
10.2: Case studies
- Last updated
- Save as PDF
- Page ID
- 81938

610.2.1 Language variety
Keyword analysis has been applied to a wide range of language varieties defined by topic area (e.g. travel writing), genre (e.g. news reportage) or both (e.g. history textbooks) (see the contributions in Bondi & Scott 2010 for recent examples). Here, we will look at two case studies of scientific language.
10.2.1.1 Case study: Keywords in scientific writing
There are a number of keyword-based analyses of academic writing (cf., for example, Scott & Tribble 2006 on literary criticism, Römer & Wulff 2010 on academic student essays). Instead of replicating one of these studies in detail, let us look more generally at the Learned and Scientific Writing section of the LOB (Section J), using the rest of the corpus (all sections except Section J) as a reference corpus. \(Table \text { } 10.5\) shows the keywords for this section.
It is immediately obvious from the preponderance of scientific terminology that we are dealing with Scientific English – there are general scientific terms like fig(ure), data experiment or model, mathematical terms and symbols (equation, values, the equals and percent signs), and a few words from chemistry (oxygen, sodium) (the reason the @ sign appears on this list is because it is used to mark places in the corpus where material such as mathematical formulae and operators have been deleted).
It may not be surprising that scientific terminology dominates in a corpus of Scientific English, but it demonstrates that keyword analysis works. Given this, we can make some more profound observations on the basis of the list in \(Table \text { }10.5\). For example, we observe that certain kinds of punctuation are typical of academic writing in general (such as the parentheses, which we already suspected based on the analysis of the fish population report in Section 10.1 above).
\(Table \text { } 10.5\): Key words in the Learned and Scientific Writing section of LOB
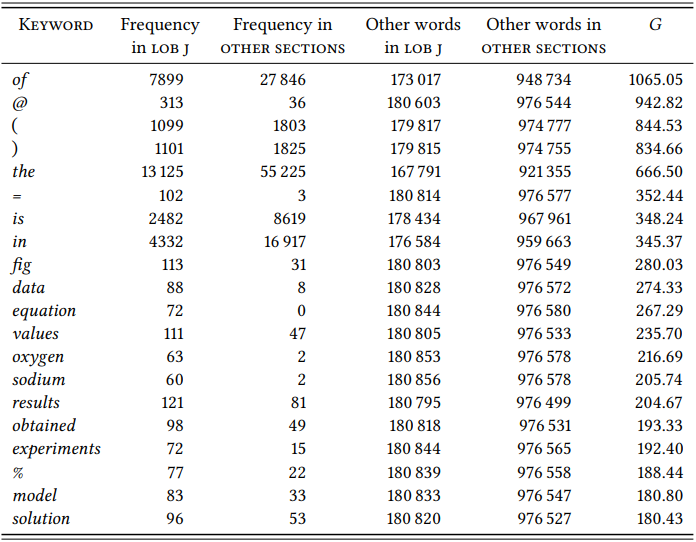
Even more interestingly, keyword analysis can reveal function words that are characteristic for a particular language variety and thus give us potential insights into grammatical structures that may be typical for it; for example, is, the and of are among the most significant keywords of Scientific English. The last two are presumably related to the nominal style that is known to characterize academic texts, while the higher-than-normal frequency of is may be due to the prevalence of definitions, statements of equivalence, etc. This (and other observations made on the basis of keyword analysis) would of course have to be followed up by more detailed analyses of the function these words serve – but keyword analysis tells us what words are likely to be interesting to investigate.
10.2.1.2 Case study: [a + __ + of] in Scientific English
Of course, keyword analysis is not the only way to study lexical characteristics of language varieties. In principle, any design studying the interaction of lexical items with other units of linguistic structure can also be applied to specific language varieties.
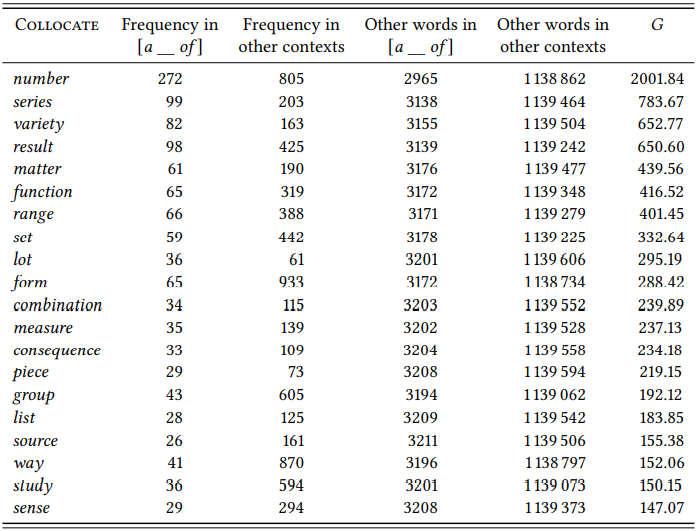
For example, Marco (2000) investigates collocational frameworks (see Chapter 8, Section 8.2.1) in medical research papers. While this may not sound particularly interesting at first glance, it turns out that even highly frequent frameworks like [a __ of ] are filled by completely different items from those found in the language as a whole, which is important for many applied purposes (such as language teaching or machine processing of language), but which also shows just how different language varieties can actually be. Since Marco’s corpus is not publicly available and the Learned and Scientific Writing section of LOB is too small for this kind of analysis, let us use the Written Academic subsection of the BNC Baby. \(Table \text { } 10.6\) shows the 15 most strongly associated collocates in the framework [a __ of ], i.e. the words whose frequency of occurrence inside this framework differs most significantly from their frequency of occurrence outside of this framework in the same corpus section.
If we compare the result in \(Table \text { } 10.6\) to that in \(Table \text { } 8.3\) in Chapter 8, we notice clear differences between the use of this framework in academic texts and the language as a whole; for example, lot, which is most strongly associated with the framework in the general language occurs in 9th position, while the top collocates of the framework are more precise quantification terms like number or series, and general scientific terms like result and function.
However, the two lists – that in \(Table \text { } 8.3\) and that presented here – were derived independently from different corpora, making it difficult to determine the true extent of the differences. In particular, in each of the two corpora the words in the pattern compete with the words outside of the pattern, which are obviously from the same discourse domains. To get a clearer idea of the different function(s) that a pattern might play in two different language varieties, we can combine collocational framework analysis and keyword analysis: we extract all words occurring in a collocational framework (or grammar pattern, construction, etc.) in a particular language variety, and compare them to the words occurring in the same pattern in a reference corpus (Stefanowitsch 2017 refers to this mix of keyword and collostructional analysis as “textually-distinctive [i.e., differential] collexeme analysis”).
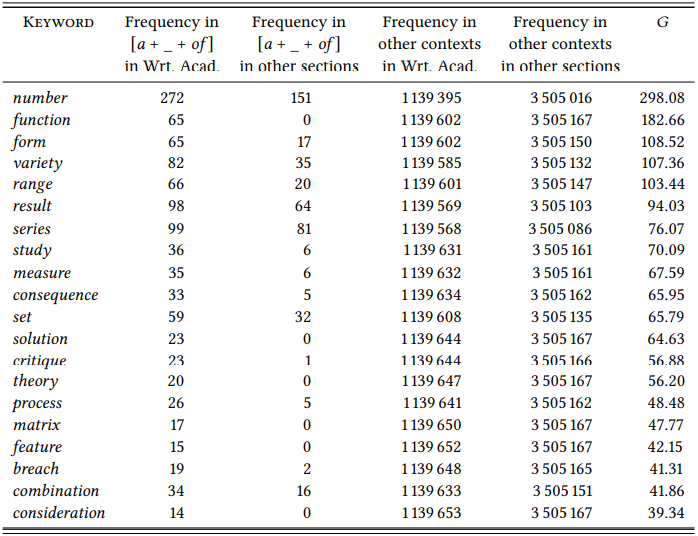
\(Table \text { } 10.7\) shows the result of such an analysis in the BNC Baby, comparing words occurring in the framework [a(n) _ of ] in the Written Academic section to the words occurring in the same pattern in the rest of the corpus (all sections other than Written Academic). The scientific vocabulary now dominates the collocates of the framework even more clearly than in the simple collocational framework analysis above: the in
\(Table \text { } 10.6\): Collocates of the framework [a __ of ] in the Written Academic subsection of BNC Baby
formal a lot of and other colloquial words are now completely absent. This case study shows the variability that even seemingly simple grammatical patterns may display across language varieties. It is also meant to demonstrate how simple techniques like collocational-framework analysis can be combined with more sophisticated techniques to yield more insightful results.
10.2.2 Comparing speech communities
As pointed out at the beginning of this chapter, a keyword analysis of corpora that are defined by demographic variables is essentially a variant of variationist sociolinguistics. The basic method remains the same, the only difference being that the corpora under investigation have to be constructed based on the variables in question, or, more typically, that existing corpora have to be separated into subcorpora accordingly. This is true for inductive keyword analyses as well
\(Table \text { } 10.7\): Textually differential collexemes in the framework [a + _- + of ] in the Written Academic section of BNC Baby compared to all other sections
as for the kind of deductive analysis of individual words or constructions that we used in some of the examples in earlier chapters. The dependent variable will, as in all examples in this and the preceding chapter, always be nominal, consisting of (some part of) the lexicon (with words as values).
Lectal variety (dialect, sociolect, etc.) is an obvious demographic category to investigate using corpus-linguistic methods. Language varieties differ from each other along a number of dimensions, one of which is the lexicon. While lexical differences have not tended to play a major role in mainstream sociolinguistics, they do play a role in corpus-based sociolinguistics – presumably, because they are relatively easy to extract from appropriately constructed corpora, but also because they have traditionally been an important defining criterion of dialects (and continue to be so, especially in applied contexts).
Many of the examples in the early chapters of this book demonstrate how, in principle, lexical differences between varieties can be investigated – take two sufficiently large corpora representing two different varieties, and study the distribution of a particular word across these two corpora. Alternatively, we can study the distribution of all words across the two corpora in the same way as we studied their distribution across texts or language varieties in the preceding section.
This was actually done fairly early, long before the invention of keyword analysis, by Johansson & Hofland (1989). They compare all word forms in the LOB and BROWN corpora using a “coefficient of difference”, essentially the percentage of the word in the two corpora.2 In addition, they test each difference for significance using the \(\chi^{2}\) test. As discussed in Chapter 7, it is more recommendable – and, in fact, simpler – to use an association measure like \(G\) right away, as percentages will massively overestimate infrequent events (a word that occurs only a single time will be seen as 100 percent typical of whichever corpus it happens to occur in); also, the \(\chi^{2}\) test cannot be applied to infrequent words. Still, Johansson and Hofland’s basic idea is highly innovative and their work constitutes the first example of a keyword analysis that I am aware of.
Comparing two (large) corpora representing two varieties will not, however, straightforwardly result in a list of dialect differences. Instead, there are at least five types of differences that such a comparison will uncover. Not all of them will be relevant to a particular research design, and some of them are fundamental problems for any research design and must be dealt with before we can proceed.
\(Table \text{ } 10.8\) shows the ten most strongly differential keywords for the LOB and BROWN corpora. The analysis is based on the tagged versions of the two corpora as originally distributed by ICAME.
For someone hoping to uncover dialectal differences between British and American English, these lists are likely to be confusing, to say the least. The hyphen is the strongest American keyword? Quotation marks are typical for British English? The word The is typically American? Clitics like n’t, ’s and ’m are British, while words containing these clitics, like didn’t, it’s and I’m are American? Of
\(Table \text { } 10.8\): Key words of British and American English based on a comparison of LOB and BROWN
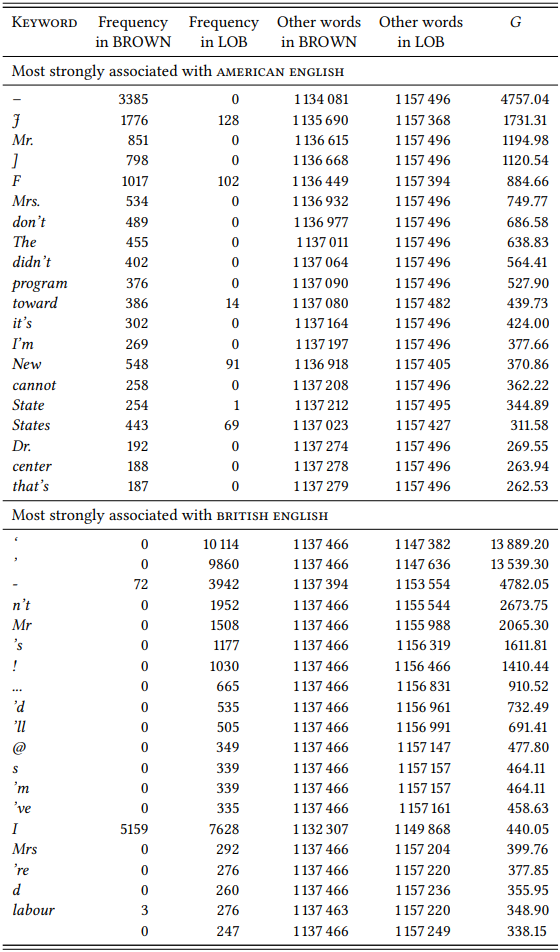
course not – all of these apparent differences between American and British English are actually differences in the way the two corpora were prepared. The tagged version of the BROWN corpus does not contain quotation marks because they have intentionally been stripped from the text. The with an uppercase T does not occur in the tagged LOB corpus, because case is normalized such that only proper names are capitalized. And clitics are separate tokens in LOB but not in BROWN.
In other words, the two corpora have to be made comparable before they can be compared. \(Table \text { } 10.9\) shows the 10 most strongly differential keywords for the LOB and BROWN corpora respectively, after all words in both corpora have been put into lowercase, all clitics in BROWN have been separated from their stems, and all tokens consisting exclusively of punctuation marks have been removed, as have periods at the end of abbreviations like mr. and st.
This list is much more insightful. There are still some artifacts of corpus construction: the codes F and J are used in BROWN to indicate that letter combinations and formulae have been removed. But the remainder of the keywords is now representative of the kinds of differences a dialectal keyword analysis will typically uncover.
First, there are differences in spelling. For example, labour and behaviour are spelled with ou in Britain, but with o in the USA, the US-American defense is spelled defence in Britain, and the British programme is spelled program in the USA. These differences are dialectal and may be of interest in applied contexts, but they are not likely to be of primary interest to most linguists. In fact, they are often irritating, since of course we would like to know whether words like labo(u)r or behavio(u)r are more typical for British or for American English aside from the spelling differences. To find out, we have to normalize spellings in the corpora before comparing them (which is possible, but labo(u)r-intensive).
Second, there are proper nouns that differ in frequency across corpora: for example, geographical names like London, Britain, Commonwealth, and (New) York will differ in frequency because their referents are of different degrees of interest to the speakers of the two varieties. There are also personal names that differ across corpora; for example, the name Macmillan occurs 63 times in the LOB corpus but only once in BROWN; this is because in 1961, Harold Macmillan was the British Prime Minister and thus Brits had more reason to mention the name. But there are also names that differ in frequency because they differ in popularity in the speech communities: for example, Mike is a keyword for BROWN, Michael for LOB. Thus, proper names may differ in frequency for purely cultural or for linguistic reasons; the same is true of common nouns.
\(Table \text { } 10.9\): Key words of British and American English based on a comparison of LOB and BROWN
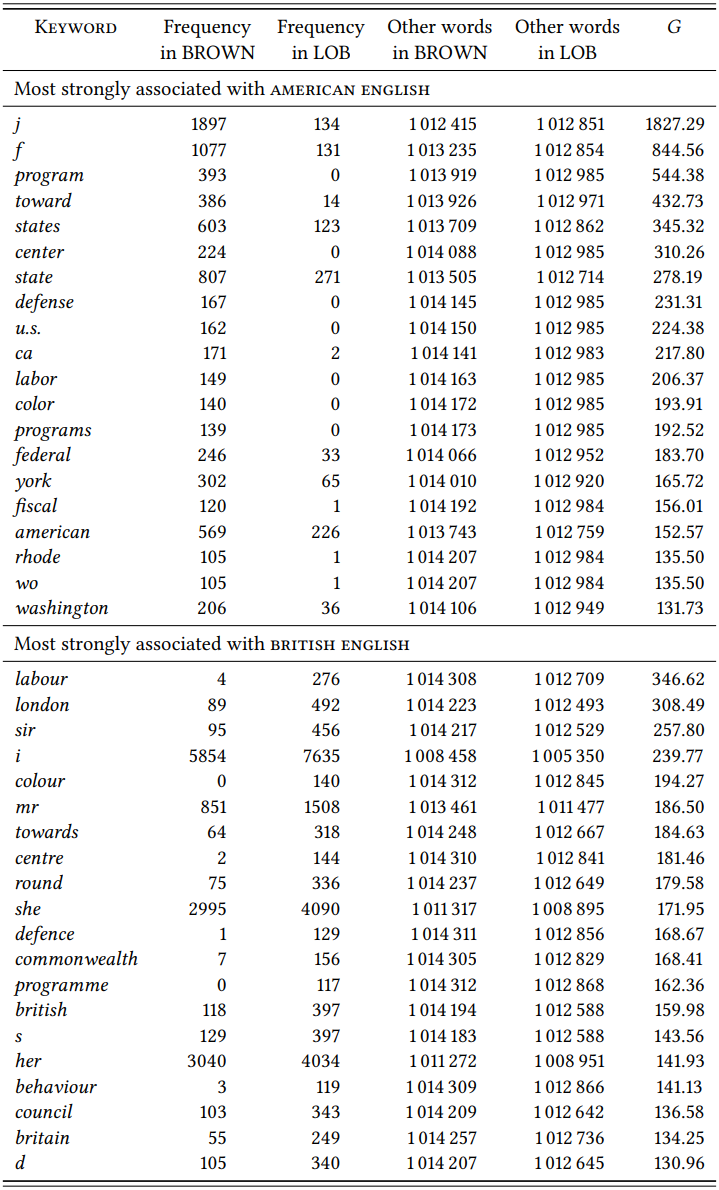
Third, nouns may differ in frequency not because they are dialectal, but because the things they refer to play a different role in the respective cultures. State, for example, is a word found in both varieties, but it is more frequent in US-American English because the USA is organized into 50 states that play an important cultural and political role.
Fourth, nouns may differ in frequency due to dialectal differences (as we saw in many of the examples in previous chapters). Take toward and towards, which mean the same thing, but for which the first variant is preferred in US-American and the second in British English. Or take round, which is an adjective meaning ‘shaped like a circle or a ball’ in both varieties, but also an adverb with a range of related meanings that corresponds to American English around.
This case study was mainly intended to demonstrate the difficulty of comparing corpora that are not really comparable in terms of the way they have been constructed. It was also meant to demonstrate how large-scale comparisons of varieties of a language can be done and what kind of results they yield. From a theoretical perspective, these results may seem to be of secondary interest, at least in the domain of lexis, since lexical differences between the major varieties of English are well documented. But from a lexicographical perspective, large-scale comparisons of varieties are useful, especially because dialectal differences are constantly evolving.
10.2.2.1 Case study: British vs. American culture
Keyword analysis of language varieties is often done not to uncover dialectal variation, but to identify cultural differences between speech communities. Such studies have two nominal variables: \(\mathrm{Culture}\) (operationalized as “corpus containing language produced by members of the culture”) and \(\mathrm{Area \space of \space Life}\) (operationalized as “semantic field”). They then investigate the importance of different areas of life for the cultures involved (where the importance of an area is operationalized as “having a large number of words from the corresponding semantic field among the differential keywords”). The earliest study of this kind is Leech & Fallon (1992), which is based on the keyword list of British and American English in Johansson & Hofland (1989).
The authors inductively identify words pointing to cultural contrasts by discarding all words whose distribution across the two corpora is not significant, all proper names, and all words whose significant differences in distribution are due to dialectal variation (including spelling variation). Next, they look at concordances of the remaining words to determine first, which senses are most frequent and thus most relevant for the observed differences, and second, whether the words are actually distributed across the respective corpus, discarding those whose overall frequency is simply due to their frequent occurrence in a single file (since those words would not tell us anything about cultural differences). Finally, they sort the words into semantic fields such as sport, travel and transport, business, mass media, military, etc., discussing the quantitative and qualitative differences for each semantic field.
For example, they note that there are obvious differences between the types of sports whose vocabulary differentiates between the two corpora (baseball is associated with the BROWN corpus, cricket and rugby with the LOB corpus), reflecting the importance of these sports in the two cultures, but also that general sports vocabulary (athletic, ball, playing, victory) is more often associated with the BROWN corpus, suggesting a greater overall importance of sports in 1961 US-American culture. Except for one case, they do not present the results systematically. They list lexical items they found to differentiate between the corpora, but it is unclear whether these lists are exhaustive or merely illustrative (the only drawback of this otherwise methodologically excellent study).
The one case where they do present a table is the semantic field military. Their results are shown in \(Table \text { } 10.10\) (I have recalculated them using the \(G\) value we have used throughout this and the preceding section).
There are two things to note about this list. First, as Leech & Fallon (1992) point out, many of these words do not occur exclusively, or even just most frequently, in the military domain. For a principled study of the different role that the military may play in British and American culture, it would be necessary to limit the study to unambiguously military words like militia, or to check all instances of ambiguous words individually and only include those used in military contexts. For example, (1a) would have to be included, while (1b) is clearly about hunting and would have to be excluded:
-
- These remarkable ships and weapons, ranging the oceans, will be capable of accurate fire on targets virtually anywhere on earth. (BROWN G35)
- A trap for throwing these miniature clays fastens to the barrel so that the shooter can throw his own targets. (BROWN E10)
Second, the list is not exhaustive, listing only words which show a significant difference across the two varieties. For example, the obvious items soldier and soldiers are missing because they are roughly equally frequent in the two varieties. However, if we want to make strong claims about the role of a particular domain of life (i.e., semantic field) in a culture, we need to take into consideration not just the words that show significant differences but also the ones that do not. If there are many of the latter, this would weaken the results.
\(Table \text { } 10.10\): Military keywords in BROWN and LOB (cf. Leech & Fallon 1992: 49-50)
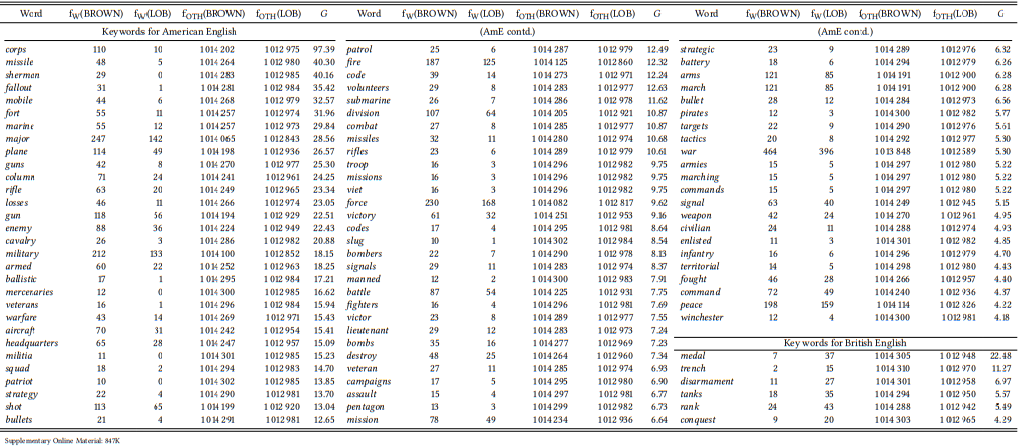
Third, the study of cultural importance cannot be separated entirely from the study of dialectal preferences. For example, the word armistice occurs 15 times in the LOB corpus but only 4 times in BROWN, making it a significant keyword for British English (\(G^{2}\) = 6.80). However, before we conclude that British culture is more peaceful than American culture, we should check synonyms. We find that truce occurs 5 times in BROWN and not at all in LOB, making it an equally significant keyword for American English (\(G^{2}\) = 6.92). Finally, cease-fire occurs 7 times in each corpus. In other words, the two cultures differ not in the importance of cease-fires, but in the words they use to denote them – similar dialectal preferences may well underlie other items on Leech and Fallon’s list.
Overall, however, Leech & Fallon (1992) were careful to include words that occur in military contexts in a substantial number of instances and to cover the semantic field broadly (armistice and truce were two of the few words I was able to think of that turned out to have significant associations). Thus, their conclusion that the concept WAR played a more central role in US culture in 1961 than it did in British culture seems reliable.
This case study is an example of a very carefully constructed and executed contrastive cultural analysis based on keywords. Note, especially, that Leech and Fallon do not just look for semantic fields that are strongly represented among the statistically significant keywords of one corpus, but that they check the entire semantic field (or a large portion of it) with respect to its associations in both corpora. In other words, they do not look only for evidence, but also for counterevidence, something that is often lacking in cultural keyword studies.
10.2.2.2 Case study: “African” keywords
Another study that involves keyword analyses aimed at identifying significant cultural concepts is Wolf & Polzenhagen (2007). The authors present (among other things) an analysis of “African” keywords arrived at by comparing a corpus of Cameroon English to the combined FLOB/FROWN corpora (jointly meant to present “Western culture”). Their study is partially deductive, in that they start out from a pre-conceived “African model of community” which, so they claim, holds for all of sub-Saharan Africa and accords the extended family and community a central role in a “holistic cosmology” involving hierarchical structures of authority and respect within the community, extending into the “spiritual world of the ancestors”, and also involving a focus on gods and witchcraft.
The model seems somewhat stereotypical, to say the least, but a judgment of its accuracy is beyond the scope of this book. What matters here is that it guides the authors in their search for keywords that might differentiate between their two corpora. Unlike Leech and Fallon in the study described above, it seems that they did not create a complete list of differential keywords and then categorized them into semantic fields, but instead focused on words for kinship relations, spiritual entities and witchcraft straight away.
This procedure yields seemingly convincing word lists like that in \(Table \text { } 10.11\), which the authors claim shows “the salience of authority and respect and the figures that can be associated with them” Wolf & Polzenhagen (2007: 420).
\(Table \text { } 10.11\): Keywords relating to authority and respect in a corpus of Cameroon English (from Wolf & Polzenhagen 2007: 421).
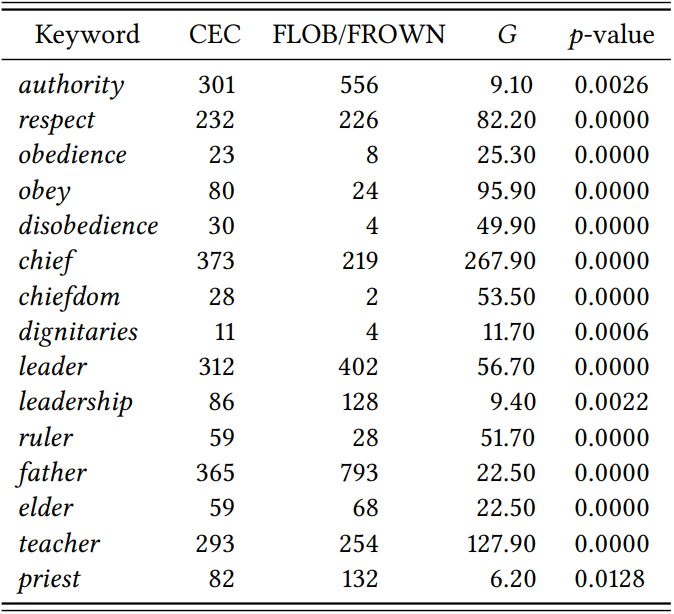
However, it is very difficult to tell whether this is a real result or whether it is simply due to the specific selection of words they look at. Some obvious items from the semantic field \(\mathrm{Authority}\) are missing from their list – for example, command, rule, disobey, disrespect, and power. As long as we do not know whether they failed to check the keyness of these (and other) \(\mathrm{Authority}\) words, or whether they did check them but found them not to be significant, we cannot claim that authority and respect play a special role in African culture(s) for the simple reason that we cannot exclude the possibility that these words may actually be significant keywords for the combined FROWN/FLOB corpus.
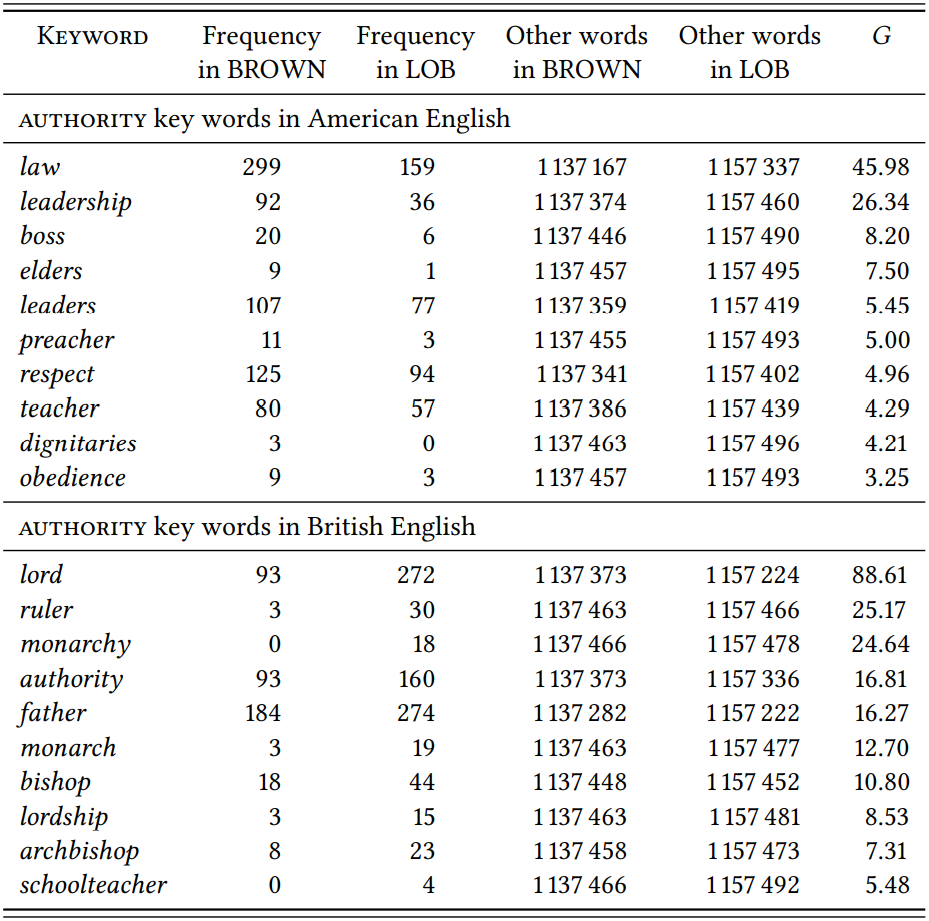
With respect to the latter, note that it is also questionable whether one can simply combine a British and an American corpus to represent “Western” culture. First, it assumes that the two cultures individually belong to such a larger culture and can jointly represent it. Second, it assumes that these two cultures do not accord any specific importance to whatever domain we are looking at. However, especially if we choose our keywords selectively, we could easily show that \(\mathrm{Authority}\) has a central place in British or American culture. \(Table \text { } 10.12\) lists ten significantly associated keywords from each corpus, resulting from the direct comparison discussed in 10.2.2. By presenting just one or the other list, we could make any argument about Britain, the USA and authority that suits our purposes.
This case study demonstrates some of the potential pitfalls of cultural keyword analysis. This is not to suggest that Wolf & Polzenhagen (2007) is methodologically flawed, but that the way they present the results does not allow us to determine the methodological soundness of their approach. Generally, semantic domains should be extracted from corpora as exhaustively as possible in such analyses, and all results should be reported. Also, instead of focusing on one culture and using another culture as the reference corpus, it seems more straightforward to compare specific cultures (for example in the sense of “speech communities within a nation state”) directly, as Leech & Fallon (1992) do (cf. also Oakes & Farrow 2007 for a method than can be used to compare more than two varieties against each other in a single analysis).
10.2.3 Co-occurrence of lexical items and demographic categories
The potential overlap between keyword analysis and sociolinguistics becomes most obvious when using individual demographic variables such as sex, age, education, income, etc. as individual variables. Note that such variables may be nominal (sex), or ordinal (age, income, education); however, even potentially ordinal variables are treated as nominal in keyword-based studies, since keyword analysis cannot straightforwardly deal with ordinal data (although it could, in principle, be adapted to do so).
10.2.3.1 Case study: A deductive approach to sex differences
A thorough study of lexical differences between male and female speech is Schmid (2003) (inspired by an earlier, less detailed study by Rayson et al. 1997). Schmid uses the parts of the BNC that contain information about speaker sex (which means that he simply follows the definition of \(\mathrm{Sex}\) used by the corpus creators); he uses the difference coefficient from Johansson & Hofland (1989) discussed in Section 10.2.2 above. His procedure is at least partially deductive in
\(Table \text { } 10.12\): Key words from the domain Authority in British and American English
that he focuses on particular \(\mathrm{Semantic \space Domains}\) in which differences between \(\mathrm{male}\) and \(\mathrm{female}\) language are expected according to authors like Lakoff (1973), for example, \(\mathrm{color}\), \(\mathrm{clothing}\), \(\mathrm{body \space and \space health}\), \(\mathrm{car \space and \space traffic}\) and \(\mathrm{public \space affairs}\). As far as one can tell from his description of his methodology, he only looks at selected words from each category, so the reliability of the results depends on the plausibility of his selection.
One area in which this is unproblematic is \(\mathrm{color}\): Schmid finds that all basic color terms (black, white, red, yellow, blue, green, orange, pink, purple, grey) are more frequent in women’s language than in men’s language. Since basic color terms are (synchronically) a closed set and Schmid looks at the entire set, the results may be taken to suggest that women talk about color more often than men do. Similarly, for the domain \(\mathrm{temporal \space deixis}\) Schmid looks at the expressions yesterday, tomorrow, last week, tonight, this morning, today, next week, last year and next year and finds that all but the last three are significantly more frequently used by women. While this is not a complete list of temporal deictic expressions, it seems representative enough to suggest that the results reflect a real difference.
The semantic domain \(\mathrm{personal \space reference}\) is slightly more difficult – it is large, lexically diverse and has no clear boundaries. Schmid operationalizes it in terms of the pronouns I, you, he, she, we, they and the relatively generic human nouns boy, girl, man, men, people, person, persons, woman, women (it is unclear why the sex-neutral child(ren) and the plurals boys and girls are missing). This is not a bad selection, but it is clear that there are many other ways of referring to persons – proper names, kinship terms, professions, to name just a few. There may be good reasons for excluding these, but doing so means that we are studying not the semantic field of personal reference as a whole, but a particular aspect of it.
\(Table \text { } 10.13\) shows the distribution of these nouns across the parts of the BNC annotated for speaker sex, both written and spoken (I have added the missing plurals boys and girls and the words child and children).
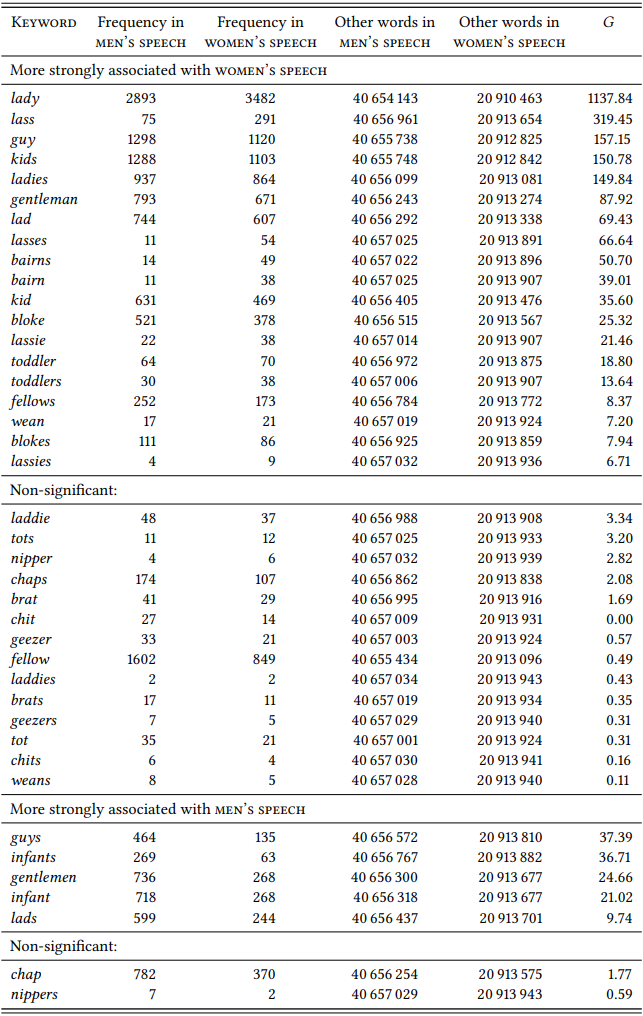
Within the limitations just mentioned, it seems that a good case can be made that women’s speech is characterized by a higher proportion of personal reference terms (at least if the corpus is well constructed, a point I will return to in the next subsection). The words selected to represent this domain form a welldelineated set – stylistically neutral English nouns referring to people with no additional semantic content other than sex (the pronouns are even a closed set). The only potential caveat is just that the words are stylistically neutral and that the results may thus reflect a tendency of women to use a more standard variety of the language. Thus, we might want to look at synonyms for man, woman, boy, girl and child. \(Table \text { } 10.14\) shows the results.
\(Table \text { } 10.13\): Differential collocates for men and women in the domain \(\mathrm{personal \space reference}\)
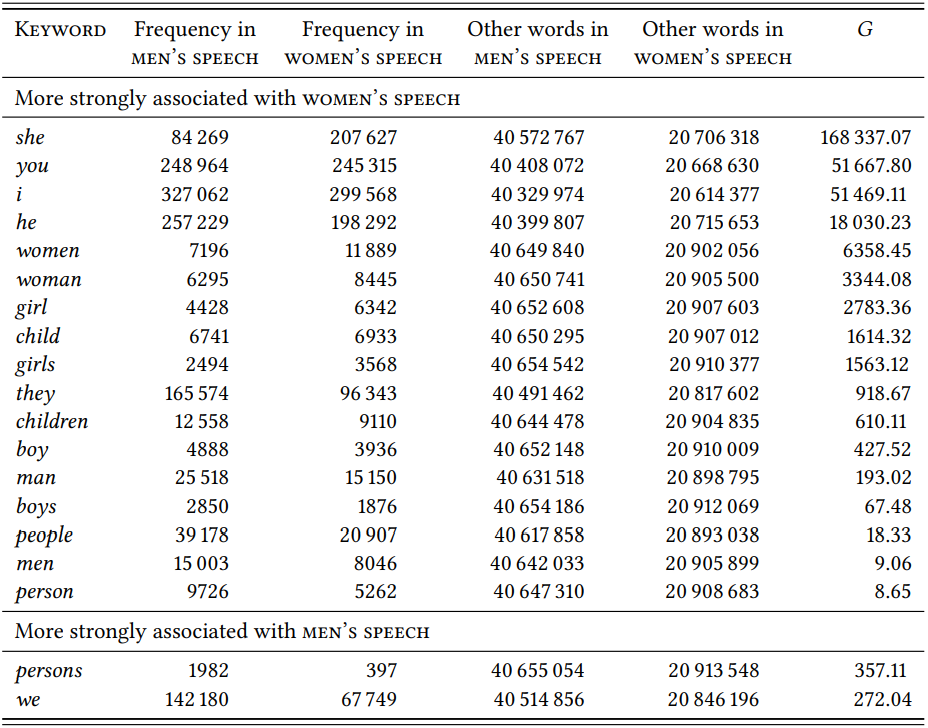
We see the same general difference as before, so the result is not due to different style preferences of men and women, but to the semantic field under investigation.
Many other fields that Schmid investigates make it much more difficult to come up with a plausibly representative sample of words. For example, for the domain \(\mathrm{health \space and \space body}\), Schmid looks at breast, hair, headache, legs, sore throat, doctor, sick, ill, leg, eyes, finger, fingers, eye, body, hands, and hand and finds that with the exception of hand they are all more frequently used by women. The selection seems small and rather eclectic, however, so let us enlarge the set with the words ache, aching, flu, health, healthy, influenza, medicine, nurse, pain and unwell from the domain \(\mathrm{health}\) and arms, ear, ears, feet, foot, kidneys, liver, mouth, muscles, nose, penis, stomach, teeth, thumb, thumbs, tooth, vagina and vulva from the domain \(\mathrm{body}\). \(Table \text { } 10.15\) shows the results.
\(Table \text { } 10.14\): More differential collocates for men and women in the domain \(\mathrm{personal \space reference}\)
\(Table \text { } 10.15\): Differential collocates for men and women in the domain \(\mathrm{body \space and \space helath}\)
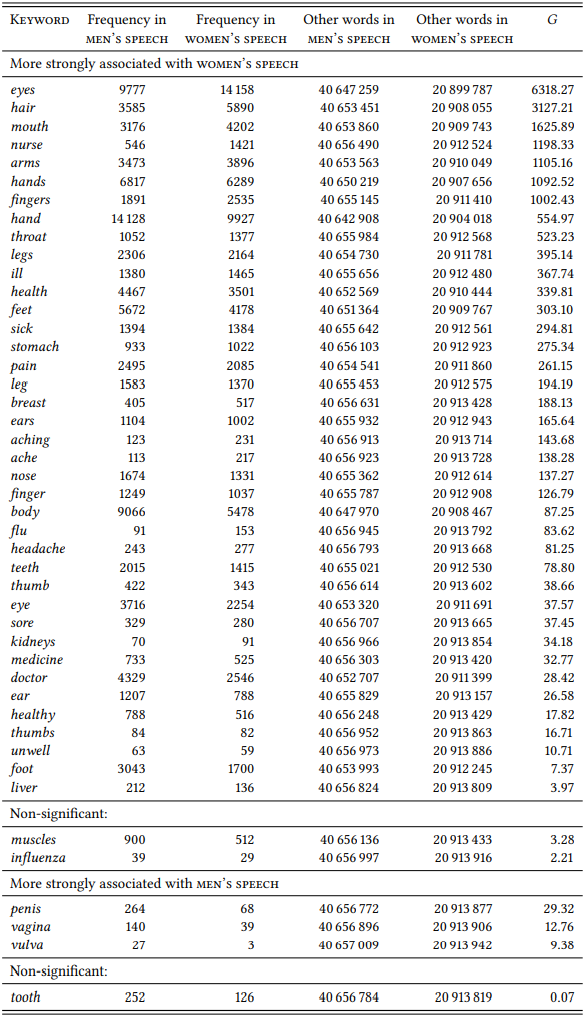
The larger sample supports Schmid’s initial conclusion, but even the larger sample is far from exhaustive. Still this case study has demonstrated that if we manage to come up with a justifiable selection of lexical items, a deductive keyword analysis can be used to test a particular hypothesis in an efficient and principled way.
10.2.3.2 Case study: An inductive approach to sex differences
An inductive design will give us a more complete and less biased picture, but also one that is much less focused. For example, Rayson et al. (1997), whose study inspired the one by Schmid discussed in the preceding section, apply inductive keyword analysis to the utterances with \(\mathrm{female \space vs. \space male}\) speaker information in the spoken-conversation subcorpus of the BNC (like Schmid, they simply follow the corpus creators’ implicit definition of \(\mathrm{Sex}\)). \(Table \text{ } 10.16\) shows the 15 most significant keywords im women’s speech and men’s speech (the results differ minimally from those in Rayson et al. (1997: 136–137), since they use the \(\chi^{2}\) statistic while we will use the \(G\) statistic again.
Two differences are obvious immediately. First, there are pronouns among the most significant keywords of women’s speech, but not of men’s speech, corroborating Schmid’s finding concerning personal reference. This is further supported if we include the next thirty-five most significant keywords, which contain three additional pronouns (him, he, and me) and eight proper names for women’s speech, but no pronouns and only a single proper name for men’s speech (although there are two terms of address, mate and sir). Second, there are three instances of cursing/taboo language among the most significant male keywords (fucking, fuck and Jesus), but not among female keywords, corroborating findings of a number of studies focusing on cursing (cf. Murphy 2009).
In order to find significant differences in other domains, we would now have to sort the entire list into semantic categories (as Leech & Fallon did for British and American English). This is clearly much more time-consuming than Schmid’s analysis of preselected items – for example, looking at the first fifty keywords in male and female speech will reveal no clear additional differences, although they point to a number of potentially interesting semantic fields (for example, the occurrence of lovely and nice as female keywords points to the possibility that there might be differences in the use of evaluative adverbs).
This case study, as well as the preceding one, demonstrates the use of keyword analyses with demographic variables traditionally of interest to sociolinguistics (see Rayson et al. 1997 for additional case studies involving age and social class, as well as interactions between sex, age and class). Taken together, they are also intended to show the respective advantages and disadvantages of deductive and inductive approaches in this area.
\(Table \text { } 10.16\): Keywords im women’s speech and men’s speech in the BNC conversation subcorpus
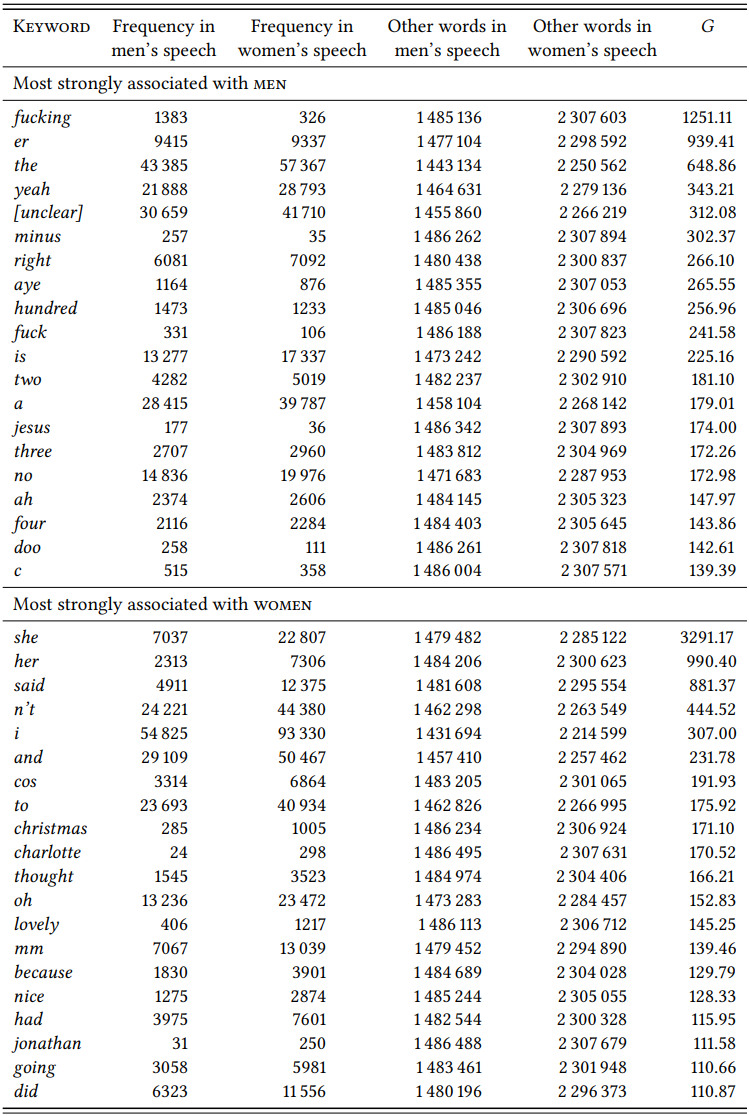
Note that one difficulty with sociolinguistic research focusing on lexical items is that topical differences in the corpora may distort the picture. For example, among the female keywords we find words like kitchen, baby, biscuits, husband, bedroom, and cooking which could be used to construct a stereotype of women’s language as being home- and family-oriented. In contrast, among the male keywords we find words like minus, plus, percent, equals, squared, decimal as well as many number words, which could be used to construct a stereotype of male language as being concerned with abstract domains like mathematics. However, these differences very obviously depend on the topics of the conversations included in the corpus. It is not inconceivable, for example, that male linguists constructing a spoken corpus will record their male colleagues in a university setting and their female spouses in a home setting. Thus, we must take care to distinguish stable, topic-independent differences from those that are due to the content of the corpora investigated. This should be no surprise, of course, since keyword analysis was originally invented to uncover precisely such differences in content.
10.2.4 Ideology
Just as we can choose texts to stand for demographic variables, we can choose them to stand for the world views or ideologies of the speakers who produced them. Note that in this case, the texts serve as an operational definition of the corresponding ideology, an operationalization that must be plausibly justified.
10.2.4.1 Case study: Political ideologies
As an example, consider Rayson (2008), who compares the election manifestos of the Labour Party and the Liberal Democrats for the 2001 general election in Great Britain in order to identify differences in the underlying ideologies.
\(Table \text { } 10.17\) shows the result of this direct comparison, derived from an analysis of the two party manifestos, which can be found online and which were converted into corpora with comparable tokenization for this case study (the tokenized versions are available in the Supplementary Online Material, file TXQP). The results differ from Rayson’s in a few details, due to slightly different decisions about tokenization, but they are identical with respect to all major observations.
Obviously, the names of each party are overrepresented in the respective manifestos as compared to that of the other party. More interesting is the fact that would is a keyword for the Liberal Democrats; this is because their manifesto
\(Table \text { } 10.17\): Differential collocates for the Labour and Liberal Democrat manifestos (2001)
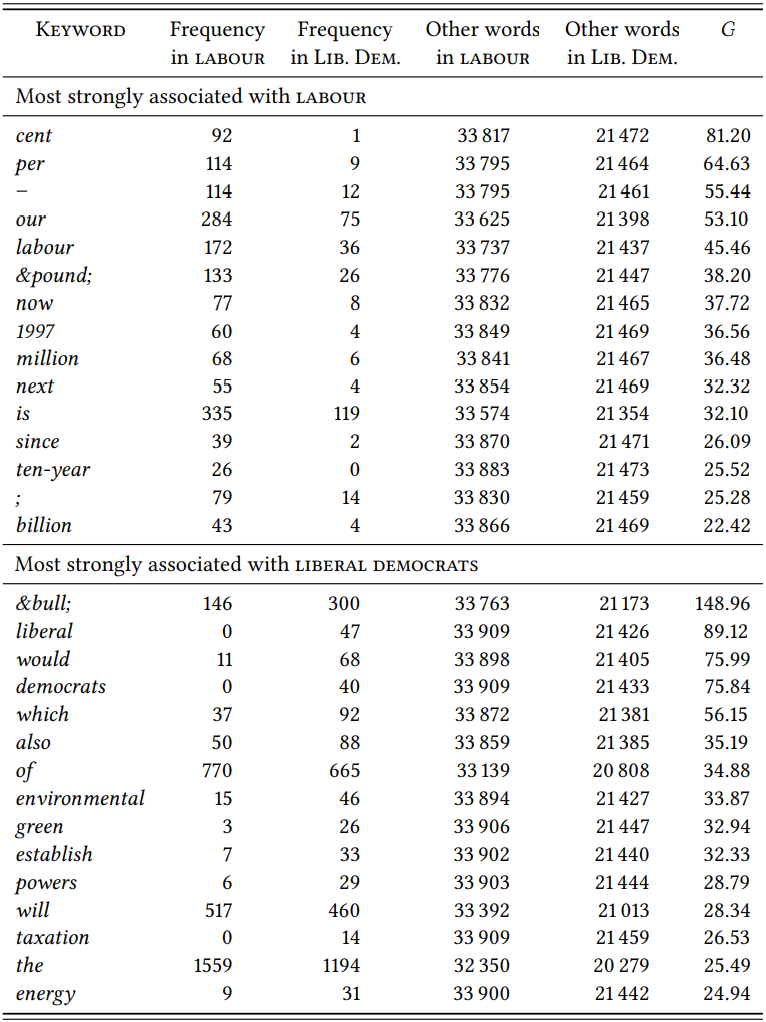
mentions hypothetical events more frequently, which Rayson takes to mean that they did not expect to win the election.
Going beyond Rayson’s discussion of individual words, note that the Labour manifesto does not have any words relating to specific policies among the ten strongest keywords, while the Liberal Democrats have green and environmental, pointing to their strong environmental focus, as well as powers, which, when we look at the actual manifesto, turns out to be due to the fact that they are very concerned with the distribution of decision-making powers. Why might this be the case? We could hypothesize that since the Labour Party was already in power in 2001, they might have felt less of a need than the Liberal Democrats to mention specific policies that they were planning to implement. Support for this hypothesis comes from the fact that the Liberal Democrats not only use the word would more frequently than Labour, but also the word will.
In order to test this hypothesis, we would have to look at a Labour election manifesto during an election in which they were not in power: the prediction would be that in such a situation, we would find words relating to specific policies. Let us take the 2017 election as a test case. There are two ways in which we could now proceed: We could compare the Labour 2017 manifesto to the 2001 manifesto, or we could simply repeat Rayson’s analysis and compare the 2017 manifestos of Labor and the Liberal Democrats. To be safe, let us do both (again, the 2017 manifestos, converted into comparable form, are found in the Supplementary Online Material, file TXQP).
\(Table \text { } 10.18\) shows the results of a comparison between the 2017 Labour and Liberal Democrat manifestos and \(Table \text{ } 10.19\) shows the results of the comparison between the 2001 and 2017 Labour manifestos. In both cases, only the keywords for the Labour 2017 manifesto are shown, since these are what our hypothesis relates to.
The results of both comparisons bear out the prediction: most of the significant keywords in the 2017 manifesto relate to specific policies. The comparison with the Liberal Democrat manifesto highlights core Labour policies, with words like workers, unions, women and workplace. The comparison with 2001 partially highlights the same areas, suggesting a return to such core policies between the 2001 “New Labour” era of Tony Blair and the 2017 “radical left” era of Jeremy Corbyn. The comparison also highlights the topical dominance of the so-called Brexit (a plan for the UK to leave the European Union): this is reflected in the word Brexit itself, but likely also in words like ensure, protect and protections, and businesses, which refer to the economic consequences of the so-called Brexit. Of course, the fact that our prediction is borne out does not mean that the hypothesis about
\(Table \text { } 10.18\): Differential collocates for the 2017 Labour manifesto (comparison to Liberal Democrats)
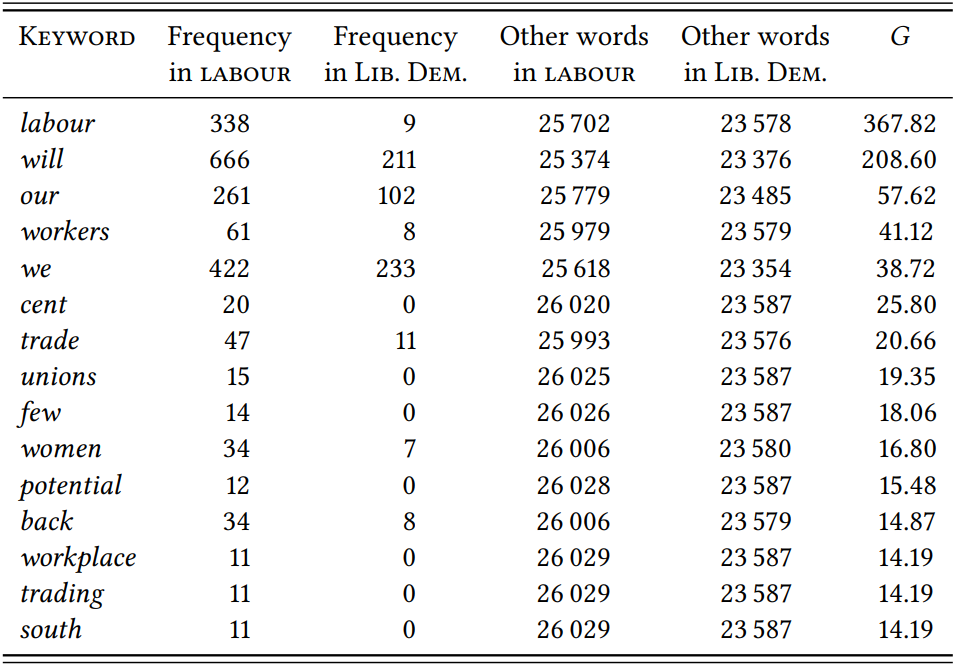
being or not being in power is correct. It could simply be that Labour was not particularly political in 2001 and has generally regained a focus on issues.
This case study has demonstrated that keyword analysis can be used to investigate ideological differences through linguistic differences. In such investigations, of course, identifying keywords is only the first step, to be followed by a closer analysis of how these keywords are used in context (cf. Rayson 2008, who presents KWIC concordances of some important keywords, and Scott 1997, who identifies collocates of the keywords in a sophisticated procedure that leads to highly insightful clusters of keywords).
One issue that needs consideration is whether in the context of a specific research design it is more appropriate to compare two texts potentially representing different ideologies directly to each other, as Rayson does, or whether it is more appropriate to compare each of the two texts to a large reference corpus, as the usual procedure in keyword analysis would be. In the first case, the focus will necessarily be on differences, as similarities are removed from the analysis by virtue of the fact that they will not be statistically significant – we could call
\(Table \text { } 10.19\): Differential collocates for the 2017 Labour manifesto (comparison to 2001)
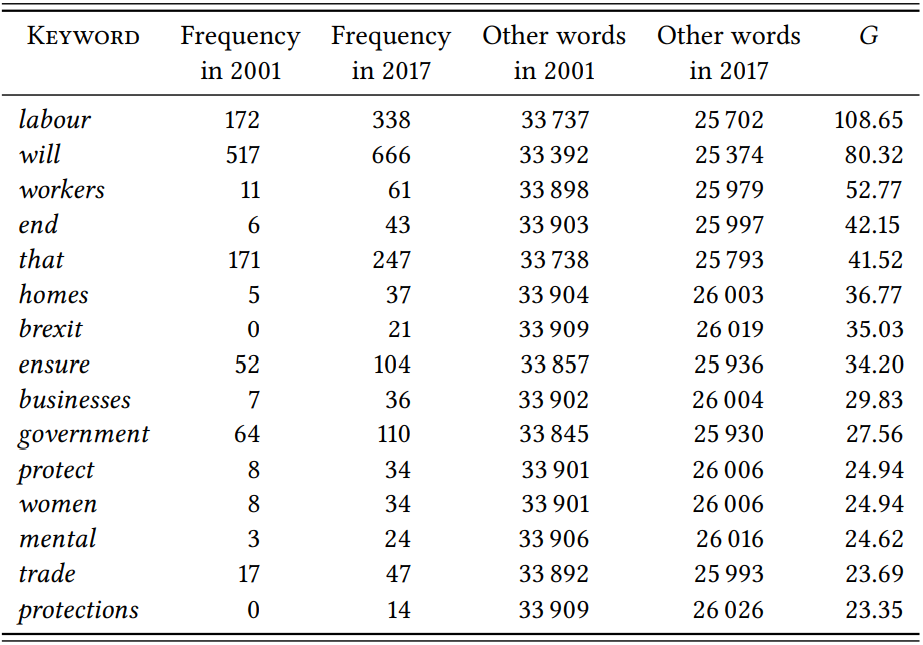
this procedure differential keyword analysis. In the second case, both similarities and differences could emerge; however, so would any vocabulary that is associated with the domain of politics in general. Which strategy is more appropriate depends on the aims of our study.
10.2.4.2 Case study: The importance of men and women
Just as text may stand for something other than a text, words may stand for something other than words in a given research design. Perhaps most obviously, they may stand for their referents (or classes of referents). If we are careful with our operational definitions, then, we may actually use corpus-linguistic methods to investigate not (only) the role of words in texts, but the role of their referents in a particular community.
In perhaps the first study attempting this, Kjellmer (1986) uses the frequency of masculine and feminine pronouns in the topically defined subcorpora of the LOB and BROWN corpora as an indicator of the importance accorded to women in the respective discourse domain. His research design is essentially deductive, since he starts from the hypothesis that women will be mentioned less frequently than men. The design has two nominal variables: \(\mathrm{Sex}\) (with the values \(\mathrm{man}\) and \(\mathrm{woman}\), operationalized as “male pronoun” and “female pronoun”) and \(\mathrm{Text \space Category}\) (with the values provided by the text categories of the LOB/BROWN corpora).
First, Kjellmer notes that overall, men are referred to much more frequently than women: There are 18 116 male pronouns in the LOB corpus compared to only 8366 female ones (Kjellmer’s figures differ very slightly from the ones given here and below, perhaps because he used an earlier version of the corpus). This difference between male and female pronouns is significant: using the single variable version of the \(\chi^{2}\) test introduced in Chapter 6, and assuming that the population in 1961 consisted of 50 percent men and 50 percent women, we get the expected frequencies shown in \(Table \text { } 10.20\) (\(\chi^{2}\) = 3589.70, (df = 1), \(p\) < 0.001).
\(Table \text { } 10.20\): Observed and expected frequencies of male and female pronouns in the LOB corpus (based on the assumption of equal proportions)
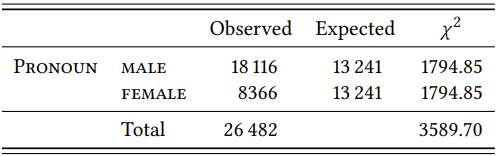
In other words, women are drastically underrepresented among the people mentioned in the LOB corpus (in the BROWN corpus, Kjellmer finds, things are even worse). We might want to blame this either on the fact that the corpus is from 1961, or on the possibility that many of the occurrences of male pronouns might actually be “generic” uses, referring to mixed groups or abstract (categories of) people of any sex. However, Kjellmer shows that only 4 percent of the male pronouns are used generically, which does not change the imbalance perceptibly; also, the FLOB corpus from 1991 shows almost the same distribution of male and female pronouns, so at least up to 1991, nothing much changed in with respect to the underrepresentation of women.
Kjellmer’s main question is whether, given this overall imbalance, there are differences in the individual text categories, and as \(Table \text { } 10.21\) shows, this is indeed the case.
Even taking into consideration the general overrepresentation of men in the corpus, they are overrepresented strongly in reportage and editorials, religious
\(Table \text { } 10.21\): Male and female pronouns in the different text categories of the LOB corpus
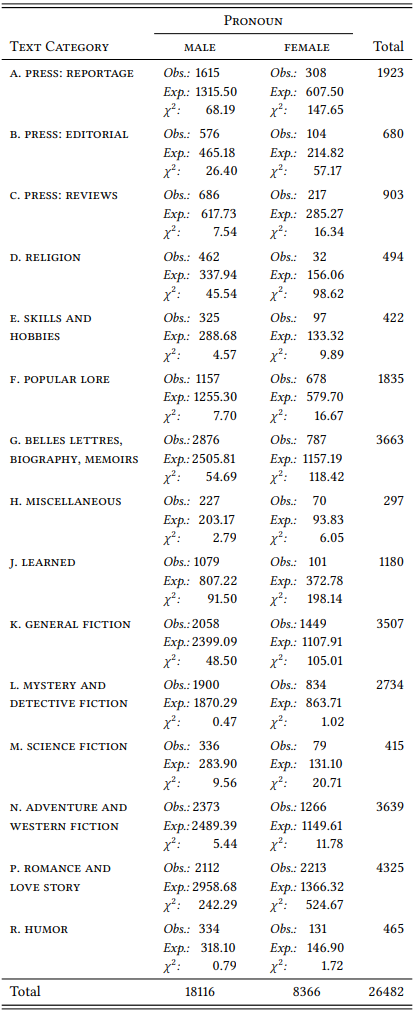
writing and belles-lettres/biographies – all “factual” language varieties, suggesting that actual, existing men are simply thought of as more worthy topics of discussion than actual, existing women. Women, in contrast, are overrepresented in popular lore, general fiction, adventure and western, and romance and love stories (overrepresented, that is, compared to their general underrepresentation; in absolute numbers, they are mentioned less frequently in every single category except romance and love stories). In other words, fictive women are slightly less strongly discriminated against in terms of their worthiness for discussion than are real women.
Other researchers have taken up and expanded Kjellmer’s method of using the distribution of male and female pronouns (and other gendered words) in corpora to assess the role of women in society (see, e.g. Romaine 2001, Baker 2010b; Twenge et al. 2012 and the discussion of their method by Liberman 2012, and Subtirelu 2014).
10.2.5 Time periods
10.2.5.1 Case study: Verbs in the going-to future
Just as we can treat speech communities, demographic groups or ideologies as subcorpora which we can compare using keyword analysis or textually differential collexeme analysis, we can treat time periods as such subcorpora. This allows us to track changes in vocabulary or in lexico-grammatical associations. This procedure was first proposed by Martin Hilpert and applied comprehensively in Hilpert (2008) to investigate future tense constructions in a range of Germanic languages.
Let us take the English going-to future as an example and study potential changes in the verbs that it occurs with during the 18th and 19th centuries, i.e. in the centuries when, as shown in Case Study 8.2.5.3 in Chapter 8, it first grammaticalized and then rose drastically in terms of discourse frequency.
For Present-Day English, Gries & Stefanowitsch (2004) confirm in a differential collexeme analysis the long-standing observation that in a direct comparison of the going-to future and the will future, the former tends to be associated with verbs describing intentional, dynamic and often very specific activities, while the latter is preferred for non-agentive, low-dynamicity processes and states. This makes sense given that the going-to future probably derived from phrases describing people literally going to some location in order to do something. Since despite these preferences, the going-to future can be used with processes and states in Present-Day English, we might expect to see a development, with the construction being more strongly restricted to activities in earlier periods and then relaxing these restrictions somewhat over time.
Let us first compare the newly emerged going-to future against the established will future for each period individually, i.e. by applying a standard differential collexeme analysis. Let us use the Corpus of Late Modern English Texts (CLMET) already used in Case Study 8.2.5.3. In addition to providing the year of publication for most texts, this corpus also provides a categorization into three periods that cover precisely the time span we are interested in: 1710–1780, 1780–1850 and 1850– 1920 (note that the periods overlap, but this is presumably just an error in the metadata for the corpus).
\(Table \text{ } 10.22\) shows the top ten differential collexemes for the going-to future (some collexemes were removed since they were clearly mistagged nouns, namely bed (5:0, \(G\) = 34.38) in Period 1, bed (12:0, \(G\) = 80.00), sleep (11:11, \(G\) = 43.62), work (10:32, \(G\) = 22.86) and supper (4:0, \(G\) = 27.5) in Period 2, and sleep (27:9, \(G\) = 100.52) and bed (15:0, \(G\) = 77.31) in Period 3 (the raw data for the studies in this section are available in the Supplementary Online Material: Q8DT).
In all three periods, there is a clear preference for activities. In Period 1, all of the top ten verbs fall into this category (relate here being used exclusively in the sense of ‘tell’, as in ...when my Tranquillity was all at once interrupted by an Accident which I am going to relate to you (CLMET 86)). In Period 2, we see a few cases of process and state verbs, namely faint, reside, and possibly begin. This trend continues in Period 3, with the process and state verbs happen, live and cry. This generally corroborates our expectation about the development of the construction (see also Hilpert (2008: 119) for very similar results).
Let us now turn to the direct comparison of diachronic periods proposed and pioneered by Hilpert. As mentioned above, Hilpert (2008) uses the multinomial test to compare three (or more) periods directly against each other. Let us instead compare the three periods pairwise (Period 1 and Period 2, and Period 2 and Period 3). This allows us to use the standard keyword analysis introduced in Section 10.2.1.2 above.
\(Table \text{ } 10.23\) shows the result of the comparison of the first two periods. The top 15 texually differential collexemes are shown for both periods, because in both cases there are significant collexemes that share the same rank so that there is no natural cutoff point before rank 15 (again, two words were removed because they were mistagged nouns, namely ruin (6:1, \(G\) = 4.55) and decay (3:0, \(G\) = 4.5), both from Period 1).
The results are less clear than for the individual differential collexeme analyses presented in \(Table \text { } 10.22\): both periods have process and state verbs among the top textually differential collexemes (cry, decay and arguably wait in the first
\(Table \text { } 10.22\): Differential collexemes of the going-to future compared to the will-future in three time periods of English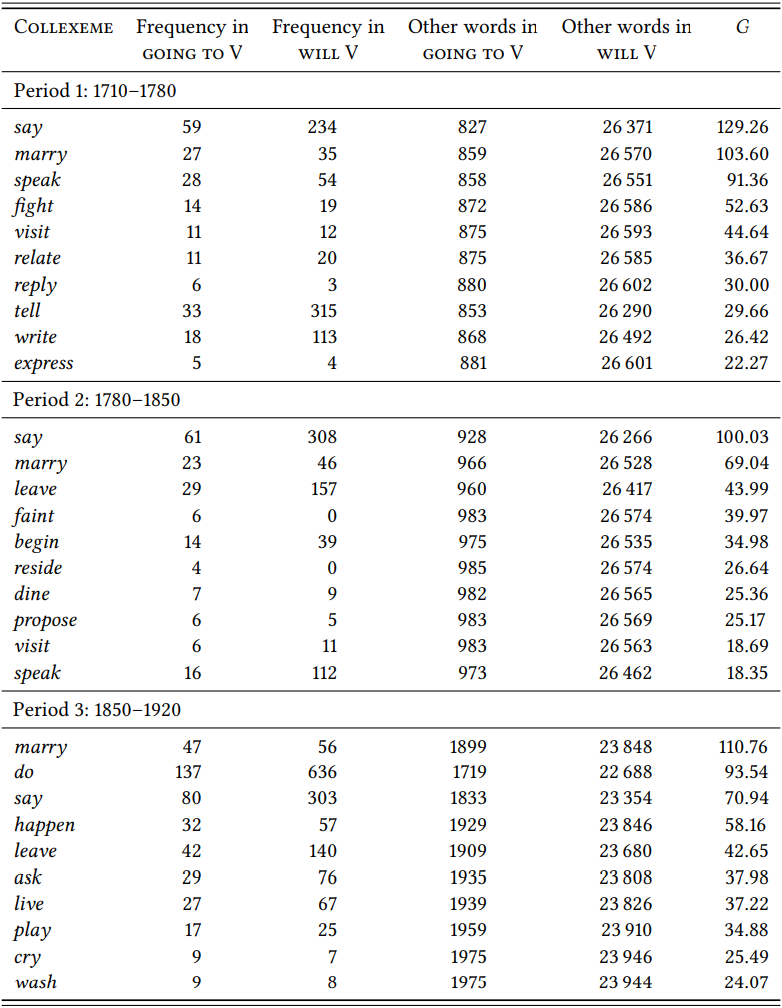
\(Table \text { } 10.23\): Textually differential collexemes of the going-to future in 1710–1780 vs. 1780–1850
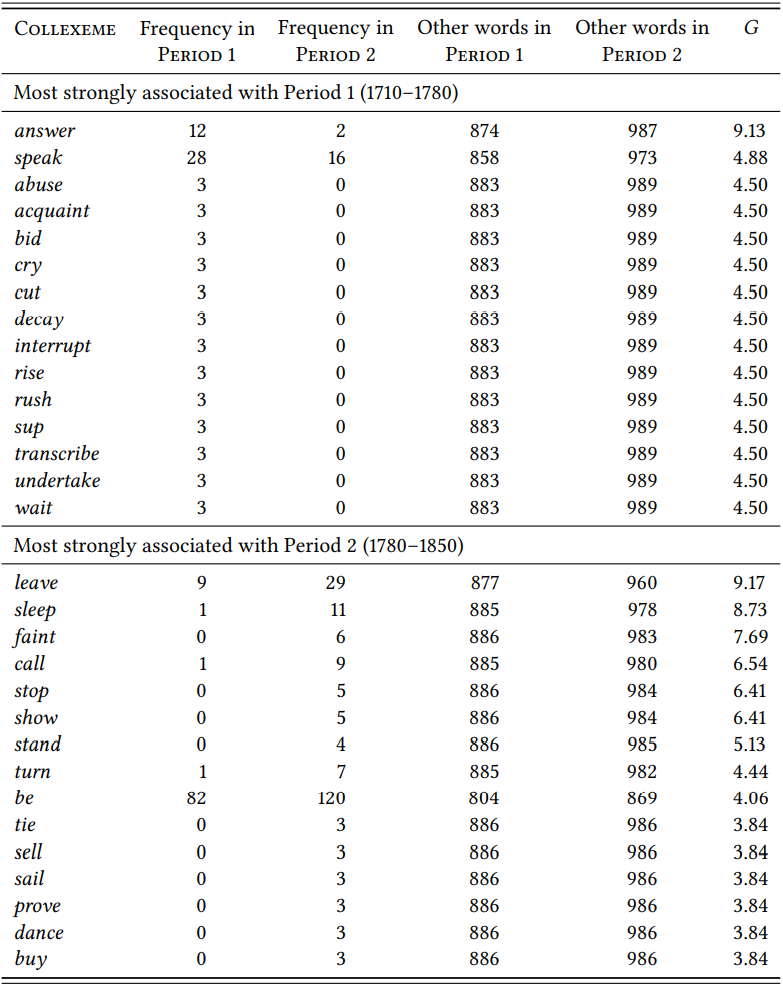
period and sleep, faint, be and arguably stand in the second period). Still, it might be seen as corroboration of our expectation that the very non-agentive be is a significant collexeme for the second period.
\(Table \text { } 10.24\) shows the results for a direct comparison of the second against the third period.
\(Table \text { } 10.24\): Textually differential collexemes of the going-to future in 1780–1850 vs. 1850–1920
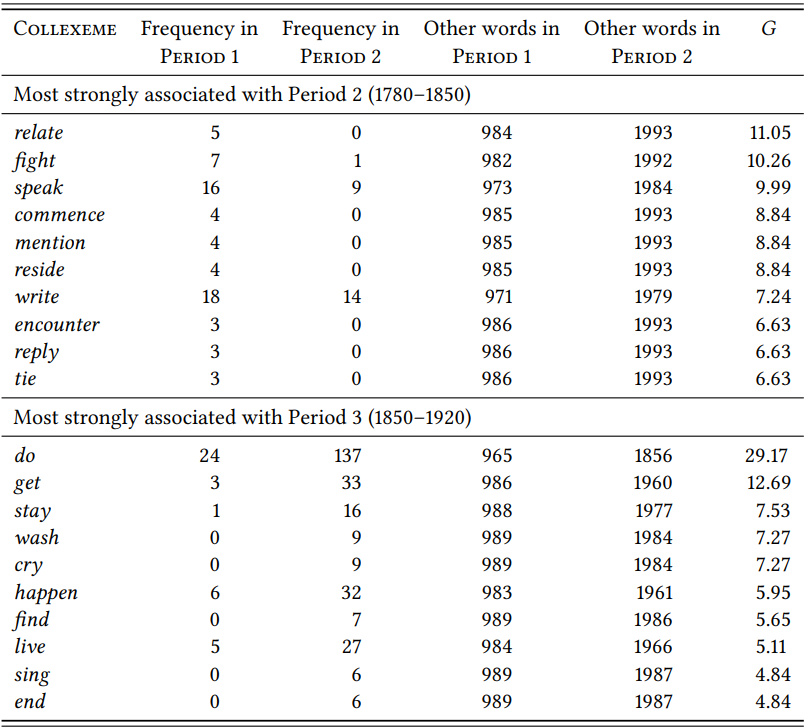
Here, the results are somewhat clearer: While the second period now has just one potential non-agentive verb (reside), the third period has five (cry, happen, live, end and arguably stay).
This case study is meant to demonstrate the use of collostructional analysis and keyword analysis, specifically, textual differential collexeme analysis, as a method for diachronic linguistics. Both approaches – separate analyses of successive periods or direct (pairwise or multinomial) comparisons of successive periods – can uncover changes in the association between grammatical constructions and lexical items, and thereby in the semantics of constructions. The separate analysis of successive periods seems conceptually more straightforward (cf. Stefanowitsch 2006a for criticism of the direct comparison of historical periods), but the direct comparison can be useful in that it automatically discards similarities between periods and puts differences in sharp focus.
10.2.5.2 Case study: Culture across time
As has become clear, a comparison of speech communities often results in a comparison of cultures, but of course culture can also be studied on the basis of a corpus without such a comparison. Referents that are important in a culture are more likely to be talked and written about than those that are not; thus, in a sufficiently large and representative corpus, the frequency of a linguistic item may be taken to represent the importance of its referent in the culture. This is the basic logic behind a research tradition referred to as “culturomics”, a word that is intended to mean something like “rigorous quantitative inquiry to a wide array of new phenomena spanning the social sciences and the humanities” (Michel et al. 2011: 176). In practice, culturomics is simply the application of standard corpuslinguistic techniques (word frequencies, tracked across time), and it has yielded some interesting results (if applied carefully, which is not always the case).
Michel et al. (2011) present a number of small case studies intended to demonstrate the potential of culturomics. They use the Google Books corpus, a large collection of \(n\)-grams ranging from single words to 5-grams, derived from the Google Books archive and freely available for download to anyone with enough patience and a large enough hard disk (see Study Notes).
The use of the Google Books archive may be criticized because it is not a balanced corpus, but the authors point out that first, it is the largest corpus available and second, books constitute cultural products and thus may not be such a bad choice for studying culture after all. These are reasonable arguments, but if possible, it seems a good idea to complement any analysis done with Google Books with an analysis of a more rigorously constructed balanced corpus.
As a simple example, consider the search for the word God in the English part of the Google Books archive, covering the 19th and 20th centuries. I used the 2012 version of the corpus, so the result differs very slightly from theirs. I also repeated the analysis using the Corpus of Historical American English (COHA), which spans more or less the same period.
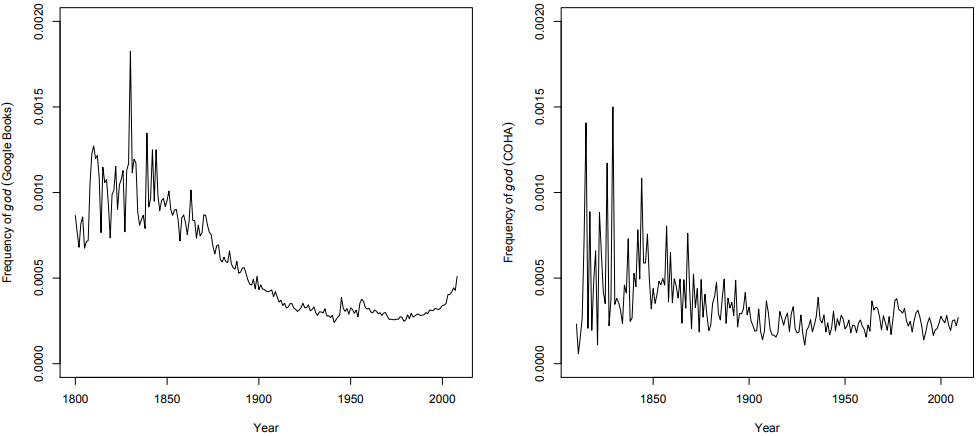
\(Figure \text { } 10.1\): God in English Books and in COHA
Clearly, the word God has decreased in frequency – dramatically so in the Google Books archive, slightly less dramatically so in COHA. The question is what conclusions to draw from this. The authors present it as an example of the “history of religion”, concluding from their result somewhat flippantly that “‘God’ is not dead but needs a new publicist”. This flippancy, incidentally, signals an unwillingness to engage with their own results in any depth that is not entirely untypical of researchers in culturomics.
Broadly speaking the result certainly suggests a waning dominance of religion on topic selection in book publishing (Google Books), and slightly less so in published texts in general (COHA). This is not surprising to anyone who has paid attention for the last 200 years; more generally, it is not surprising that the rise and fall in importance of particular topics is reflected in the frequency of the vocabulary used to talk and write about these topics, but the point of this case study was mainly to demonstrate that the method works.
While it is not implausible to analyze culture in general on the basis of a literary corpus, any analysis that involves the area of publishing itself will be particularly convincing. One such example is the use of frequencies to identify periods of censorship in Michel et al. (2011). For example, they search for the name of the Jewish artist Marc Chagall in the German and the US-English corpora. As \(Figure \text { } 10.2\) shows, there is a first peak in the German corpus around 1920, but during the time of the Nazi government, the name drops to almost zero while it continues to rise in the US-English corpus.
The authors plausibly take this drastic drop in frequency as evidence of political censorship – Chagall’s works, like those of other Jewish artists, were declared
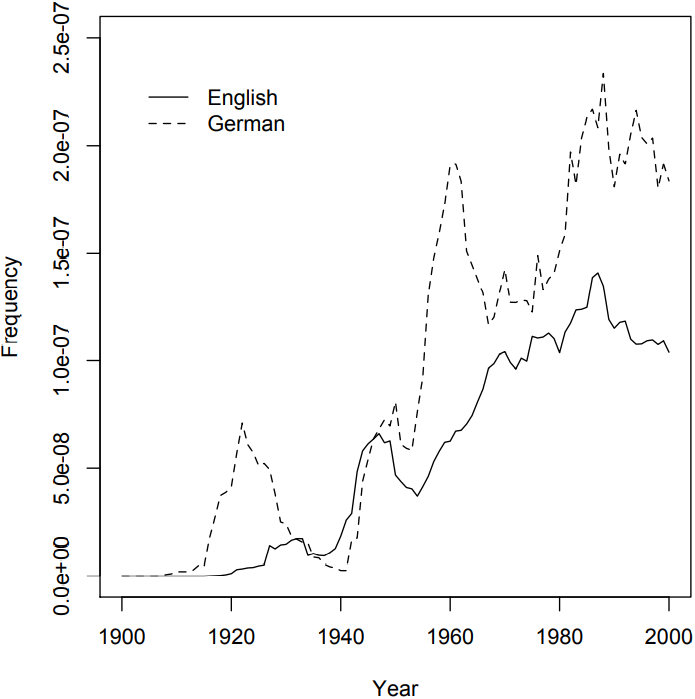
\(Figure \text { } 10.2\): The name Marc Chagall in the US-English and the German parts of the Google Books corpus
to be “degenerate” and confiscated from museums, and it makes sense that his name would not be mentioned in books written in Nazi Germany. However, the question is, again, what conclusions to draw from such an analysis. Specifically, we know how to interpret the drop in frequency of the name Marc Chagall during the Nazi era in Germany because we know that Marc Chagall’s works were banned. But if we did not know this, we would not know how to interpret the change in frequency, since words, especially names, may rise or fall in frequency for all kinds of reasons.
Consider the following figure, which shows the development of the frequency of the name Karl Marx in the German and English Google Books archive (extracted from the bigram files downloaded from the Google Books site, see Supplementary Online Material, file CUBF). Note the different frequency scales – the name is generally much more frequent in German than in English, but what interests us are changes in frequency.
Again, we see a rise in frequency in the 1920s, and then a visible decrease during the Nazi era from 1933 to 1945. Again, this can plausibly be seen as evidence
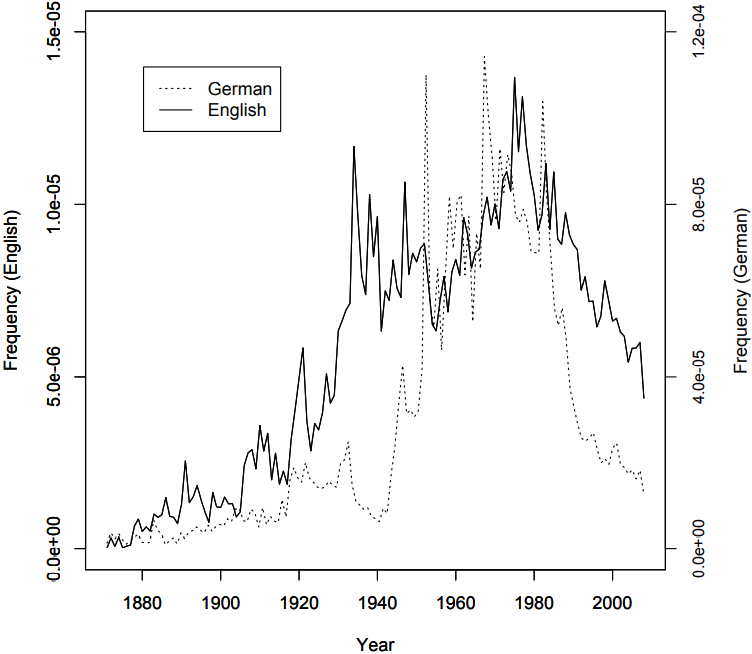
\(Figure \text { } 10.3\): The name Karl Marx in the English and the German parts of the Google Books corpus
for censorship in Nazi Germany. Plausibly, because we know that the Nazis censored Karl Marx’s writings – they were among the first books to be burned in the Nazi book burnings of 1933. But what about other drops in frequency, both in English and in German? There are some noticeable drops in frequency in English: after 1920, between 1930 and 1940 (with some ups and downs), and at the beginning of the 1950s. Only the latter could plausibly be explained as the result of (implicit) censorship during the McCarthy era. Finally, the frequency drops massively in both languages after 1980, but there was no censorship in either speech community. A more plausible explanation is that in the 1980s, neoliberal capitalism became a very dominant ideology, and Marx’s communist ideas simply ceased to be of interest to many people (if this explanation is correct, we might see the frequency of the name rise again, given the current wide-spread disillusionment with neoliberalism).
Thus, the rise and fall in frequency cannot be attributed to a particular cause without an investigation of the social, economic and political developments during the relevant period. As such, culturomics can at best point us towards potentially interesting cultural changes that then need to be investigated in other 39510 Text disciplines. At worst, it will simply tell us what we already know from those other disciplines. In order to unfold their potential, such analyses would have to be done at a much larger scale – the technology and the resources are there, and with the rising interest in digital humanities we might see such large-scale analyses at some point.
_____________________
2More precisely, in its generalized form, this coefficient is calculated by the following formula, given two corpora A and B: \(\frac{\frac{f\left(\text { word }_{A}\right)}{\operatorname{size}_{A}}-\frac{f\left(\text { word }_{B}\right)}{\operatorname{size}_{B}}}{\frac{f\left(\text { word }_{A}\right)}{\text { size }_{A}}+\frac{f\left(\text { word }_{B}\right)}{\text { size }_{B}}}\)
This formula will give us the percentage of uses of the word in Corpus A or Corpus B (whichever is larger), with a negative sign if it occurs in Corpus B.