
8.2: Case studies
- Page ID
- 81932

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)8.2.1 Collocational frameworks and grammar patterns
8.2.1.1 Case study: [a __ of]
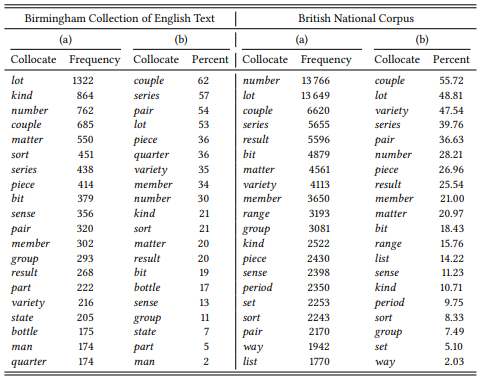
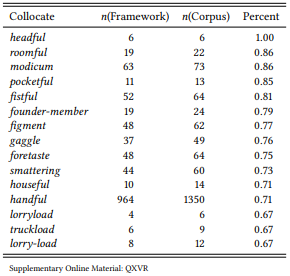
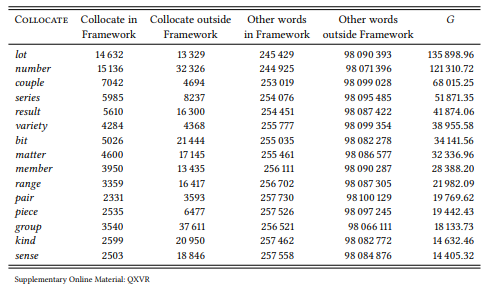
8.2.1.2 Case study: [there Vlinksomething ADJ about NP]
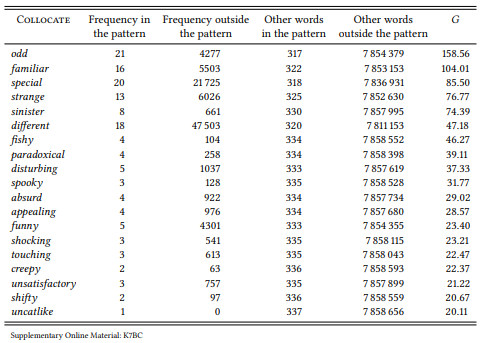
8.2.2 Collostructional analysis
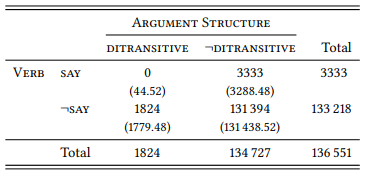
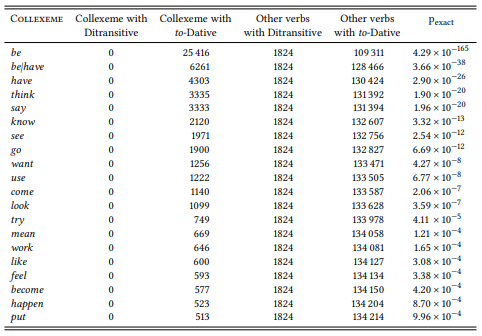
8.2.2.1 Case study: The ditransitive
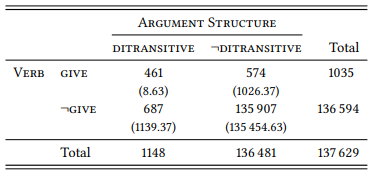
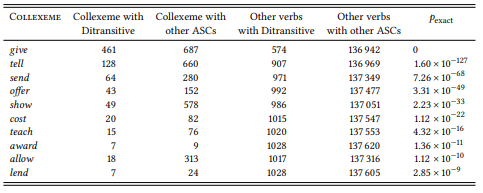
8.2.2.2 Case study: Ditransitive and prepositional dative
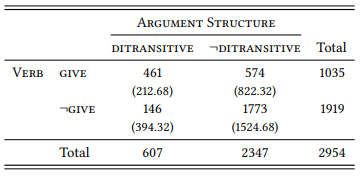
8.2.2.3 Case study: Negative evidence
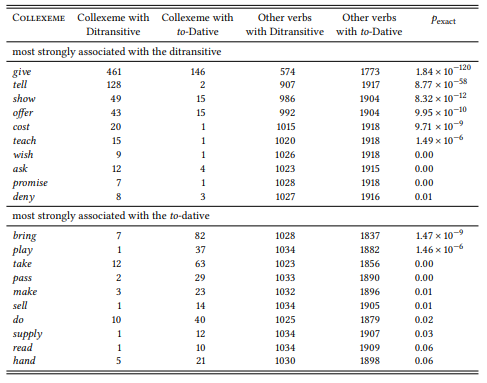
8.2.3 Words and their grammatical properties
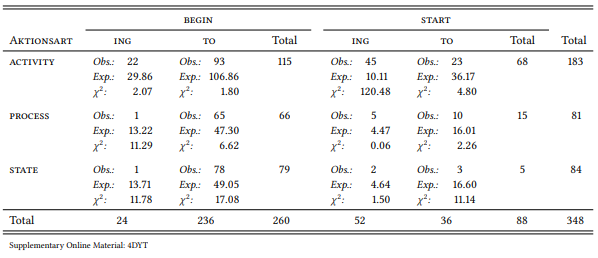
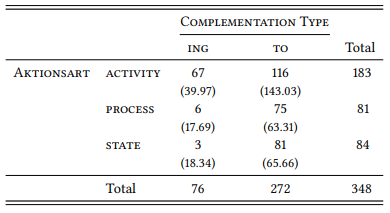
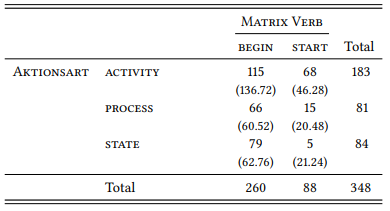
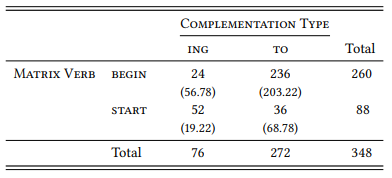
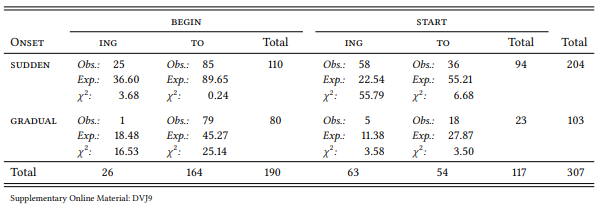
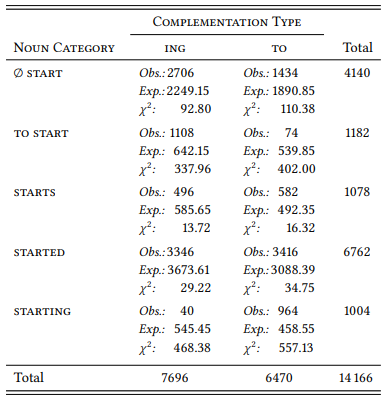
8.2.3.1 Case study: Complementation of begin and start
8.2.4 Grammar and context
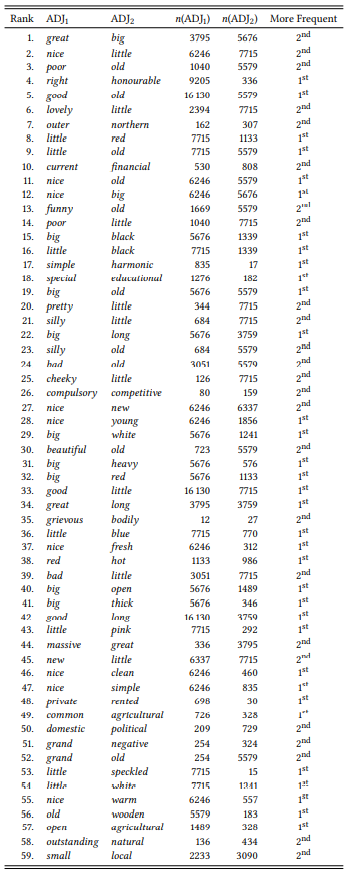
8.2.4.1 Case study: Adjective order and frequency
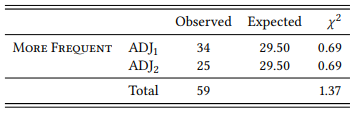
8.2.4.2 Case study: Binomials and sonority
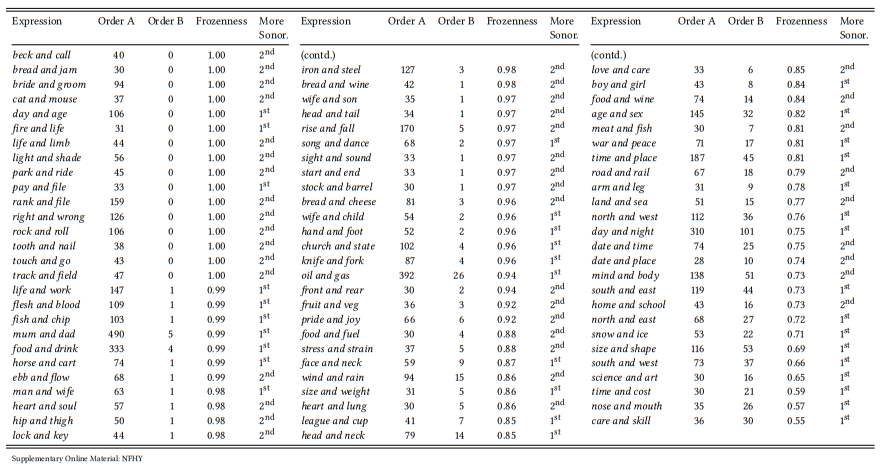
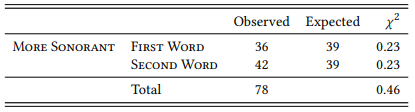
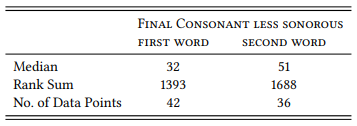
8.2.4.3 Case study: Horror aequi
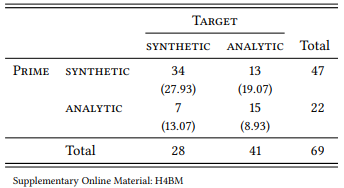
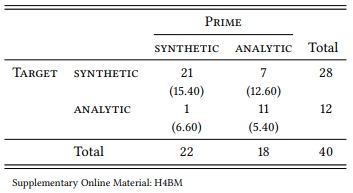
8.2.4.4 Case study: Synthetic and analytic comparatives and persistence
8.2.5 Variation and change
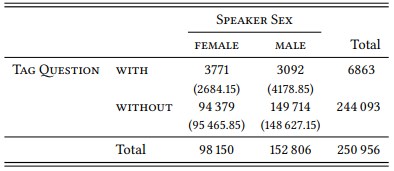
8.2.5.1 Case study: Sex differences in the use of tag questions
Grammatical differences may also exist between varieties spoken by subgroups of speakers defined by demographic variables, for example, when the speech of younger speakers reflects recent changes in the language, or when speakers from different educational or economic backgrounds speak different established sociolects. Even more likely are differences in usage preference. For example, Lakoff (1973) claims that women make more intensive use of tag questions than men. Mondorf (2004b) investigates this claim in detail on the basis of the London-Lund Corpus, which is annotated for intonation among other things. Mondorf’s analysis not only corroborates the claim that women use tag questions more frequently than men, but also shows qualitative differences in terms of their form and function.
This kind of analysis requires very careful, largely manual data extraction and annotation so it is limited to relatively small corpora, but let us see what we can do in terms of a larger-scale analysis. Let us focus on tag questions with negative polarity containing the auxiliary be (e.g. isn’t it, wasn’t she, am I not, was it not). These can be extracted relatively straightforwardly even from an untagged corpus using the following queries:
8.2.5.2 Case study: Language change
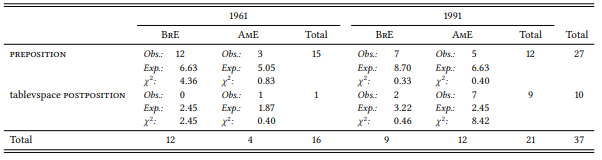
Grammatical differences between varieties of a language will generally change over time – they may increase, as speech communities develop separate linguistic identities or even lose contact with each other, or they may decrease, e.g. through mutual influence. For example, Berlage (2009) studies word-order differences in the placement of adpositions in British and American English, focusing on notwithstanding as a salient member of a group of adpositions that can occur as both pre- and postpositions in both varieties. Two larger questions that she attempts to answer are, first, the diachronic development and, second, the interaction of word order and grammatical complexity. She finds that the prepositional use is preferred in British English (around two thirds of all uses are prepositions in present-day British newspapers) while American English favors the postpositional use (more than two thirds of occurrences in American English are postpositions). She shows that the postpositional use initially accounted for around a quarter of all uses but then almost disappeared in both varieties; its reemergence in American English is a recent development (the convergence and/ or divergence of British and American English has been intensively studied, cf. e.g. Hundt 1997 and Hundt 2009).
8.2.5.3 Case study: Grammaticalization
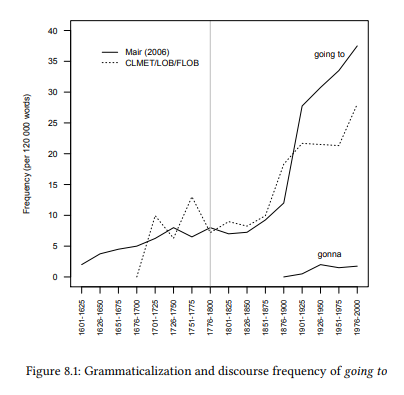
One of the central issues in grammaticalization theory is the relationship between grammaticalization and discourse frequency. Very broadly, the question is whether a rise in discourse frequency is a precondition for (or at least a crucial driving force in) the grammaticalization of a structure, or whether it is a consequence.
Since corpora are the only source for the identification of changes in discourse frequency, this is a question that can only be answered using corpus-linguistic methodology. An excellent example is Mair (2004), which looks at a number of grammaticalization phenomena to answer this and other questions.
He uses the OED’s citation database as a corpus (not just the citations given in the OED’s entry for the specific phenomena he is interested in, but all citations used in the entire OED). It is an interesting question to what extent such a citation database can be treated as a corpus (cf. the extensive discussion in Hoffmann 2004). One argument against doing so is that it is an intentional selection of certain examples over others and thus may not yield an authentic picture of any given phenomenon. However, as Mair points out, the vast majority of examples of a given phenomenon X will occur in citations that were collected to illustrate other phenomena, so they should constitute random samples with respect to X. The advantage of citation databases for historical research is that the sources for citations will have been carefully checked and very precise information will be available as to their year of publication and their author.
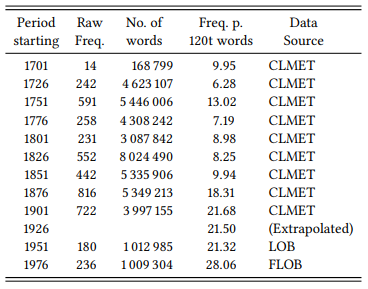
Let us look at one of Mair’s examples and compare his results to those derived from more traditional corpora, namely the Corpus of Late Modern English Texts (CLMET), LOB and FLOB. The example is that of the going-to future. It is relatively easy to determine at what point at the latest the sequence [going to Vinf] was established as a future marker. In the literature on going to, the following example from the 1482 Revelation to the Monk of Evesham is considered the first documented use with a future meaning (it is also the first citation in the OED):
8.2.6 Grammar and cultural analysis
Like words, grammatical structures usually represent themselves in corpus linguistic studies – they are either investigated as part of a description of the syntactic behavior of lexical items or they are investigated in their own right in order to learn something about their semantic, formal or functional restrictions. However, like words, they can also be used as representatives of some aspect of the speech community’s culture, specifically, a particular culturally defined scenario. To take a simple example: if we want to know what kinds of things are transferred between people in a given culture, we may look at the theme arguments of ditransitive constructions in a large corpus; we may look for collocates in the verb and theme positions of the ditransitive if we want to know how particular things are transferred (cf. Stefanowitsch & Gries 2009). In this way, grammatical structures can become diagnostics of culture. Again, care must be taken to ensure that the link between a grammatical structure and a putative scenario is plausible.
8.2.6.1 Case study: He said, she said
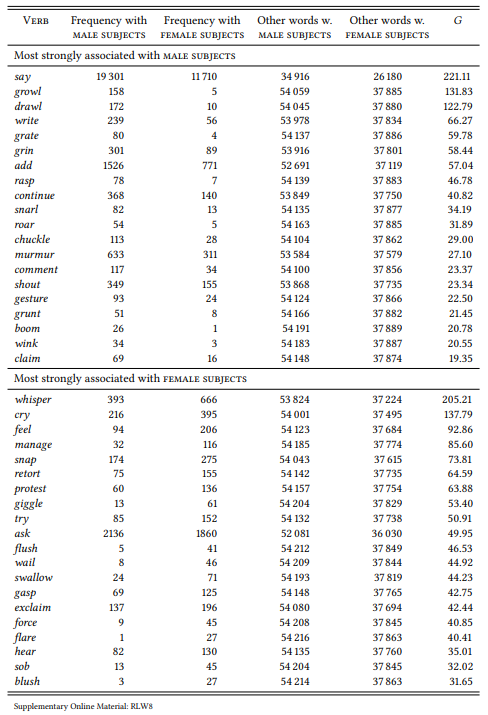
In a paper on the medial representation of men and women, Caldas-Coulthard (1993) finds that men are quoted vastly more frequently than women in the COBUILD corpus (cf. also Chapter 9). She also notes in passing that the verbs of communication used to introduce or attribute the quotes differ – both men’s and women’s speech is introduced using general verbs of communication, such as say or tell, but with respect to more descriptive verbs, there are differences: “Men shout and groan, while women (and children) scream and yell” (Caldas-Coulthard 1993: 204)
8.2.7 Grammar and counterexamples
While this book focuses on quantitative designs, non-quantitative designs are possible within the general framework adopted. Chapter 3 included a discussion of counterexamples and their place in a scientific framework for corpus linguistics. Let us conclude this chapter with a case study making use of them.
8.2.7.1 Case study: To- vs. that-complements
A good case study for English that is based largely on counterexamples is Noël (2003), who looks at a number of claims made about the semantics of infinitival complements as compared to that-clauses. He takes claims made by other authors based on their intuition and treats them like Popperian hypotheses, searching the BNC for counterexamples. He mentions more or less informal impressions about frequencies, but only to clarify that the counterexamples are not just isolated occurrences that could be explained away.