
15.5: Test of Two Variances
- Page ID
- 19151

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Another of the uses of the \(F\) distribution is testing two variances. It is often desirable to compare two variances rather than two averages. For instance, college administrators would like two college professors grading exams to have the same variation in their grading. In order for a lid to fit a container, the variation in the lid and the container should be the same. A supermarket might be interested in the variability of check-out times for two checkers.
to perform a \(F\) test of two variances, it is important that the following are true:
- The populations from which the two samples are drawn are normally distributed.
- The two populations are independent of each other.
Unlike most other tests in this book, the \(F\) test for equality of two variances is very sensitive to deviations from normality. If the two distributions are not normal, the test can give higher \(p\text{-values}\) than it should, or lower ones, in ways that are unpredictable. Many texts suggest that students not use this test at all, but in the interest of completeness we include it here.
Suppose we sample randomly from two independent normal populations. Let \(\sigma^{2}_{1}\) and \(\sigma^{2}_{2}\) be the population variances and \(s^{2}_{1}\) and \(s^{2}_{2}\) be the sample variances. Let the sample sizes be \(n_{1}\) and \(n_{2}\). Since we are interested in comparing the two sample variances, we use the \(F\) ratio:
\[F = \dfrac{\left[\dfrac{(s_{1})^{2}}{(\sigma_{1})^{2}}\right]}{\left[\dfrac{(s_{2})^{2}}{(\sigma_{2})^{2}}\right]}\]
\(F\) has the distribution
\[F \sim F(n_{1} - 1, n_{2} - 1)\]
where \(n_{1} - 1\) are the degrees of freedom for the numerator and \(n_{2} - 1\) are the degrees of freedom for the denominator.
If the null hypothesis is \(\sigma^{2}_{1} = \sigma^{2}_{2}\), then the \(F\) Ratio becomes
\[F = \dfrac{\left[\dfrac{(s_{1})^{2}}{(\sigma_{1})^{2}}\right]}{\left[\dfrac{(s_{2})^{2}}{(\sigma_{2})^{2}}\right]} = \dfrac{(s_{1})^{2}}{(s_{2})^{2}}.\]
The \(F\) ratio could also be \(\dfrac{(s_{2})^{2}}{(s_{1})^{2}}\). It depends on \(H_{a}\) and on which sample variance is larger.
If the two populations have equal variances, then \(s^{2}_{1}\) and \(s^{2}_{2}\) are close in value and \(F = \dfrac{(s_{1})^{2}}{(s_{2})^{2}}\) is close to one. But if the two population variances are very different, \(s^{2}_{1}\) and \(s^{2}_{2}\) tend to be very different, too. Choosing \(s^{2}_{1}\) as the larger sample variance causes the ratio \(\dfrac{(s_{1})^{2}}{(s_{2})^{2}}\) to be greater than one. If \(s^{2}_{1}\) and \(s^{2}_{2}\) are far apart, then
\[F = \dfrac{(s_{1})^{2}}{(s_{2})^{2}}\]
is a large number.
Therefore, if \(F\) is close to one, the evidence favors the null hypothesis (the two population variances are equal). But if \(F\) is much larger than one, then the evidence is against the null hypothesis. A test of two variances may be left, right, or two-tailed.
A test of two variances may be left, right, or two-tailed.
Example \(\PageIndex{1}\)
Two college instructors are interested in whether or not there is any variation in the way they grade math exams. They each grade the same set of 30 exams. The first instructor's grades have a variance of 52.3. The second instructor's grades have a variance of 89.9. Test the claim that the first instructor's variance is smaller. (In most colleges, it is desirable for the variances of exam grades to be nearly the same among instructors.) The level of significance is 10%.
Answer
Let 1 and 2 be the subscripts that indicate the first and second instructor, respectively.
- \(n_{1} = n_{2} = 30\).
- \(H_{0}: \sigma^{2}_{1} = \sigma^{2}_{2}\) and \(H_{a}: \sigma^{2}_{1} < \sigma^{2}_{2}\)
Calculate the test statistic: By the null hypothesis \(\sigma^{2}_{1} = \sigma^{2}_{2})\), the \(F\) statistic is:
\[F = \dfrac{\left[\dfrac{(s_{1})^{2}}{(\sigma_{1})^{2}}\right]}{\left[\dfrac{(s_{2})^{2}}{(s_{2})^{2}}\right]} = \dfrac{(s_{1})^{2}}{(s_{2})^{2}} = \dfrac{52.3}{89.9} = 0.5818\]
Distribution for the test: \(F_{29,29}\) where \(n_{1} - 1 = 29\) and \(n_{2} - 1 = 29\).
Graph: This test is left tailed.
Draw the graph labeling and shading appropriately.
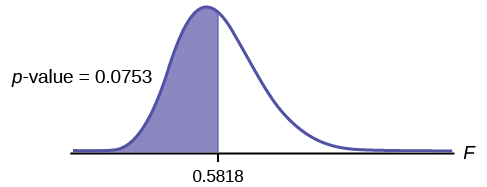
Figure \(\PageIndex{1}\)
Probability statement: \(p\text{-value} = P(F < 0.5818) = 0.0753\)
Compare \(\alpha\) and the \(p\text{-value}\): \(\alpha = 0.10 \alpha > p\text{-value}\).
Make a decision: Since \(\alpha > p\text{-value}\), reject \(H_{0}\).
Conclusion: With a 10% level of significance, from the data, there is sufficient evidence to conclude that the variance in grades for the first instructor is smaller.
Press STAT and arrow over to TESTS. Arrow down to D:2-SampFTest. Press ENTER. Arrow to Stats and press ENTER. For Sx1, n1, Sx2, and n2, enter (52.3)−−−−−√(52.3), 30, (89.9)−−−−−√(89.9), and 30. Press ENTER after each. Arrow to σ1: and <σ2. Press ENTER. Arrow down to Calculate and press ENTER. F = 0.5818 and p-value = 0.0753. Do the procedure again and try Draw instead of Calculate.
Exercise \(\PageIndex{1}\)
The New York Choral Society divides male singers up into four categories from highest voices to lowest: Tenor1, Tenor2, Bass1, Bass2. In the table are heights of the men in the Tenor1 and Bass2 groups. One suspects that taller men will have lower voices, and that the variance of height may go up with the lower voices as well. Do we have good evidence that the variance of the heights of singers in each of these two groups (Tenor1 and Bass2) are different?
| Tenor1 | Bass2 | Tenor 1 | Bass 2 | Tenor 1 | Bass 2 |
|---|---|---|---|---|---|
| 69 | 72 | 67 | 72 | 68 | 67 |
| 72 | 75 | 70 | 74 | 67 | 70 |
| 71 | 67 | 65 | 70 | 64 | 70 |
| 66 | 75 | 72 | 66 | 69 | |
| 76 | 74 | 70 | 68 | 72 | |
| 74 | 72 | 68 | 75 | 71 | |
| 71 | 72 | 64 | 68 | 74 | |
| 66 | 74 | 73 | 70 | 75 | |
| 68 | 72 | 66 | 72 |
Answer
The histograms are not as normal as one might like. Plot them to verify. However, we proceed with the test in any case.
Subscripts: \(\text{T1} =\) tenor 1 and \(\text{B2} =\) bass 2
The standard deviations of the samples are \(s_{\text{T1}} = 3.3302\) and \(s_{\text{B2}} = 2.7208\).
The hypotheses are
\(H_{0}: \sigma^{2}_{\text{T1}} = \sigma^{2}_{\text{B2}}\) and \(H_{0}: \sigma^{2}_{\text{T1}} \neq \sigma^{2}_{\text{B2}}\) (two tailed test)
The \(F\) statistic is \(1.4894\) with 20 and 25 degrees of freedom.
The \(p\text{-value}\) is \(0.3430\). If we assume alpha is 0.05, then we cannot reject the null hypothesis.
We have no good evidence from the data that the heights of Tenor1 and Bass2 singers have different variances (despite there being a significant difference in mean heights of about 2.5 inches.)
References
- “MLB Vs. Division Standings – 2012.” Available online at http://espn.go.com/mlb/standings/_/y...ion/order/true.
Chapter Review
The F test for the equality of two variances rests heavily on the assumption of normal distributions. The test is unreliable if this assumption is not met. If both distributions are normal, then the ratio of the two sample variances is distributed as an F statistic, with numerator and denominator degrees of freedom that are one less than the samples sizes of the corresponding two groups. A test of two variances hypothesis test determines if two variances are the same. The distribution for the hypothesis test is the \(F\) distribution with two different degrees of freedom.
Assumptions:
- The populations from which the two samples are drawn are normally distributed.
- The two populations are independent of each other.
Formula Review
\(F\) has the distribution \(F \sim F(n_{1} - 1, n_{2} - 1)\)
\(F = \dfrac{\dfrac{s^{2}_{1}}{\sigma^{2}_{1}}}{\dfrac{s^{2}_{2}}{\sigma^{2}_{2}}}\)
If \(\sigma_{1} = \sigma_{2}\), then \(F = \dfrac{s^{2}_{1}}{s^{2}_{2}}\)