
3.1: The scientific hypothesis
- Last updated
- Save as PDF
- Page ID
- 81909

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)At the end of the previous chapter, we defined corpus linguistics as “the investigation of linguistic research questions that have been framed in terms of the conditional distribution of linguistic phenomena in a linguistic corpus” and briefly discussed the individual steps necessary to conduct research on the basis of this discussion.
In this chapter, we will look in more detail at the logic and practice of formulating and testing research questions (Sections 3.1.1 and 3.1.2). We will then discuss the notion of operationalization in some detail (Section 3.2) before closing with some general remarks about the place of hypothesis testing in scientific research practice (Section 3.3).
3.1 The scientific hypothesis
Broadly speaking, there are two ways in which we can state our research question: first, in the form of an actual question such as “Is there a relationship between X and Y?” or “What is the relationship between X and Y?”; second, in the form of a specific hypothesis concerning the relationship between two variables, such as “all X are Y” or “X leads to Y”.
The first way entails a relatively open-minded approach to our data. We might have some general expectation of what we will find, but we would put them aside and simply start collecting observations and look for patterns. If we find such patterns, we might use them to propose a provisional generalization, which we successively confirm, modify or replace on the basis of additional observations until we are satisfied that we have found the broadest generalization that our data will allow – this will then be the answer to our research question.
This so-called inductive approach was famously rejected by the Austrian-British philosopher Karl Popper for reasons that will become clear below, but after a period of disrepute it has been making a strong comeback in many disciplines in recent years due to the increasing availability of massive amounts of data and of tools that can search for correlations in these data within a reasonable time frame (think of the current buzz word “big data”). Such massive amounts of data allow us to take an extremely inductive approach – essentially just asking “What relationships exist in my data?” – and still arrive at reliable generalizations. Of course, matters are somewhat more complex, since, as discussed at the end of the previous chapter, theoretical constructs cannot directly be read off our data. But the fact remains that, used in the right way, inductive research designs have their applications. In corpus linguistics, large amounts of data have been available for some time (as mentioned in the previous chapter, the size even of corpora striving for some kind of balance is approaching half-a-billion words), and inductive approaches are used routinely and with insightful consequences (Sinclair 1991 is an excellent example).
The second way of stating research questions entails a more focused way of approaching our data. We state our hypothesis before looking at any data, and then limit our observations just to those that will help us determine the truth of this hypothesis (which is far from trivial, as we will see presently). This so-called deductive approach is generally seen as the standard way of conducting research (at least ideally – actual research by actual people tends to be a bit messier even conceptually).
We will generally take a deductive approach in this book, but it will frequently include inductive (exploratory) excursions, as induction is a often useful in itself (for example, in situations where we do not know enough to state a useful working hypothesis or where our aim is mainly descriptive) or in the context of deductive research (where a first exploratory phase might involve inductive research as a way of generating hypotheses). We will see elements of inductive research in some of the case studies in Part II of this book.
3.1.1 Stating hypotheses
As indicated above, scientific hypotheses are typically statements relating two variables, but in order to understand what makes such statements special, let us take a step back and look at the simpler statement in (1):
(1) The English language has a word for the forward-facing window of a car.
Let us assume, for the moment, that we agree on the existence of something called car that has something accurately and unambiguously described by ‘forward-facing window’, and that we agree on the meaning of “English” and “language X has a word for Y”. How could we prove the statement in (1) to be true?
There is only one way: we have to find the word in question. We could, for example, describe the concept FORWARD-FACING WINDOW OF CAR to a native speaker or show them a picture of one, and ask them what it is called (a method used in traditional dialectology and field linguistics). Or we could search a corpus for all passages mentioning cars and hope that one of them mentions the forward-facing window; alternatively, we could search for grammatical contexts in which we might expect the word to be used, such as through the NOUN of POSS.PRON car (see Section 4.1 in Chapter 4 on how such a query would have to be constructed). Or we could check whether other people have already found the word, for example by searching the definitions of an electronic dictionary. If we find a word referring to the forward-facing window of a car, we have thereby proven its existence – we have verified the statement in (1).
But how could we falsify the statement, i.e., how could we prove that English does not have a word for the forward-facing window of a car? The answer is simple: we can’t. As discussed extensively in Chapter 1, both native-speaker knowledge and corpora are necessarily finite. Thus, if we ask a speaker to tell us what the forward-facing window of car is called and they don’t know, this may be because there is no such word, or because they do not know this word (for example, because they are deeply uninterested in cars). If we do not find a word in our corpus, this may be because there is no such word in English, or because the word just happens to be absent from our corpus, or because it does occur in the corpus but we missed it. If we do not find a word in our dictionary, this may be because there is no such word, or because the dictionary-makers failed to include it, or because we missed it (for example, because the definition is phrased so oddly that we did not think to look for it – as in the Oxford English Dictionary, which defines windscreen somewhat quaintly as “a screen for protection from the wind, now esp. in front of the driver’s seat on a motor-car” (OED, sv. windscreen)). No matter how extensively we have searched for something (e.g. a word for a particular concept), the fact that we have not found it does not mean that it does not exist.
The statement in (1) is a so-called “existential statement” (it could be rephrased as “There exists at least one x such that x is a word of English and x refers to the forward-facing window of a car”). Existential statements can (potentially) be verified, but they can never be falsified. Their verifiability depends on a crucial condition hinted at above: that all words used in the statement refer to entities that actually exist and that we agree on what these entities are. Put simply, the statement in (1) rests on a number of additional existential statements, such as “Languages exist”, “Words exist”, “At least one language has words”, “Words refer to things”, “English is a language”, etc.
There are research questions that take the form of existential statements. For example, in 2016 the astronomers Konstantin Batygin and Michael E. Brown proposed the existence of a ninth planet (tenth, if you cannot let go of Pluto) in our solar system (Batygin & Brown 2016). The existence of such a planet would explain certain apparent irregularities in the orbits of Kuiper belt objects, so the hypothesis is not without foundation and may well turn out to be true. However, until someone actually finds this planet, we have no reason to believe or not to believe that such a planet exists (the irregularities that Planet Nine is supposed to account for have other possible explanations, cf., e.g. Shankman et al. 2017). Essentially, its existence is an article of faith, something that should clearly be avoided in science.1
Nevertheless, existential statements play a crucial role in scientific enquiry – note that we make existential statements every time we postulate and define a construct. As pointed out above, the statement in (1) rests, for example, on the statement “Words exist”. This is an existential statement, whose precise content depends on how our model defines words. One frequently-proposed definition is that words are “the smallest units that can form an utterance on their own” (Matthews 2014: 436), so “Words exist” could be rephrased as “There is at least one x such that x can form an utterance on its own” (which assumes an additional existential statement defining utterance, and so on). In other words, scientific enquiry rests on a large number of existential statements that are themselves rarely questioned as long as they are useful in postulating meaningful hypotheses about our research objects.
But if scientific hypotheses are not (or only rarely) existential statements, what are they instead? As indicated at the end of the previous and the beginning of the current chapter, they are statements postulating relationships between constructs, rather than their existence. The minimal model within which such a hypothesis can be stated is visualized schematically in the cross table (or contingency table) in Table 3.1.
Table 3.1: A contingency table
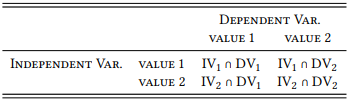
There must be (at least) two constructs, one of which we want to explain (the dependent variable), and one which we believe provides an explanation (the independent variable). Each variable has (at least) two values. The dimensions of the table represent the variables (with a loose convention to show the values of the independent variable in the table rows and the values of the dependent variables in the table columns, the cells represent all possible intersections (i.e., combinations) of their values (these are represented here, and on occasion in the remainder of the book, by the symbol ∩)).
The simplest cases of such hypotheses (in Popper’s view, the only legitimate case) are so-called universal statements. A text-book example of such a statement is All swans are white (Popper 1959), where the two constructs are ANIMAL, with the values SWAN and NON-SWAN and Color, with the values WHITE and NON-WHITE. The hypothesis All swans are white amounts to the prediction that the intersection SWAN ∩ WHITE exists, while the intersection SWAN ∩ NON-WHITE does not exist – it makes no predictions about the other two intersections. Our speculation concerning the distribution of the words windscreen and windshield, discussed in the previous chapter, essentially consists of the two universal statements, given in (2) and (3):
(2) All occurrences of the word windscreen are British English. (or, more formally, “For all x, if x is the word windscreen then x is (a word of) British English”)
(3) All occurrences of the word windshield are American English. (or, more formally, “For all x, if x is the word windshield then x is (a word of) American English”)
Note that the statements in (2) and (3) could be true or false independently of each other (and note also that we are assuming a rather simple model of English, with British and American English as the only varieties).
How would we test (either one or both of) these hypotheses? Naively, we might attempt to verify them, as we would in the case of existential statements. This attempt would be doomed, however, as Popper (1963) forcefully argues.
If we treat the statements in (2) and (3) analogously to the existential statement in (1), we might be tempted to look for positive evidence only, i.e., for evidence that appears to support the claim. For example, we might search a corpus of British English for instances of windscreen and a corpus of American English for instances of windshield. As mentioned at the end of the previous chapter, the corresponding quieries will indeed turn up cases of windscreen in British English and of windshield in American English.
If we were dealing with existential statements, this would be a plausible strategy and the results would tell us, that the respective words exist in the respective variety. However, with respect to the universal statements in (2) and (3), the results tell us nothing. Consider Table 3.2, which is a visual representation of the hypotheses in (2) and (3).
Table 3.2: A contingency table with binary values for the intersections
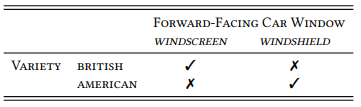
What we would have looked for in our naive attempt to verify our hypotheses are only those cases that should exist (i.e., the intersections indicated by checkmarks in Table 3.2). But if we find such examples, this does not tell us anything with respect to (2) and (3): we would get the same result if both words occur in both varieties. As Popper puts it, “[i]t is easy to obtain confirmations, or verifications, for nearly every theory [i.e., hypothesis, A.S.] – if we look for confirmations” (Popper 1963: 36).
Obviously, we also have to look for those cases that should not exist (i.e., the intersections indicated by crosses in Table 3.2): the prediction derived from (2) and (3) is that windscreen should occur exclusively in British English corpora and that windshield should occur exclusively in American English corpora.
Even if we approach our data less naively and find that our data conform fully to the hypothesized distribution in Table 3.2, there are two reasons why this does not count as verification.
First, the distribution could be due to some difference between the corpora other than the dialectal varieties they represent – it could, for example, be due to stylistic preferences of the authors, or the house styles of the publishing houses whose texts are included in the corpora. There are, after all, only a handful of texts in LOB and BROWN that mention either of the two words at all (three in each corpus).
Second, and more importantly, even if such confounding variables could be ruled out, no amount of data following the distribution in Table 3.2 could ever verify the hypotheses: no matter how many cases of windscreen we find in British but not American English and of windshield in American but not in British English, we can never conclude that the former cannot occur in American or the latter in British English. No matter how many observations we make, we cannot exclude the possibility that our next observation will be of the word windscreen in American English or of the word windshield in British English. This would be true even if we could somehow look at the entirety of British and American English at any given point in time, because new instances of the two varieties are being created all the time.
In other words, we cannot verify the hypotheses in (2) and (3) at all. In contrast, we only have to find a single example of windshield in British or windscreen in American English to falsify them. Universal statements are a kind of mirror-image of existential statements. We can verify the latter (in theory) by finding the entity whose existence we claim (such as Planet Nine in our solar system or a word for the forward-facing window of a car in English), but we cannot falsify them by not finding this entity. In contrast, we can falsify the former (in theory) by finding the intersection of values whose existence we deny (such as non-white swans or the word windscreen in American English), but we cannot verify them by finding intersections whose existence we affirm.
Thus, to test a scientific hypothesis, we have to specify cases that should not exist if the hypothesis were true, and then do our best to find such cases. As Popper puts it: “Every ‘good’ scientific theory is a prohibition: it forbids certain things to happen”, and “[e]very genuine test of a theory is an attempt to falsify it, or to refute it” (Popper 1963: 36).
The harder we try to find such cases but fail to do so, the more certain we can be that our hypothesis is correct. But no matter how hard we look, we must learn to accept that we can never be absolutely certain: in science, a “fact” is simply a hypothesis that has not yet been falsified. This may seem disappointing, but science has made substantial advances despite (or perhaps because) scientists accept that there is no certainty when it comes to truth. In contrast, a single counterexample will give us the certainty that our hypothesis is false. Incidentally, our attempts to falsify a hypothesis will often turn up evidence that appears to confirm it – for example, the more data we search in an attempt to find examples of the word windshield in British English, the more cases of windscreen we will come across. It would be strange to disregard this confirming evidence, and even Popper does not ask us to: however, he insists that in order to count as confirming evidence (or “corroborating evidence”, as he calls it), it must be the result of “a serious but unsuccessful attempt to falsify the theory” (Popper 1963: 36).
In our example, we would have to take the largest corpora of British and American English we can find and search them for counterexamples to our hypothesis (i.e., the intersections marked by crosses in Table 3.2). As long as we do not find them (and as long as we find corroborating evidence in the process), we are justified in assuming a dialectal difference, but we are never justified in claiming to have proven such a difference. Incidentally, we do indeed find such counterexamples in this case if we increase our samples: The 100-million word British National Corpus contains 33 cases of the word windshield (as opposed to 451 cases of windscreen), though some of them refer to forward-facing windows of aircraft rather than cars; conversely the 450-million-word Corpus of Current American English contains 205 cases of windscreen (as opposed to 2909 cases of windshield).
3.1.2 Testing hypotheses: From counterexamples to probabilities
We have limited the discussion of scientific hypotheses to the simple case of universal statements so far, and in the traditional Popperian philosophy of science, these are the only statements that truly qualify as scientific hypotheses. In corpus linguistics (and the social sciences more generally), hypotheses of this type are the exception rather than the norm – we are more likely to deal with statements about tendencies (think Most swans are white or Most examples of windscreen are British English), where the search for counterexamples is not a viable research strategy.
They may, however, inform corpus-based syntactic argumentation (cf. Meurers (2005), Meurers & Müller (2009), Noël (2003) for excellent examples of such studies, cf. also Case Study 8.2.7.1 in Chapter 8), and of course they have played a major role in traditional, intuition-based linguistic argumentation. Thus, a brief discussion of counterexamples will be useful both in its own right and in setting the stage for the discussion of hypotheses concerning tendencies. For expository reasons, I will continue to use the case of dialectal variation as an example, but the issues discussed apply to all corpus-linguistic research questions.
In the case of windscreen and windshield, we actually find counterexamples once we increase the sample size sufficiently, but there is still an overwhelming number of cases that follow our predictions. What do we make of such a situation?
Take another well-known lexical difference between British and American English: the distilled petroleum used to fuel cars is referred to as petrol in British English and gasoline in American English. A search in the four corpora used above yields the frequencies of occurrence shown in Table 3.3.
Table 3.3: Petrol vs. gasoline
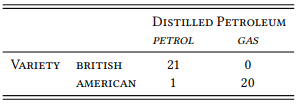
In other words, the distribution is almost identical to that for the words windscreen and windshield – except for one counterexample, where petrol occurs in the American part of the corpus (specifically, in the FROWN corpus). In other words, it seems that our hypothesis is falsified at least with respect to the word petrol. Of course, this is true only if we are genuinely dealing with a counterexample, so let us take a closer look at the example in question, which turns out to be from the novel Eye of the Storm by Jack Higgins:
(4) He was in Dorking within half an hour. He passed straight through and continued toward Horsham, finally pulling into a petrol station about five miles outside. (Higgins, Eye of the Storm)
Now, Jack Higgins is a pseudonym used by the novelist Harry Patterson for some of his novels – and Patterson is British (he was born in Newcastle upon Tyne and grew up in Belfast and Leeds). In other words, his novel was erroneously included in the FROWN corpus, presumably because it was published by an American publisher. Thus, we can discount the counterexample and maintain our original hypothesis. Misclassified data are only one reason to discount a counterexample, other reasons include intentional deviant linguistic behavior (for example, an American speaker may imitate a British speaker or a British speaker may have picked up some American vocabulary on a visit to the United States); a more complex reason is discussed below.
Note that there are two problems with the strategy of checking counterexamples individually to determine whether they are genuine counterexample or not. First, we only checked the example that looked like a counterexample – we did not check all the examples that fit our hypothesis. However, these examples could, of course, also contain cases of misclassified data, which would lead to additional counterexamples. Of course, we could theoretically check all examples, as there are only 42 examples overall. However, the larger our corpus is (and most corpus-linguistic research requires corpora that are much larger than the four million words used here), the less feasible it becomes to do so.
The second problem is that we were lucky, in this case, that the counterexample came from a novel by a well-known author, whose biographical information is easily available. But linguistic corpora do not (and cannot) contain only well-known authors, and so checking the individual demographic data for every speaker in a corpus may be difficult to impossible. Finally, some language varieties cannot be attributed to a single speaker at all – political speeches are often written by a team of speech writers that may or may not include the person delivering the speech, newspaper articles may include text from a number of journalists and press agencies, published texts in general are typically proof-read by people other than the author, and so forth.
Let us look at a more complex example, the words for the (typically elevated) paved path at the side of a road provided for pedestrians. Dictionaries typically tell us, that this is called pavement in British English and sidewalk in American English, for example, the OALD:
(5) a. pavement noun [...]
1 [countable] (British English) (North American English sidewalk) a flat part at the side of a road for people to walk on [OALD]
b. sidewalk noun [...]
(North American English) (British English pavement) a flat part at the side of a road for people to walk on [OALD]
A query for the two words (in all their potential morphological and orthographic variants) against the LOB and FLOB corpora (British English) and BROWN and FROWN corpora (American English) yields the results shown in Table 3.4.
Table 3.4: Pavement vs. sidewalk
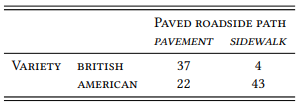
In this case, we are not dealing with a single counterexample. Instead, there are four apparent counterexamples where sidewalk occurs in British English, and 22 apparent counterexamples where pavement occurs in American English.
In the case of sidewalk, it seems at least possible that a closer inspection of the four cases in British English would show them to be only apparent counterexamples, due, for example, to misclassified texts. In the case of the 22 cases of pavement in American English, this is less likely. Let us look at both cases in turn.
Here are all four examples of sidewalk in British English, along with their author and title of the original source as quoted in the manuals of the corresponding corpora:
(6) a. One persistent taxi follows him through the street, crawling by the sidewalk...
(LOB E09: Wilfrid T. F. Castle, Stamps of Lebanon’s Dog River)
b. “Keep that black devil away from Rusty or you’ll have a sick horse on your hands,” he warned, and leaped to the wooden sidewalk.
(LOB N07: Bert Cloos, Drury)
c. There was a small boy on the sidewalk selling melons.
(FLOB K24: Linda Waterman, Bad Connection.)
d. Joe, my love, the snowflakes fell on the sidewalk.
(FLOB K25: Christine McNeill, The Lesson.)
Not much can be found about Wilfrid T.F. (Thomas Froggatt) Castle, other than that he wrote several books about postal stamps and about history, including the history of English parish churches, all published by British publishers. There is a deceased estate notice under the name Wilfrid Thomas Froggatt Castle that gives his last address in Somerset (The Stationery Office 1999). If this is the same person, it seems likely that he was British and that (6a) is a genuinely British English use of sidewalk.
Bert Cloos is the author of a handful of western novels with titles like Sangre India, Skirmish and Injun Blood. Again, very little can be found out about him, but he is mentioned in the Los Angeles Times from May 2, 1963 (p. 38), which refers to him as “Bert Cloos of Encinitas”. Since Encinitas is in California, Bert Cloos may, in fact, be an American author who ended up in the LOB by mistake – but, of course, Brits may also live in California, so there is no way of determining this. Clearly, though, the novels in question are all set in the US, so whether Cloos is American or not, he is presumably using American English in (6b) above.
For the authors of (6c, d), Linda Waterman and Christine McNeill, no biographical information can be found at all. Waterman’s story was published in a British student magazine, but this in itself is no evidence of anything. The story is set in Latin America, so there may be a conscious effort to evoke American English. In McNeill’s case there is some evidence that she is British: she uses some words that are typically British, such as dressing gown (AmE (bath)robe) and breadbin (AmE breadbox), so it is plausible that she is British. Like Waterman’s story, hers was published in a British magazine. Interestingly, however, the scene in which the word is used is set in the United States, so she, too, might be consciously evoking American English. To sum up, we have one example that was likely produced by an American speaker, and three that were likely produced by British speakers, although two of these were probably evoking American English. Which of these examples we may safely discount, however, remains difficult to say.
Turning to pavement in American English, it would be possible to check the origin of the speakers of all 22 cases with the same attention to detail, but it is questionable that the results would be worth the time invested: as pointed out, it is unlikely that there are so many misclassified examples in the American corpora.
On closer inspection, however, it becomes apparent that we may be dealing with a different type of exception here: the word pavement has additional senses to the one cited in (5a) above, one of which does exist in American English. Here is the remainder of the relevant dictionary entry:
(7) a. 2 [countable, uncountable] (British English) any area of flat stones on the ground
b. 3 [uncountable] (North American English) the surface of a road (OALD)
Since neither of these meanings is relevant for the issue of British and American words for pedestrian paths next to a road, they cannot be treated as counterexamples in our context. In other words, we have to look at all hits for pavement and annotate them for their appropriate meaning. This in itself is a non-trivial task, which we will discuss in more detail in Chapters 4 and 5. Take the example in (8):
(8) [H]e could see the police radio car as he rounded the corner and slammed on the brakes. He did not bother with his radio – there would be time for that later – but as he scrambled out on the pavement he saw the filling station and the public telephone booth ... (BROWN L 18)
Even with quite a large context, this example is compatible with a reading of pavement as ‘road surface’ or as ‘pedestrian path’. If it came from a British text, we would not hesitate to assign the latter reading, but since it comes from an American text (the novel Error of Judgment by the American author George Harmon Coxe), we might lean towards erring on the side of caution and annotate it as ‘road surface’. Alas, the side of “caution” here is the side suggested by the very hypothesis we are trying to falsify – we would be basing our categorization circularly on what we are expecting to find in the data.
A more intensive search of novels by American authors in the Google Books archive (which is larger than the BROWN corpus by many orders of magnitude), turns up clear cases of the word pavement with the meaning of sidewalk, for example, this passage from a novel by American author Mary Roberts Rinehart:
(9) He had fallen asleep in his buggy, and had wakened to find old Nettie drawing him slowly down the main street of the town, pursuing an erratic but homeward course, while the people on the pavements watched and smiled. (Mary Roberts Rinehart, The Breaking Point, Ch. 10)
Since this reading exists, then, we have found a counterexample to our hypothesis and can reject it.
But what does this mean for our data from the BROWN corpus – is there really nothing to be learned from this sample concerning our hypothesis? Let us say we truly wanted to err on the side of caution, i.e. on the side that goes against our hypothesis, and assign the meaning of sidewalk to Coxe’s novel too. Let us further assume that we can assign all other uses of pavement in the sample to the reading ‘paved surface’, and that two of the four examples of sidewalk in the British English corpus are genuine counterexamples. This would give us the distribution shown in Table 3.5.
Table 3.5: Pavement vs. sidewalk (corrected)
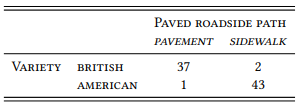
Given this distribution, would we really want to claim that it is wrong to assign pavement to British and sidewalk to American English on the basis that there are a few possible counterexamples? More generally, is falsification by counterexample a plausible research strategy for corpus linguistics?
There are several reasons why the answer to this question must be “no”. First, we can rarely say with any certainty whether we are dealing with true counterexamples or whether the apparent counterexamples are due to errors in the construction of the corpus or in our classification. This turned out to be surprisingly difficult even with respect to a comparatively straightforward issue like the distribution of vocabulary across major dialectal boundaries. Imagine how much more difficult it would have been with grammatical phenomena. For example, the LOB corpus contains (10a):
(10) a. We must not be rattled into surrender, but we must not – and I am not – be afraid of negotiation. (LOB A05)
b. We must not be rattled into surrender, but we must not be – and I am not – afraid of negotiation. (Macmillan 1961)
There is what seems to be an agreement error in (10a), that is due to the fact that the appositional and I am not is inserted before the auxiliary be, leading to the ungrammatical am not be. But how do we know it is ungrammatical, since it occurs in a corpus? In this case, we are in luck, because the example is quoted from a speech by the former British Prime Minister Harold Macmillan, and the original transcript shows that he actually said (10b). But not every speaker in a corpus is a prime minister, just as not every speaker is a well-known author, so it will not usually be possible to get independent evidence for a particular example. Take (11), which represents a slightly more widespread agreement “error”:
(11) It is, however, reported that the tariff on textiles and cars imported from the Common Market are to be reduced by 10 percent. (LOB A15)
Here, the auxiliary be should agree with its singular subject tarrif, but instead, the plural form occurs. There is no way to find out who wrote it and whether they intended to use the singular form but were confused by the embedded plural NP textiles and cars (a likely explanation). Thus, we would have to discard it based on our intuition that it constitutes an error (the LOB creators actually mark it as such, but I have argued at length in Chapter 1 why this would defeat the point of using a corpus in the first place), or we would have to accept it as a counterexample to the generalization that singular subjects take singular verbs (which we are unlikely to want to give up based on a single example).
In theoretical terms, this may not be a definitive argument against the idea of falsification by counterexample. We could argue that we simply have to make sure that there are no errors in the construction of our corpus and that we have to classify all hits correctly as constituting a genuine counterexample or not. However, in actual practice this is impossible. We can (and must) try to minimize errors in our data and our classification, but we can never get rid of them completely (this is true not only in corpus-linguistics but in any discipline).
Second, even if our data and our classification were error-free, human behavior is less deterministic than the physical processes Popper had in mind when he elevated counterexamples to the sole acceptable evidence in science. Even in a simple case like word choice, there may be many reasons why a speaker may produce an exceptional utterance – evoking a variety other than their own (as in the examples above), unintentionally or intentionally using a word that they would not normally use because their interlocutor has used it, temporarily slipping into a variety that they used to speak as a child but no longer do, etc. With more complex linguistic behavior, such as producing particular grammatical structures, there will be additional reasons for exceptional behavior: planning errors, choosing a different formulation in mid-sentence, tiredness, etc. – all the kinds of things classified as performance errors in traditional grammatical theory.
In other words, our measurements will never be perfect and speakers will never behave perfectly consistently. This means that we cannot use a single counterexample (or even a handful of counterexamples) as a basis for rejecting a hypothesis, even if that hypothesis is stated in terms of a universal statement.
However, as pointed out above, many (if not most) hypotheses in corpus linguistics do not take the form of universal statements (“All X’s are Y”, “Z’s always do Y”, etc.), but in terms of tendencies or preferences (“X’s tend to be Y”, “Z’s prefer Y”, etc.). For example, there are a number of prepositions and/or adverbs in English that contain the morpheme -ward or -wards, such as afterward(s), backward(s), downward(s), inward(s), outward(s) and toward(s). These two morphemes are essentially allomorphs of a single suffix that are in free variation: they have the same etymology (-wards simply includes a lexicalized genitive ending), they have both existed throughout the recorded history of English and there is no discernible difference in meaning between them. However, many dictionaries claim that the forms ending in -s are preferred in British English and the ones without the -s are preferred in American English.
We can turn this claim into a hypothesis involving two variables (VARIETY and SUFFIX VARIENT), but not one of the type “All x are y”. Instead, we would have to state it along the lines of (12) and (13):
(12) Most occurrences of the suffix -wards are British English.
(13) Most occurrences of the suffix -ward are American English.
Clearly, counterexamples are irrelevant to these statements. Finding an example like (14a) in a corpus of American English does not disprove the hypothesis that the use in (14b) would be preferred or more typical:
(14) a. [T]he tall young buffalo hunter pushed open the swing doors and walked towards the bar. (BROWN N)
b. Then Angelina turned and with an easy grace walked toward the kitchen. (BROWN K)
Instead, we have to state our prediction in relative terms. Generally speaking, we should expect to find more cases of -wards than of -ward in British English and more of -ward than of -wards in American English, as visualized in Table 3.6 (where the circles of different sizes represent different frequencies of occurrence).
Table 3.6: A contingency table with graded values for the intersections

We will return to the issue of how to phrase predictions in quantitative terms in Chapter 5. Of course, phrasing predictions in quantitative terms raises additional questions: How large must a difference in quantity be in order to count as evidence in favor of a hypothesis that is stated in terms of preferences or tendencies? And, given that our task is to try to falsify our hypothesis, how can this be done if counterexamples cannot do the trick? In order to answer such questions, we need a different approach to hypothesis testing, namely statistical hypothesis testing. This approach will be discussed in detail in Chapter 6.
There is another issue that we must turn to first, though – that of defining our variables and their values in such a way that we can identify them in our data. We saw even in the simple cases discussed above that this is not a trivial matter. For example, we defined American English as “the language occurring in the BROWN and FROWN corpora”, but we saw that the FROWN corpus contains at least one misclassified text by a British author, and we also saw that it is questionable to assume that all and only speakers of American English produce the language we would want to call “American English” (recall the uses of sidewalk by British speakers). Thus, nobody would want to claim that our definition accurately reflects linguistic reality. Similarly, we assumed that it was possible, in principle, to recognize which of several senses of a word (such as pavement) we are dealing with in a given instance from the corpus; we saw that this assumption runs into difficulties very quickly, raising the more general question of how to categorize instances of linguistic phenomena in corpora. These are just two examples of the larger problem of operationalization, to which we will turn in the next section.
1 Which is not to say that existential statements in science cannot lead to a happy ending – consider the case of the so-called Higgs boson, a particle with a mass of 125.09 GeV/c2 and a charge and spin of 0, first proposed by the physicist Peter Higgs and five colleagues in 1964. In 2012, two experiments at the Large Hadron Collider in Geneva finally measured such a particle, thus verifying this hypothesis.