
7.2: Vision
- Page ID
- 133852
This page is a draft and under active development. Please forward any questions, comments, and/or feedback to the ASCCC OERI (oeri@asccc.org).
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Vision
- Identify the key structures of the eye and the role they play in vision.
- Summarize how the eye and the visual cortex work together to sense and perceive the visual stimuli in the environment, including processing colors, shape, depth, and motion.
- Explain the benefit of having two eyes.
- Understand differences in color vision.
- Understand depth perception and vision.
- Understand motion detection.
Humans rely largely on vision and seeing the world around them through sight. Most non human organisms rely more on the other senses to interpret the world around them. Research indicates that a large part of the cerebral cortex in humans is dedicated to vision. As the information reaches the visual cortex in the brain, multiple neurons identify shapes, colors, and motions. When light falls on the eyes, sensory receptors begin the process of transduction. As this process occurs, individuals begin to perceive the environment around them.
Think about entering a dark theater or room if you have been outside on a sunny day; often times it takes time to adjust to the change of light intensity in the environment. The muscles in the iris of the eye adjust to allow more light to enter the pupil (the round opening in the center of the iris). The iris of the eye is the colored part of the eye that constricts and dilates the pupil to adjust for different light intensities that we may encounter throughout the day. Photoreceptors help distinguish the different characteristics of different objects. The types of photoreceptors in the human eye include rods and cones; rods are typically more prevalent than cones. Rods give us sensitivity under dim lighting conditions and allow us to see at night. Cones allow us to see fine details in bright light and give us the ability to distinguish color. Cones are tightly packed around the fovea (the small central region located at the back of the retina) and more sparsely elsewhere. Rods populate the periphery (the region surrounding the fovea) and are almost absent from the fovea. As organisms move about their environment throughout the day the information by light from objects both near and far is encoded by the brain and the identification of colors, shapes, and motion occurs (see Figure \(\PageIndex{1}\)).
Anatomy of the Human Eye
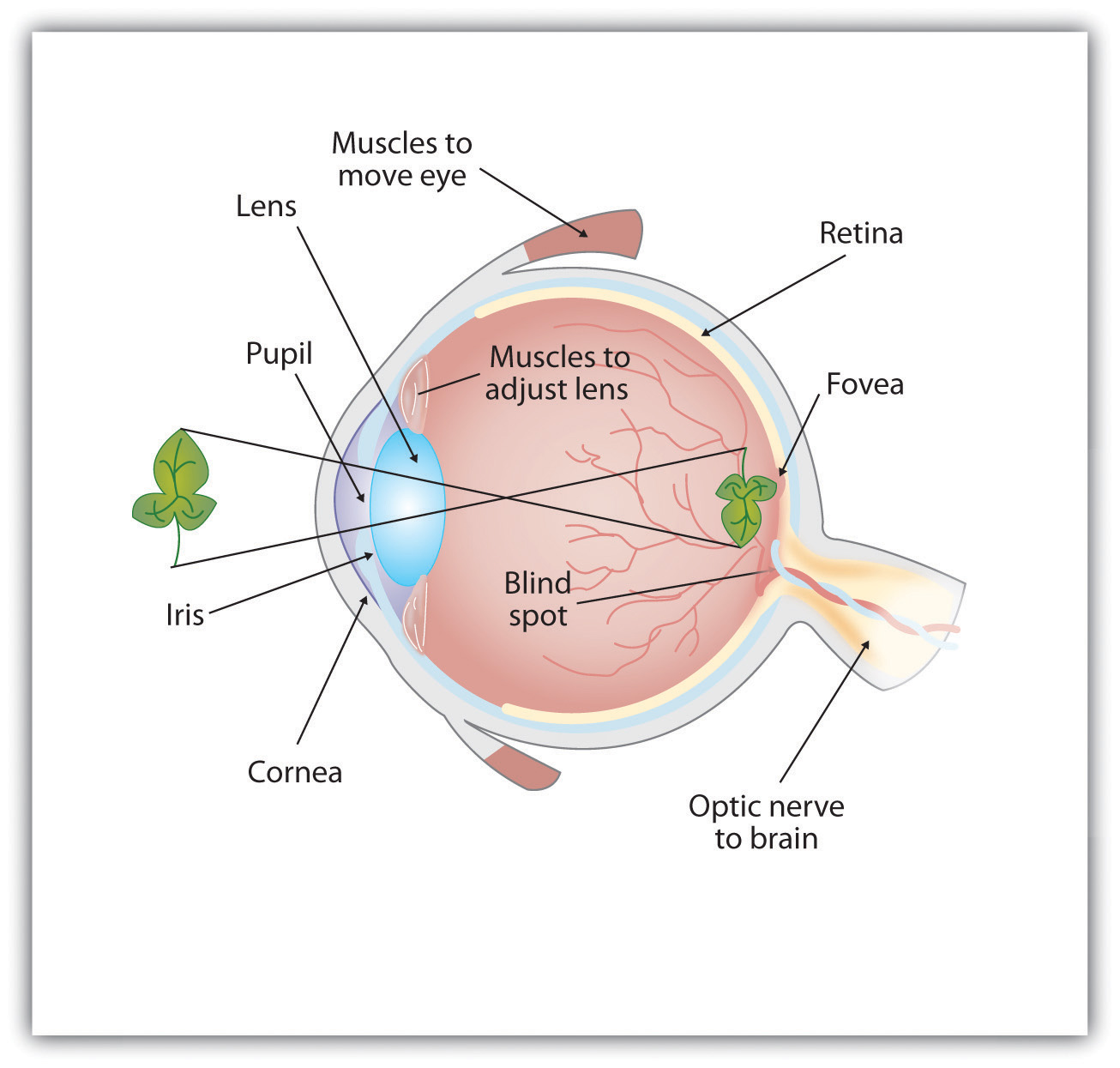
Figure \(\PageIndex{1}\): Light enters the eye through the transparent cornea, passing through the pupil at the center of the iris. The lens adjusts to focus the light on the retina, where it appears upside down and backward. Receptor cells on the retina send information via the optic nerve to the visual cortex. https://open.lib.umn.edu/intropsyc/c...04_s02_s01_f02
Normal, Nearsighted, and Farsighted Eyes Figure \(\PageIndex{2}\)

Figure \(\PageIndex{2}\) For people with normal vision (left), the lens properly focuses incoming light on the retina. For people who are nearsighted (center), images from far objects focus too far in front of the retina, whereas for people who are farsighted (right), images from near objects focus too far behind the retina. Eyeglasses solve the problem by adding a secondary, corrective, lens. https://open.lib.umn.edu/intropsyc/chapter/4-2-seeing/#stangor-ch04_s02_s01_f02
Research indicates that humans can distinguish between millions of different color variations (Gerald , 1972). Although humans can distinguish between a wide variety of variations there are three primary colors that form the base of these variations; red, green, and blue. The ability for these colors to form these variations is based on the hue or shade of the colors. The electromagnetic spectrum illustrated below shows that visible light for humans is just a small slice of the entire spectrum, which includes radiation that we cannot see as light because it is below the frequency of visible red light and above the frequency of visible violet light.
The Electromagnetic Spectrum Figure \(\PageIndex{3}\)
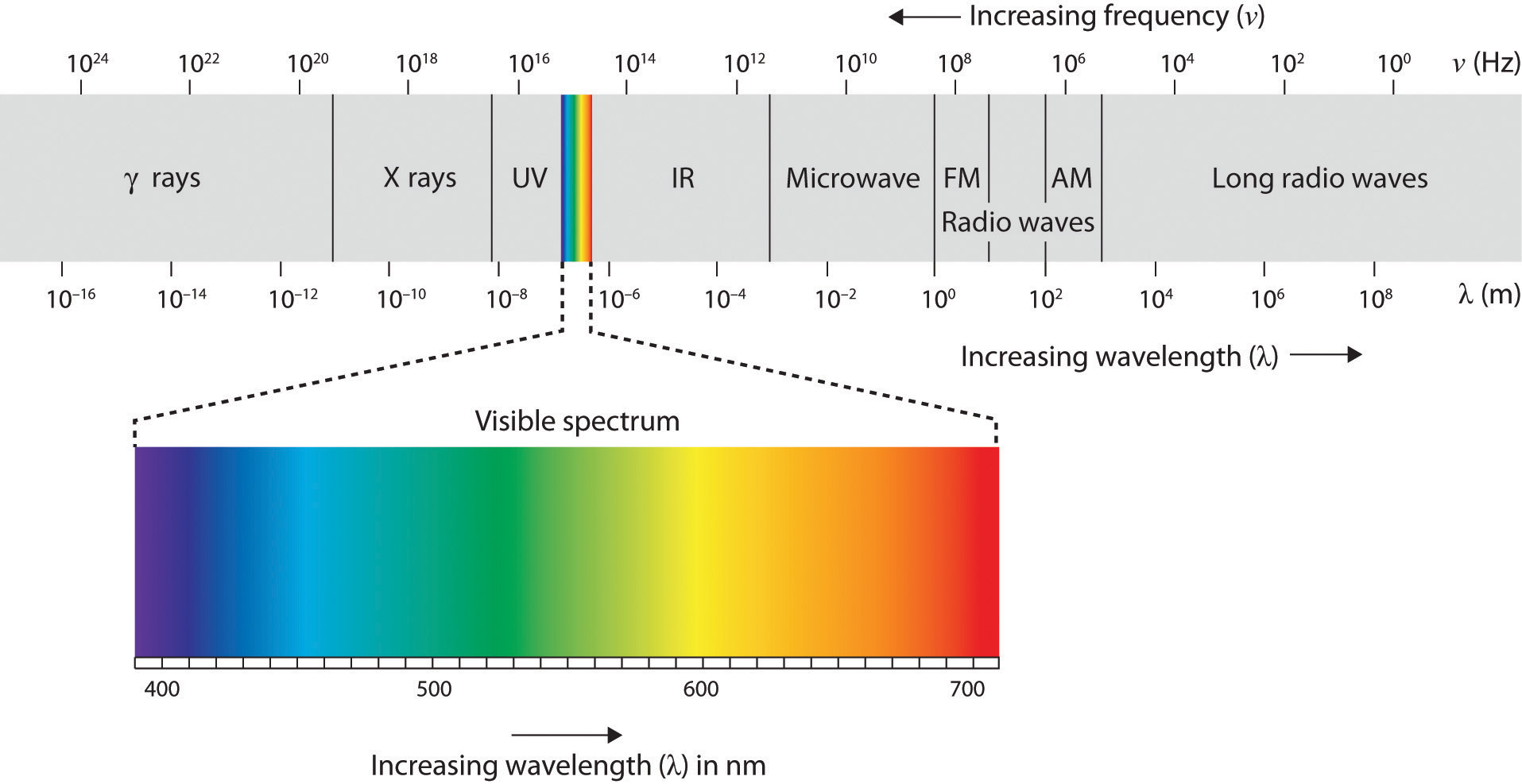
Figure \(\PageIndex{3}\): Only a small fraction of the electromagnetic energy that surrounds us (the visible spectrum) is detectable by the human eye.
In his important research on color vision, Hermann von Helmholtz theorized that color is perceived because the cones in the retina come in three types. One type of cone reacts primarily to blue light (short wavelengths), another reacts primarily to green light (medium wavelengths), and a third reacts primarily to red light (long wavelengths). The visual cortex then detects and compares the strength of the signals from each of the three types of cones, creating the experience of color. According to this Young-Helmholtz trichromatic color theory, what color we see depends on the mix of the signals from the three types of cones. If the brain is receiving primarily red and blue signals, for instance, it will perceive purple; if it is receiving primarily red and green signals it will perceive yellow; and if it is receiving messages from all three types of cones it will perceive white.
The different functions of the three types of cones are apparent in people who experience color blindness. Color blindness can be defined as having decreased capacity to see color or distinguish differences between colors. Red–green color blindness is the most common form, followed by blue–yellow color blindness and total color blindness. Red–green color blindness affects up to 8% of males and 0.5% of females of Northern European descent. Red-green color blindness is a result of an absence of long or medium wavelength cones or to the production of abnormal opsin pigments in these cones that affect red-green color vision (see Figure \(\PageIndex{4}\)).

Figure \(\PageIndex{4}\): People with normal color vision can see the number 42 in the first image and the number 12 in the second (they are vague but apparent). However, people who are color blind cannot see the numbers at all. Wikimedia Commons.
An alternative approach to the Young-Helmholtz theory, known as the opponent-process color theory, proposes that we analyze sensory information not in terms of three colors but rather in three sets of “opponent colors”: red-green, yellow-blue, and white-black. Evidence for the opponent-process theory comes from the fact that some neurons in the retina and in the visual cortex are excited by one color (e.g., red) but inhibited by another color (e.g., green).
One example of opponent processing occurs in the experience of an afterimage. If you stare at the flag on the left for about 30 seconds (the longer you look, the better the effect), and then move your eyes to the blank area to the right of it, you will see the afterimage. When we stare at the green stripes, our green receptors habituate and begin to process less strongly, whereas the red receptors remain at full strength. When we switch our gaze, we see primarily the red part of the opponent process. Similar processes create blue after yellow and white after black (see Figure \(\PageIndex{5}\)).

Figure \(\PageIndex{5}\): U.S. Flag. The presence of an afterimage is best explained by the opponent-process theory of color perception. Stare at the flag for a few seconds, and then move your gaze to the blank space next to it. Do you see the afterimage? Mike Swanson – U.S. Flag (inverted) – public domain.
Depth Perception
Depth perception is the ability to perceive three-dimensional space and to accurately judge distance. Without depth perception, we would be unable to drive a car, thread a needle, or simply navigate our way around the supermarket (Howard & Rogers, 2001). Research has found that depth perception is in part based on innate capacities and in part learned through experience (Witherington, 2005).
Psychologists Eleanor Gibson and Richard Walk (1960) tested the ability to perceive depth in 6- to 14-month-old infants by placing them on a visual cliff, a mechanism that gives the perception of a dangerous drop-off, in which infants can be safely tested for their perception of depth (see Figure \(\PageIndex{6}\)). The infants were placed on one side of the “cliff,” while their mothers called to them from the other side. Gibson and Walk found that most infants either crawled away from the cliff or remained on the board and cried because they wanted to go to their mothers, but the infants perceived a chasm that they instinctively could not cross. Further research has found that even very young children who cannot yet crawl are fearful of heights (Campos, Langer, & Krowitz, 1970). On the other hand, studies have also found that infants improve their hand-eye coordination as they learn to better grasp objects and as they gain more experience in crawling, indicating that depth perception is also learned (Adolph, 2000).

Depth perception is the result of our use of depth cues, messages from our bodies and the external environment that supply us with information about space and distance. Binocular depth cues are depth cues that are created by retinal image disparity—that is, the space between our eyes, and thus which require the coordination of both eyes. One outcome of retinal disparity is that the images projected on each eye are slightly different from each other. The visual cortex automatically merges the two images into one, enabling us to perceive depth. Three-dimensional movies make use of retinal disparity by using 3-D glasses that the viewer wears to create a different image on each eye. The perceptual system quickly, easily, and unconsciously turns the disparity into 3-D.
An important binocular depth cue is convergence, the inward turning of our eyes that is required to focus on objects that are less than about 50 feet away from us. The visual cortex uses the size of the convergence angle between the eyes to judge the object’s distance. You will be able to feel your eyes converging if you slowly bring a finger closer to your nose while continuing to focus on it. When you close one eye, you no longer feel the tension—convergence is a binocular depth cue that requires both eyes to work.
The visual system also uses accommodation to help determine depth. As the lens changes its curvature to focus on distant or close objects, information relayed from the muscles attached to the lens helps us determine an object’s distance. Accommodation is only effective at short viewing distances, however, so while it comes in handy when threading a needle or tying shoelaces, it is far less effective when driving or playing sports.
Although the best cues to depth occur when both eyes work together, we are able to see depth even with one eye closed. Monocular depth cues are depth cues that help us perceive depth using only one eye (Sekuler & Blake, 2006). Some of the most important are summarized in Table \(\PageIndex{1}\) “Monocular Depth Cues That Help Us Judge Depth at a Distance”.
Table \(\PageIndex{1}\) Monocular Depth Cues That Help Us Judge Depth at a Distance
| Name | Description | Example | Image |
|---|---|---|---|
| Position | We tend to see objects higher up in our field of vision as farther away. | The fence posts at right appear farther away not only because they become smaller but also because they appear higher up in the picture. |
Figure
|
| Relative size | Assuming that the objects in a scene are the same size, smaller objects are perceived as farther away. | At right, the cars in the distance appear smaller than those nearer to us. |
Figure
|
| Linear perspective | Parallel lines appear to converge at a distance. | We know that the tracks at right are parallel. When they appear closer together, we determine they are farther away. |
Figure
|
| Light and shadow | The eye receives more reflected light from objects that are closer to us. Normally, light comes from above, so darker images are in shadow. | We see the images at right as extending and indented according to their shadowing. If we invert the picture, the images will reverse. |
Figure
|
| Interposition | When one object overlaps another object, we view it as closer. | At right, because the blue star covers the pink bar, it is seen as closer than the yellow moon. |
Figure
|
| Aerial perspective | Objects that appear hazy, or that are covered with smog or dust, appear farther away. | The artist who painted the picture on the right used aerial perspective to make the distant hills more hazy and thus appear farther away. |
Figure
|






Motion
Many animals, including human beings, have very sophisticated perceptual skills that allow them to coordinate their own motion with the motion of moving objects in order to create a collision with that object. Bats and birds use this mechanism to catch up with prey, dogs use it to catch a Frisbee, and humans use it to catch a moving football. The brain detects motion partly from the changing size of an image on the retina (objects that look bigger are usually closer to us) and in part from the relative brightness of objects.
We also experience motion when objects near each other change their appearance. The beta effect refers to the perception of motion that occurs when different images are presented next to each other in succession (see Note “Beta Effect and Phi Phenomenon”). The visual cortex fills in the missing part of the motion and we see the object moving. The beta effect is used in movies to create the experience of motion. A related effect is the phi phenomenon, in which we perceive a sensation of motion caused by the appearance and disappearance of objects that are near each other. The phi phenomenon looks like a moving zone or cloud of background color surrounding the flashing objects. The beta effect and the phi phenomenon are other examples of the importance of the gestalt—our tendency to “see more than the sum of the parts.”
Beta Effect and Phi Phenomenon
In the beta effect, our eyes detect motion from a series of still images, each with the object in a different place. This is the fundamental mechanism of motion pictures (movies). In the phi phenomenon, the perception of motion is based on the momentary hiding of an image.
Phi phenomenon: http://upload.wikimedia.org/Wikipedia/commons/6/6e/Lilac-Chaser.gif
Beta effect: http://upload.wikimedia.org/Wikipedia/commons/0/09/Phi_phenomenom_no_watermark.gif
Attribution
- Vision sections adapted by Isaias Hernandez from "NOBA-Vision"; https://nobaproject.com/modules/vision
- Vision sections adapted by Isaias Hernandez from "Psychology-Penn State"; https://psu.pb.unizin.org/intropsych...eption-vision/
- Vision sections adapted by Isaias Hernandez from "Introduction to Psychology-University of Minnesota"; https://open.lib.umn.edu/intropsyc/c...04_s02_s01_f02