Listen to this phrase in Amharic, meaning 'he finished carefully'. See what consonants sounds you can pick out that do not occur in English.
Recall how vowel phonemes in different languages differ from each other. One possibility is that one of the vowel dimensions may be organized differently. For example, the backness dimension has two contrastive values (front and back) in Spanish and Japanese but three contrastive values (front, central, and back) in English (and Amharic). A second possibility is that there is a gap in one system that is filled in the other. For example, Spanish and Japanese have low vowels and front vowels, but they have no low front vowel (/æ/), whereas English does have such a vowel. A third possibility is that one language may use a dimension contrastively which is not used contrastively at all in other languages. Thus the dimension of tenseness distinguishes English vowels from one another (/i/ from /ɪ/ and /u/ from /ʊ/), while this dimension is irrelevant for Spanish and Japanese vowels.
Organization of dimensions
As with vowels, a language may make fewer distinctions on a given dimension than other languages make. Consider Lingala, which, like English, has bilabial, alveolar, and velar stops, nasals, and fricatives, but, unlike English, Spanish, Japanese, Amharic, and Tzeltal, makes no use of the postalveolar place of articulation. That is, Lingala has no phonemes like /č/, /ǰ/, /š/, and /ž/.
Another possibility is that two languages make the same number of distinctions along a dimension but not the same distinctions. Consider place of articulation for stops, affricates, and nasals. English stops, affricates, and nasals (other than the marginal glottal stop) appear at four places of articulation: bilabial (/p/, /b/, /m/), alveolar (/t/, /d/, /n/), postalveolar (/č/, /ǰ/), and velar (/k/, /g/, /ŋ/). Spanish and Japanese also have stops and affricates at four different positions, and three of these are roughly the same as for English, but alveolar is replaced by dental place of articulation, that is, with the tongue tip against the upper teeth rather than against the alveolar ridge. (Recall that English has fricatives at this place of articulation (/θ/, /ð/), but no stops or nasals.) When we are concerned only about the phonemes within a language, we can use the same symbols that we use for the English alveolar phonemes — /t/, /d/, /n/ — for the dental phonemes in these languages because it is not to make sure each phone is kept distinct from every other. However, when it is important to make it clear that the place of articulation is dental rather than alveolar, I will use the IPA symbols [t̪], [d̪], [n̪]. See if you can hear the difference between the alveolar and dental places of articulation in the following syllables: [tata], [t̪at̪a], [dada], [d̪ad̪a].
Now consider voicing. Recall that English consonants are either voiced, with voicing during the production of the consonant, or voiceless, with voicing beginning after or ending before (or simultaneously with) the consonant. Spanish also has voiced and voiceless consonants, but it differs in the details. Listen to your pronunciation of the word pie. The lips are brought together for the /p/. Next the lips are opened with a kind of explosive puff of air (which you can feel if you put your hand in front of your mouth). Then the vocal cords begin to vibrate and the vowel /ay/ is produced. Now listen to the pronunciation of the Spanish word pai, a word borrowed from English with the meaning 'pie': /pai/. The consonant at the beginning sounds something like English /p/, but the release of the lip closure and the beginning of voicing happen almost simultaneously for Spanish, and there is no puff of air. We call the English voiceless stop in pie aspirated, and when we need to distinguish it from consonants like those in Spanish, we use [h] following the consonant symbol, for example, [ph]. So if we want to show the detailed pronunciations of the English and Spanish words, we would write them [phay] and [pay] respectively.
As in English, the Spanish /p/ is distinct from its voiced counterpart, /b/, as in the word vaya, pronounced /baya/. That is, Spanish and English both make a two-way distinction in voicing. The pattern that holds for /p/ and /b/ in the two languages also holds for the other stops and affricates. So English /t/ is aspirated, while Spanish /t/ is not; English /k/ is aspirated, while Spanish /k/ is not. In brief, then, both English and Spanish have voiced and voiceless stops, but for Spanish voiceless stops there is no lag between the release and the voicing as there is for English voiceless stops.
We can see that the voicing dimension is really a continuous dimension with many different possibilities for the relative timing of the release of the consonant closure and the voicing. When we think of voicing in this way, the dimension is sometimes called voice onset time. Voice onset time is illustrated for three bilabial stops in the figure below. The top line shows the closure (single line) and opening (double line) of the lips. Each of the three other lines shows when voicing begins relative to the opening of the lips (the dashed vertical line) for three different stops, [ph], as in English pie; [p], as in Spanish pie; and [b], as in English buy and Spanish vaya.
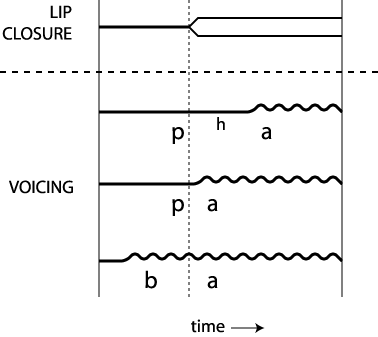
The figure shows only three of many possible times for voicing to begin. But both English and Spanish have exactly two categories along this continuum. This means that English and Spanish hearers perceive discontinuity where there is continuity. An English hearer would perceive some of the cases as /p/ and some as /b/. The differences between the different /p/ cases and the differences between the different /b/ cases might not be perceived at all; the /p/s and the /b/s would tend to sound the same. At the same time, the differences between the /p/s and the /b/s would be exaggerated; they would tend to sound more different than they actually are. This phenonemon is referred to as categorical perception. Both Spanish and English hearers experience categorical perception for voice onset time, but the line dividing their categories is in different places. As we will see in the section on phonetic contexts, the situation in English is somewhat more complicated than what we've seen so far; English speakers actually produce a range of voiceless stops that include ones like the Spanish voiceless stops.
You should not be surprised to know that other languages divide up the voice onset time dimension differently from English or Spanish. In Mandarin Chinese there is also a two-way distinction for stops (and affricates), but the distinction is between voiceless aspirated stops (like English [ph]) and voiceless unaspirated stops (like Spanish [p]). In problems later on, we will see how other languages treat voice onset time.
What about manner of articulation, the third major dimension distinguishing consonants? While all languages make use of different manners of articulation, some make use of more possibilities. Recall that to some extent, manner of articulation can be seen as a collection of possible ways of configuring the vocal tract to produce sounds. The possibilities we have seen are stops, fricatives, affricates, nasals, and approximants, including lateral approximants.
There are two other possibilities that involve bringing the articulators into contact, as for stops and affricates. For stops and affricates the articulators are brought together and held there till the release. A different approach is for one articulator to quickly tap against the other but not remain in contact with it. This is known as a tap. This is the manner of articulation used for the second consonant in the Spanish word pero 'but'. For this consonant, the tip of the tongue strikes the alveolar ridge quickly but does not remain there. A similar sound is also used in Japanese and Amharic. When we need to distinguish this tap from other r-like sounds, I will use the symbol [ɾ] for this purpose.
The other possibility is for one articulator to be brought quickly in contact with the other several times in succession. This is known as a trill. This is the manner of articulation used for the second consonant in the Spanish word perro 'dog'. The place of articulation is the same as for [ɾ], but in this case the tongue strikes the alveolar ridge several times. A similar sound is also used in Amharic; it appears in the Amharic phrase referred to in the box at the beginning of this section. The usual IPA symbol for the alveolar trill is [r], but we can also use a double [r] for this purpose to distinguish it from a tap when this is necessary. With this notation, the pronunciation of the Spanish word perro is written /perro/.
Gaps
Now consider how some languages fill the gaps of other languages. Notice that in the alveolar place of articulation, English has stops, fricatives, and a nasal. In the bilabial place of articulation, it has stops and a nasal but no fricatives, though there are fricatives in the nearby labiodental place of articulation. In the velar place of articulation, English has stops and a nasal but no fricatives in this or any nearby position. Notice also that while English has bilabial, alveolar, and velar nasals, it has no nasal phoneme in the postalveolar or palatal places of articulation.
These last two gaps are filled in Spanish. Spanish has a voiceless velar fricative, the consonant in the middle of the word México. This sound is symbolized by /x/, so the pronunciation of the word México is written /mexiko/. Spanish also has a palatal nasal, the consonant in the middle of the word año 'year'. This consonant is symbolized in this book by /ɲ/, so the pronunciation of the word año is written /aɲo/. But Spanish has gaps of its own. There is no velar nasal phoneme, a gap which is filled by the English phoneme /ŋ/. And while Spanish has a postalveolar affricate (/č/), it has no postalveolar fricative (/š/), unlike English, Japanese, Amharic, and Tzeltal.
New dimensions
Just as for vowels, one language may make use of a consonant dimension which other languages do not. Two of the languages on our list, Amharic and Tzeltal, have an alternate way of producing stops and affricates. This mode of production involves a buildup of pressure behind the point of contact and an explosive release accompanied by a glottal stop; such consonants are referred to as ejective consonants. I will use a following apostrophe to indicate these sounds and will refer to this dimension as glottalization. (Note that we have to consider this a new dimension rather than just a new value for manner of articulation because it is possible with different manners of articulation; there are glottalized stops, fricatives, affricates, and sonorants in different languages.)
Listen to the following contrasts, and see if you can hear the difference between ejectives and plain, non-glottalized stops and affricates: [papa], [p'ap'a], [tata], [t'at'a], [kaka], [k'ak'a], [čača], [č'ač'a]. Glottalization is used contrastively in Amharic and Tzeltal. That is, the sounds /t'/, /č'/, and /k'/ are used, like /t/, /č/, and /k/, to make distinct words in these languages. Three of these sounds appear in the Amharic phrase mentioned in the box at the beginning of this section, which it may be worth transcribing now: /bεt'ɪnɪkk'ak'e c'εrrεsε/. To show that glottalization is contrastive in Amharic, we can cite pairs like /kok/ 'peach' vs. /k'ok'/ 'partridge' and /tɪl/ 'worm' vs. /t'ɪl/ 'quarrel'.
This section has not been a complete survey of possible consonants in human languages, or even in the ten languages discussed in this book. There are other places of articulation, other manners of articulation, and even other dimensions. The point has been to show how consonant systems differ along the basic dimensions of place of articulation and manner of articulation and what all languages share: a small set of phonemes produced with different kinds of constrictions within the vocal tract. In the next section we'll see how these consonant phonemes are combined with the vowel phonemes we discussed earlier to form syllables and how languages resemble and differ from each other in how this is done.

