than \(\mu\), and when \(z\) is negative \(x\) is less than \(\mu\).
Exercise \(\PageIndex{1}\)
What is the \(z\)-score of \(x\), when \(x = 1\) and \(X \sim N(12, 3)\)?
- Answer
-
\(z = \dfrac{1-12}{3} \approx -3.67\)
Example \(\PageIndex{2}\)
Some doctors believe that a person can lose five pounds, on the average, in a month by reducing his or her fat intake and by exercising consistently. Suppose weight loss has a normal distribution. Let \(X =\) the amount of weight lost(in pounds) by a person in a month. Use a standard deviation of two pounds. \(X \sim N(5, 2)\). Fill in the blanks.
- Suppose a person lost ten pounds in a month. The \(z\)-score when \(x = 10\) pounds is \(x = 2.5\) (verify). This \(z\)-score tells you that \(x = 10\) is ________ standard deviations to the ________ (right or left) of the mean _____ (What is the mean?).
- Suppose a person gained three pounds (a negative weight loss). Then \(z =\) __________. This \(z\)-score tells you that \(x = -3\) is ________ standard deviations to the __________ (right or left) of the mean.
Answers
a. This \(z\)-score tells you that \(x = 10\) is 2.5 standard deviations to the right of the mean five.
b. Suppose the random variables \(X\) and \(Y\) have the following normal distributions: \(X \sim N(5, 6)\) and \(Y \sim N(2, 1)\). If \(x = 17\), then \(z = 2\). (This was previously shown.) If \(y = 4\), what is \(z\)?
\[z = \dfrac{y-\mu}{\sigma} = \dfrac{4-2}{1} = 2 \nonumber\]
where \(\mu = 2\) and \(\sigma = 1\).
The \(z\)-score for \(y = 4\) is \(z = 2\). This means that four is \(z = 2\) standard deviations to the right of the mean. Therefore, \(x = 17\) and \(y = 4\) are both two (of their own) standard deviations to the right of their respective means.
The z-score allows us to compare data that are scaled differently. To understand the concept, suppose \(X \sim N(5, 6)\) represents weight gains for one group of people who are trying to gain weight in a six week period and \(Y \sim N(2, 1)\) measures the same weight gain for a second group of people. A negative weight gain would be a weight loss. Since \(x = 17\) and \(y = 4\) are each two standard deviations to the right of their means, they represent the same, standardized weight gain relative to their means.
Exercise \(\PageIndex{2}\)
Fill in the blanks.
Jerome averages 16 points a game with a standard deviation of four points. \(X \sim N(16, 4)\). Suppose Jerome scores ten points in a game. The \(z\)–score when \(x = 10\) is \(-1.5\). This score tells you that \(x = 10\) is _____ standard deviations to the ______(right or left) of the mean______(What is the mean?).
- Answer
-
1.5, left, 16
The Empirical Rule
If \(X\) is a random variable and has a normal distribution with mean \(\mu\) and standard deviation \(\sigma\), then the Empirical Rule says the following:
- About 68% of the \(x\) values lie between –1\(\sigma\) and +1\(\sigma\) of the mean \(\mu\) (within one standard deviation of the mean).
- About 95% of the \(x\) values lie between –2\(\sigma\) and +2\(\sigma\) of the mean \(\mu\) (within two standard deviations of the mean).
- About 99.7% of the \(x\) values lie between –3\(\sigma\) and +3\(\sigma\) of the mean \(\mu\) (within three standard deviations of the mean). Notice that almost all the \(x\) values lie within three standard deviations of the mean.
- The \(z\)-scores for +1\(\sigma\) and –1\(\sigma\) are +1 and –1, respectively.
- The \(z\)-scores for +2\(\sigma\) and –2\(\sigma\) are +2 and –2, respectively.
- The \(z\)-scores for +3\(\sigma\) and –3\(\sigma\) are +3 and –3 respectively.
The empirical rule is also known as the 68-95-99.7 rule.
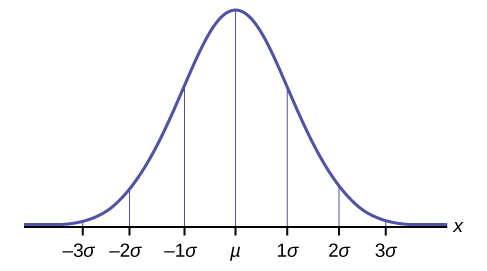
Figure \(\PageIndex{1}\)
Example \(\PageIndex{3}\)
The mean height of 15 to 18-year-old males from Chile from 2009 to 2010 was 170 cm with a standard deviation of 6.28 cm. Male heights are known to follow a normal distribution. Let \(X =\) the height of a 15 to 18-year-old male from Chile in 2009 to 2010. Then \(X \sim N(170, 6.28)\).
- Suppose a 15 to 18-year-old male from Chile was 168 cm tall from 2009 to 2010. The \(z\)-score when \(x = 168\) cm is \(z =\) _______. This \(z\)-score tells you that \(x = 168\) is ________ standard deviations to the ________ (right or left) of the mean _____ (What is the mean?).
- Suppose that the height of a 15 to 18-year-old male from Chile from 2009 to 2010 has a \(z\)-score of \(z = 1.27\). What is the male’s height? The \(z\)-score (\(z = 1.27\)) tells you that the male’s height is ________ standard deviations to the __________ (right or left) of the mean.
Answers
- –0.32, 0.32, left, 170
- 177.98, 1.27, right
Exercise \(\PageIndex{3}\)
Use the information in Example \(\PageIndex{3}\) to answer the following questions.
- Suppose a 15 to 18-year-old male from Chile was 176 cm tall from 2009 to 2010. The \(z\)-score when \(x = 176\) cm is \(z =\) _______. This \(z\)-score tells you that \(x = 176\) cm is ________ standard deviations to the ________ (right or left) of the mean _____ (What is the mean?).
- Suppose that the height of a 15 to 18-year-old male from Chile from 2009 to 2010 has a \(z\)-score of \(z = –2\). What is the male’s height? The \(z\)-score (\(z = –2\)) tells you that the male’s height is ________ standard deviations to the __________ (right or left) of the mean.
- Answer
-
Solve the equation \(z = \dfrac{x-\mu}{\sigma}\) for \(z\). \(x = \mu+ (z)(\sigma)\)
\(z = \dfrac{176-170}{6.28}\), This z-score tells you that \(x = 176\) cm is 0.96 standard deviations to the right of the mean 170 cm.
- Answer
-
Solve the equation \(z = \dfrac{x-\mu}{\sigma}\) for \(z\). \(x = \mu+ (z)(\sigma)\)
\(X = 157.44\) cm, The \(z\)-score(\(z = –2\)) tells you that the male’s height is two standard deviations to the left of the mean.
Example \(\PageIndex{4}\)
From 1984 to 1985, the mean height of 15 to 18-year-old males from Chile was 172.36 cm, and the standard deviation was 6.34 cm. Let \(Y =\) the height of 15 to 18-year-old males from 1984 to 1985. Then \(Y \sim N(172.36, 6.34)\).
The mean height of 15 to 18-year-old males from Chile from 2009 to 2010 was 170 cm with a standard deviation of 6.28 cm. Male heights are known to follow a normal distribution. Let \(X =\) the height of a 15 to 18-year-old male from Chile in 2009 to 2010. Then \(X \sim N(170, 6.28)\).
Find the z-scores for \(x = 160.58\) cm and \(y = 162.85\) cm. Interpret each \(z\)-score. What can you say about \(x = 160.58\) cm and \(y = 162.85\) cm?
Answer
- The \(z\)-score (Equation \ref{zscore}) for \(x = 160.58\) is \(z = –1.5\).
- The \(z\)-score for \(y = 162.85\) is \(z = –1.5\).
Both \(x = 160.58\) and \(y = 162.85\) deviate the same number of standard deviations from their respective means and in the same direction.
Exercise \(\PageIndex{4}\)
In 2012, 1,664,479 students took the SAT exam. The distribution of scores in the verbal section of the SAT had a mean \(\mu = 496\) and a standard deviation \(\sigma = 114\). Let \(X =\) a SAT exam verbal section score in 2012. Then \(X \sim N(496, 114)\).
Find the \(z\)-scores for \(x_{1} = 325\) and \(x_{2} = 366.21\). Interpret each \(z\)-score. What can you say about \(x_{1} = 325\) and \(x_{2} = 366.21\)?
- Answer
-
The z-score (Equation \ref{zscore}) for \(x_{1} = 325\) is \(z_{1} = –1.14\).
The z-score (Equation \ref{zscore}) for \(x_{2} = 366.21\) is \(z_{2} = –1.14\).
Student 2 scored closer to the mean than Student 1 and, since they both had negative \(z\)-scores, Student 2 had the better score.
Example \(\PageIndex{5}\)
Suppose \(x\) has a normal distribution with mean 50 and standard deviation 6.
- About 68% of the \(x\) values lie between \(-1\sigma\) = (-1)(6) = -6\) and \(1 \sigma = (1)(6) = 6\) of the mean 50. The values \(50 - 6 = 44\) and \(50 + 6 = 56\) are within one standard deviation of the mean 50. The \(z\)-scores are –1 and +1 for 44 and 56, respectively.
- About 95% of the \(x\) values lie between \(-2 \sigma = (–2)(6) = –12\) and \(2 \sigma = (2)(6) = 12\). The values \(50 – 12 = 38\) and \(50 + 12 = 62\) are within two standard deviations of the mean 50. The \(z\)-scores are –2 and +2 for 38 and 62, respectively.
- About 99.7% of the \(x\) values lie between \(–3 \sigma = (–3)(6) = –18\) and \(3 \sigma = (3)(6) = 18\) of the mean 50. The values \(50 – 18 = 32\) and \(50 + 18 = 68\) are within three standard deviations of the mean 50. The \(z\)-scores are –3 and +3 for 32 and 68, respectively.
Exercise \(\PageIndex{5}\)
Suppose \(X\) has a normal distribution with mean 25 and standard deviation five. Between what values of \(x\) do 68% of the values lie?
- Answer
-
between 20 and 30.
Example \(\PageIndex{6}\)
From 1984 to 1985, the mean height of 15 to 18-year-old males from Chile was 172.36 cm, and the standard deviation was 6.34 cm. Let \(Y =\) the height of 15 to 18-year-old males in 1984 to 1985. Then \(Y \sim N(172.36, 6.34)\).
- About 68% of the \(y\) values lie between what two values? These values are ________________. The \(z\)-scores are ________________, respectively.
- About 95% of the \(y\) values lie between what two values? These values are ________________. The \(z\)-scores are ________________ respectively.
- About 99.7% of the \(y\) values lie between what two values? These values are ________________. The \(z\)-scores are ________________, respectively.
Answer
- About 68% of the values lie between 166.02 and 178.7. The \(z\)-scores are –1 and 1.
- About 95% of the values lie between 159.68 and 185.04. The \(z\)-scores are –2 and 2.
- About 99.7% of the values lie between 153.34 and 191.38. The \(z\)-scores are –3 and 3.
Exercise \(\PageIndex{6}\)
The scores on a college entrance exam have an approximate normal distribution with mean, \(\mu = 52\) points and a standard deviation, \(\sigma = 11\) points.
- About 68% of the \(y\) values lie between what two values? These values are ________________. The \(z\)-scores are ________________, respectively.
- About 95% of the \(y\) values lie between what two values? These values are ________________. The \(z\)-scores are ________________, respectively.
- About 99.7% of the \(y\) values lie between what two values? These values are ________________. The \(z\)-scores are ________________, respectively.
- Answer a
-
About 68% of the values lie between the values 41 and 63. The \(z\)-scores are –1 and 1, respectively.
- Answer b
-
About 95% of the values lie between the values 30 and 74. The \(z\)-scores are –2 and 2, respectively.
- Answer c
-
About 99.7% of the values lie between the values 19 and 85. The \(z\)-scores are –3 and 3, respectively.
Summary
A \(z\)-score is a standardized value. Its distribution is the standard normal, \(Z \sim N(0, 1)\). The mean of the \(z\)-scores is zero and the standard deviation is one. If \(y\) is the z-score for a value \(x\) from the normal distribution \(N(\mu, \sigma)\) then \(z\) tells you how many standard deviations \(x\) is above (greater than) or below (less than) \(\mu\).
Formula Review
\(Z \sim N(0, 1)\)
\(z = a\) standardized value (\(z\)-score)
mean = 0; standard deviation = 1
To find the \(K\)th percentile of \(X\) when the \(z\)-scores is known:
\(k = \mu + (z)\sigma\)
\(z\)-score: \(z = \dfrac{x-\mu}{\sigma}\)
\(Z =\) the random variable for z-scores
\(Z \sim N(0, 1)\)
Glossary
- Standard Normal Distribution
- a continuous random variable (RV) \(X \sim N(0, 1)\); when \(X\) follows the standard normal distribution, it is often noted as \(Z \sim N(0, 1)\.
- \(z\)-score
- the linear transformation of the form \(z = \dfrac{x-\mu}{\sigma}\); if this transformation is applied to any normal distribution \(X \sim N(\mu, \sigma\) the result is the standard normal distribution \(Z \sim N(0,1)\). If this transformation is applied to any specific value \(x\) of the RV with mean \(\mu\) and standard deviation \(\sigma\), the result is called the \(z\)-score of \(x\). The \(z\)-score allows us to compare data that are normally distributed but scaled differently.
References
- “Blood Pressure of Males and Females.” StatCruch, 2013. Available online at http://www.statcrunch.com/5.0/viewre...reportid=11960 (accessed May 14, 2013).
- “The Use of Epidemiological Tools in Conflict-affected populations: Open-access educational resources for policy-makers: Calculation of z-scores.” London School of Hygiene and Tropical Medicine, 2009. Available online at http://conflict.lshtm.ac.uk/page_125.htm (accessed May 14, 2013).
- “2012 College-Bound Seniors Total Group Profile Report.” CollegeBoard, 2012. Available online at http://media.collegeboard.com/digita...Group-2012.pdf (accessed May 14, 2013).
- “Digest of Education Statistics: ACT score average and standard deviations by sex and race/ethnicity and percentage of ACT test takers, by selected composite score ranges and planned fields of study: Selected years, 1995 through 2009.” National Center for Education Statistics. Available online at http://nces.ed.gov/programs/digest/d...s/dt09_147.asp (accessed May 14, 2013).
- Data from the San Jose Mercury News.
- Data from The World Almanac and Book of Facts.
- “List of stadiums by capacity.” Wikipedia. Available online at https://en.wikipedia.org/wiki/List_o...ms_by_capacity (accessed May 14, 2013).
- Data from the National Basketball Association. Available online at www.nba.com (accessed May 14, 2013).