
8.4: Indo-European and Romance Phonological Reconstruction
- Page ID
- 199981
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)8.3.1 Indo-European and Romance Phonological Reconstruction, from Sarah Harmon
Video Script
Now that we have studied a bit about reconstruction, let’s start talking about reconstruction in action with some data. This is going to focus primarily on the Indo-European languages and the Romance family specifically. There are a few reasons, not just because this is my area and I’m going to be able to explain this best. With the Indo-European language family, we have a very special set of data—it is the language family with the longest continuous deciphered writing data. We have a about 3,500 years of continuous deciphered data from a variety of sub-families. Technically speaking, the oldest writing systems are not in the Indo-European families. Certainly, the Chinese writing system has been around for about 4000 years, give or take, and that isn't even touching Egyptian Hieroglyphics, or especially what we consider to be the first writing system, the Sumerian writing system.
However, there are some problems: the Sumerian writing system is excellent and it got borrowed from the Sumerians to later generations, specifically the Akkadians, who spoke an Afro-Asiatic language, and the Hittites, who spoken an Indo-European language. We're still trying to decipher a lot of pieces with respect to just Sumerian, let alone any of the others. There's the unfortunate aspect of the Sumerian language being an isolate; to this point, we have yet to connect it to another language family or even subsequent languages. It's very difficult, so we have to put that one aside. With respect to the Egyptian Hieroglyphics, we definitely know how most of them were pronounced throughout their history; we've gotten pretty good data on that. As far as the oldest hieroglyphs, that's a little harder to decipher. We're not entirely sure how they were pronounced and so I’m going to put that aside as well. Finally, with respect to Old Chinese: no question that the ethnic groups that have spawned and continued to thrive in that region have had a writing system for a very long time. But we aren't entirely sure how everything was pronounced. While a lot of work has been happening in China with respect to that, and there is a good amount of research in that area, there's still a lot of controversy with respect to that data. For now, I’m going to also put it to the side; who knows, maybe in a few years, I will be able to include it. Therefore, I will stick with the Indo-European languages, and specifically Romance, which is my actual specific area of expertise.
We have not just the modern Indo-European languages, and not just the classical languages of Latin and ancient Greek. We have to include Sanskrit, which has a very long history, and Vedic or Aryuvedic, which has an even longer history of being written down, and then the granddaddy of them all, which is Hittite. Hittite is the earliest attested Indo-European writing; they borrowed the Sumerian writing system buccaneer form, but it is the earliest documentation and it has helped us to understand some of the potential sounds of proto-Indo-European.
Let's take a walk into the past, shall we?
This first slide shows a couple of different reconstructions that we can do. The top is Romance, and this is modern Romance. This should be in into international phonetic alphabet (IPA), but it's not, although most of you probably either have some knowledge of how the Spanish or French or maybe both are pronounced. There may be some of you who are Italian speakers, Portuguese speakers, and so you can pronounce them. I will go through them just the case.
When we reconstruct, we say, “Okay, let's look at each sound individually across the board, and let's see what the sound could be in the earlier parent of that language.” Admittedly, we are cheating a little bit with Romance because we have the parent is written down—I don't just mean Classical Latin, but I mean Vulgar Latin. There's really only a window of about 150 years that we have no writing, or precious little writing, in any Romance language. It really goes all the way back to Old Latin.
In reconstructing these sounds, we go across. The word for ‘dear’, like ‘a dear person’ or ‘a dear friend’: cher in French, caro in Italian, caro in Spanish, caro in Portuguese. Therefore, we know that that first sound in each modern word is a [k, k, k, ʃ]. One of these things is not like the other. (Come on, you know that song, right?) Because of those data, we know:
- That first sound is probably going to be a [k], because three out of the four languages, the data here suggests that that is the sound.
- The next is the vowel: [a, a, a, ɛ]. Again, one of these things is not like the other, so probably it's going to be [a] because that's pretty close.
- As far as the R is concerned, I don't have them written out here and IPA but technically speaking. Spanish and Italian both use that alveolar tap, that real quick flick that hits the alveolar ridge. If you speak Spanish, you know what this is; Italian has the same sound. It's not like the trill; that's not the term that we use. What is interesting is that both French and Portuguese, depending on the dialect, that ‘r’ rhotic, has intensified and velarized; it has gone to the back of the mouth, and almost always it's the velar region. It is either a trill or a kind of fricative, depending on the dialect. For right now, I’m going to actually keep it as an alveolar trill, because there's so much play and the alveolar trill is higher up on the hierarchy than the others.
- This final sound—the [o, o, o], deletion—clearly, French is not going to represent the old pronunciation. It is going to be a lot closer to what we hear in Spanish or Italian.
We can do the same thing for the term for ‘field’. If we go across:
- [k, k, k, ʃ], so we know that that first sound is a [k] because three of the four have it.
- [a, a, a, a], okay all four languages show that it's the same sound, so it's probably going to be an [a].
- we have an [m] sound, and then we have a [p] sound at all for the languages
- again, three out of four and in a vowel is probably an [o].
The word for ‘candle’, you can do the same thing, right?
- Three of the four have a [k];
- All four have an [a];
- All four have an [n];
- The next sound is almost certainly some kind of a [d]-like sound;
- There's a lateral liquid;
- Three out of the four have an [a], the fourth has an [ɛ], so the chances are that it's going to be [a].
The great news is, as I said, these are Romance languages, and we actually know that this was how both Classical Latin and Vulgar Latin sounded, so this is a pretty good clue. In fact, many of the Indo-European languages are frequently test runs for any historical linguistic theory; if you can prove it on any of the Hellenic family (that's Greek), anything with respect to Romance to Latin, and if you can do it with Sanskrit (Hindi or Gujarati and the languages in northern and central India, Pakistan and parts of Afghanistan). Those languages have such a long and rich attestation, and we have so much data for those three language families in Indo-European alone. If your theory holds water there, it might hold water elsewhere. This is one of the reasons I got into Romance linguistics; I wanted to be able to test out theories. If a theory can work to explain something in the Romance languages, then it might be a pretty good theory for how languages change. If not, well, we might have to find something else that might work.
With respect to Proto-Indo-European, as I said, there is a reconstruction based off of the oldest attestations of the Indo-European languages—not just Classical Latin, but Old Latin, for which we do have good records, as well as the various ancient Greek language, including Attic, especially as we get to know more about Mycenean, which is written in Linear B. The more we start understanding Hittite, the best data seem to come from there, because it is the oldest attestation of an Indo-European language. As we get those languages together, and as we start comparing and contrasting and seeing how these correspondences work, we can start building how Proto-Indo-European might have sounded like.
Here are some correspondences. if you think of the term for ‘father’. Remember that English is a Germanic language, so ‘father’ is frequently with that labiodental fricative. Pater in Classical Latin—actually, most attestations of Latin—and notice that the word for ‘father’ in most of the Romance languages, if not all of them, begin with a [p]. In Sanskrit, it's very similar, and if you speak Hindi, Urdu, Gujarati, or any of the Indic languages, you know that your term for ‘father’ is very similar to pitar. What we're going to say is that the Proto-Indo-European sound is almost assuredly that same [p], that there's a sound change that happens in the Germanic languages. As you go around, the word for ‘three’ and most of the other languages do not begin with that interdental fricative; it begins with a [t]. Chances are in Proto-Indo-European it probably also started with a [t].
When you see consonants that have an ‘h’ afterwards, if you speak an Indic language or even an Indo-Aryan language as a whole—Farsi still has some of the sounds, too—these are what we like to call breathy sounds. It's not just a [b], but there's a <glottal vibration/exhale> with it: [b̤]. They tend to be voiced obstruents, almost always stops, but you can have some fricatives and affricates in there. We see them in Sanskrit, Vedic (Farsi’s much older ancestor) and we see something similar in Hittite. Therefore, the chances are that Proto-Indo-European might have had it, too.
One more thing to point out: notice that the Proto-Indo-European sounds all have an asterisk in front of them. If you recall when we were in syntax, we said that the asterisks meant that it's ungrammatical, that it doesn't follow the phrase structure rules for the language. There is a different meaning here—arbitrariness, right? In historical linguistics, we use the asterisk to mark that something is reconstructed. This means that we do not have evidence or data of it being that way, but based off of the data of the child languages, the chances are pretty good that this is the sound that was in the proto-language.
When we talk about phonological languages or phonological changes as a whole, we're going to talk about some of these things that we saw way back when we talked about phonology. The same rules apply; in fact, most of what we saw with respect to phonological change all the way back in chapter three is due to an historical process, meaning there's some change over time that has happened. Whether we're talking about loss or deletion, apocope is part of that, insertion or epenthesis, assimilation and dissimilation rules and metathesis—all of these are going to come back in a big way. We know that these are processes that happen, not just within one generation, or maybe spilling into a second, but we're talking over 3, 4, 5, up to10 generations where we see the change happen. Most language change is gradual; it is not instant by and large. There are some exceptions to that rule, but we'll talk about that at another time. I’ll show you a couple of phonological changes that we see in the Indo-European languages, and I’m going to start with Grimm’s Law—by the way, Grimm is Jakob Grimm, as in one of the Grimm Brothers. We know them for collecting fairy tales throughout Central Europe. Jacob Grimm was also comparing languages, specifically the languages that were spoken throughout Central and Eastern Europe, as they were going out into the countryside and collecting tales. What he ended up showing was a little bit about why the Germanic languages sound different than the other languages of Central and Eastern Europe—Slavic languages, Romance languages, and the like. He came up with some interesting facts. We have subsequently found more data, and we still call this Grimm’s Law, even though he didn't fully flesh it out; he gave us the idea and we attribute it to him. Specifically with respect to Grimm’s Law, focus on this top right corner of the graphic.
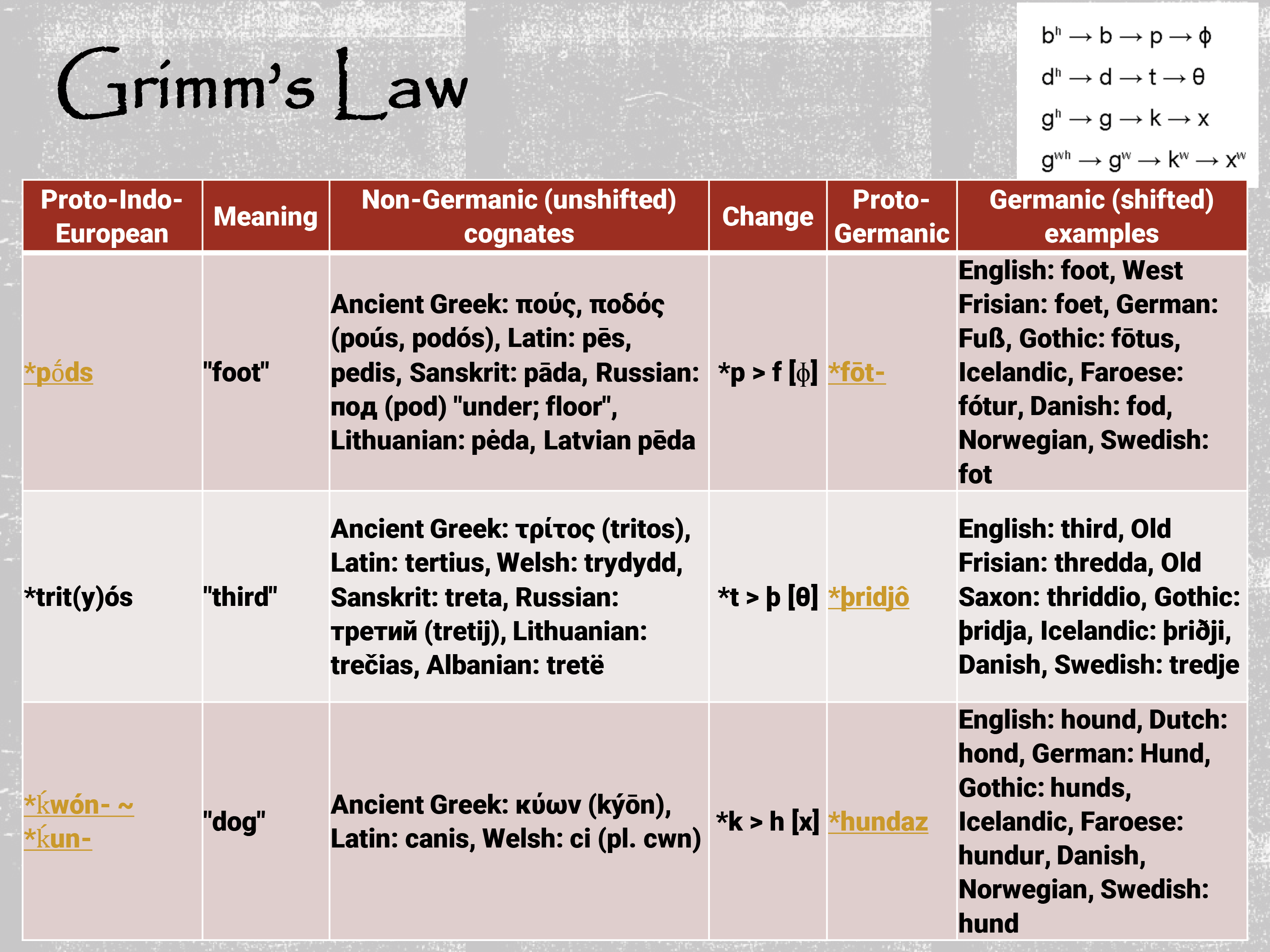
It's the concept of Proto-Indo-European [b, d, g] and [p, t, k], all changing. It's a specific change within the Germanic languages, because we see a number of shifted sounds—and by shifting, I mean they go from voiced and breathy to voiceless—and then they get fricated—meaning they turn into fricatives. The term for a ‘foot’ and you see here: foot, foet, fuß, fōtus, fótur, fod, fot. All the term for the thing at the end of your leg that you stand on. Notice that in every other Indo-European language, almost without exception, that term starts with a with a [p] sound: poús or podós, pēs or pedis, pāda, pod, péda, pēda. Pretty important work. It should be noted that Latvian is thrown; Latin and Lithuanian are both Indo-European languages, although they have been heavily influenced by their Finno-Ugric neighbors, especially Estonian but even Finnish. Yet, their core vocabulary tends to be Indo-European.
Why do we have these languages up here? That is what Jakob Grimm looked at; he compared all of the Germanic languages. Most of those you probably have heard before. West Friesian is part of some of the islands off of Scotland; the Faroe Islands are between Scotland and Iceland. The others you probably recognize. He went and compared them to Ancient Greek and Classical Latin, because he knew those languages, and he had access to Sanskrit. Given his status, he would have had access to it. Grimm knew plenty of Russians, and he came across those who spoke Russian, Lithuanian and Latvian, even included some Albanian, and for kicks and grins included some Welsh. All of these cases—the [f] sound, the [θ] sound, and the [h] sound that we have in the Germanic languages—many times have more obstruent counterparts. They were more occlusive; they are stops in almost all cases in the more modern Indo-European languages.
To take it a step further, what Grimm hypothesized was that there would be in a parent language something a little bit harder, probably a little bit more involved, and so what we see is that in the Proto-Indo-European, we see that it is occlusive, it is a stop. It's also a very hard stop; it has softened over time, and softened even further when we get to the Germanic languages. The Germanic languages showcase a really great example of what a language family describes: this tendency to exist because there was an initial group or speech community that pulled off, got established elsewhere, and then spread out on their own. Think of migration patterns, as they are the same thing. In the case of the Germanic languages, what we have learned subsequent to Jakob Grimm and his work, is that the Germanic languages, the Germanic peoples seemed to have broken off later than other Indo-European groups. In doing so, they started interacting with the other peoples in and around Eurasia. Because of this late separation and intermingling with other linguistic communities, their patterns are is going to be very different than what everybody else ended up doing with respect to the sounds.
That's a little bit about the Germanic languages, let me show you a little bit about the romance languages. Again, this is a little bit of my specialty and I have to give a shout out to one of my professors at UC Davis, Robert Blake, who was mentored by one of my professors at the University of Texas who also became my mentor, Carlos Solé.
When we talk about Romance languages and we talk about palatalization—remember that term? That the sounds are going more towards the palatal region of the mouth—if you think about the different Romance languages, there's a lot of palatalization. It's not exactly the same palatalization rule; we have different forms of it. What we see in the history of this language family is different waves of palatalization. I've put up here Spanish and Italian, and then I’ve given you what we have in Classical Latin, but slightly modified, and that's what we're going to see with Vulgar Latin. Vulgar Latin was the language of the people. It wasn’t vulgar, like full cuss words; Vulgar Latin just means it was the language of the people, what people tended to speak, instead of Classical Latin, which was studied and written, but not really spoken much once you get to the end of the reign of the Latin kings—before the Republic. By the point that we get to the Republic, even Classical Latin is not really spoken that much anymore; certainly, by the time you get to Julius and Augustus Caesar, Classical Latin is not spoken hardly at all—maybe only by the Emperor and that class, maybe a couple generals, but that's about it.
| Classes of yod | Effects on various vowels | |||||
|---|---|---|---|---|---|---|
| 1st yod: oldest change; doesn’t affect vowel |
ty/ky → [t:s, z, ɵ, tʃ] |
fortia → Sp. fuerza; It. forza |
pettia → Sp. pieza; It. pezza |
lutea → Sp. loza It. --- |
malitia → Sp. maleza; It. --- |
minacia → Sp. amenaza; It. minaccia |
| 2nd yod: influences open vowels only |
ly, k’l → [l: à x/ʎ] |
folia → Sp. hoja; It. foglia |
reg(u)la → Sp. reja; It. ---- |
cusculiu → Sp. coscojo; It. ---- |
cilia → Sp. ceja; It. ciglia |
palea → Sp. paja; It. paglia |
|
(mnà) ny, gn → [ɲ, n:, n] |
somniu → Sp. sueño; It. sonno |
ingeniu → Sp. i/engeño; It. ingegno |
cunea → Sp. cuña; It. cuneo |
ligna → Sp. leña; It. legno |
aranea → Sp. araña; It. ragno |
|
| 3rd yod: regularly affects open vowels, sometimes closed vowels |
gy/dy → [j, dʒ] |
podiu → Sp. poyo It. poggio |
pulegiu → Sp. poleo It. puleggio |
fugio → Sp. huyo It. fuggio |
fastidiu → Sp. hastío (It. fastidio) |
exagiu → Sp. ensayo It. saggio |
|
by/my → [j, bj/b:, mj/m:] |
fovea → Sp. hoya (It. fovea) |
nerviu → Sp. nervio; It. nervo |
rubeu → Sp. ruyo/royo It. ---- |
vindemia → Sp. vendimia; It. vendemmia |
labio → Sp. labio; It. labbro |
|
| 4th yod: regularly affects vowels |
kt, ks → [tʃ/t:, ʃ à x] |
nocte → Sp. noche; It. notte |
lecto → Sp. lecho It. letto |
tructa → Sp. trucha It. trota |
strictu → Sp. estrecho It. stretto |
facto → Sp. hecho; It. fatto |
We see four different waves, and you see this term yod. This is actually a letter of the Hebrew alphabet, but, more specifically, it has this [j] quality to it in Classical Hebrew. Whenever you had that letter written, you knew that the sound that came before it was palatalized somehow. That's why that term was borrowed, to explain what happens in the Romance languages; this does not mean that Hebrew has any effect on the Romance languages, at least not in this way. It also should be noted that these four waves all happened before the fall of the Empire, so this first yod actually starts during Imperial times. This is the oldest change; it doesn't produce any effect on the vowel. There were seven vowels in Classical Latin, and they were both long and short. Realistically, the only modern Romance language that has anything similar to that is Sardinian; most all of the other Romance languages have five vowels, and they sound very different. To explain this table, we're talking about when you have a [t] or [k] next to this yod, and this is almost always a high vowel or a front vowel. In this case, fortia, which means ‘strength’; notice that is next to a [i] sound, so there's your yod that's the palatalization effect. We have pettia, lutea, militia, minacia. If you speak Spanish, you'll recognize most, if not all, of these terms; some of them are older terms and may not be used very often. I’m giving you the Italian because there's a slight difference in how Italian palatalized over Spanish; if I had more room, I would include Spanish and Portuguese, probably Romanian as well, just to give you an idea. We’ll start with fortia because the term force that we have in English is borrowed from French, and it comes from the same root. In Spanish, this becomes fuerza, so this [t] softens to a fricative, and may, depending on your dialect even front a little bit to [θ]. If you're in Spain, this is not [fueɾsa] in Spain, this would be [fueɾθa]. In Italian, it's [foɾtsa] so becomes a affricate [ts]. You see that here: amenaza for minacia, which is a ‘threat’ in Classical Latin, and [amenasa] or [amenaθa], depending on your dialect in Spanish, same thing; [minatʃa] in Italian, same thing. Notice it's a [tʃ] sound, not a [t] sound. A little bit later, maybe four to five generations later, you get the second yod, where you start opening up the vowel a little bit, and you have more consonants that are affected by it. You have the [l, ɲ], and the ‘ng’ together. Think, for example, the term for a ‘leaf’ or ‘sheet’ is a folia in Classical Latin; notice that I’m palatalizing that a little bit. In Italian it's [foʎja]; it's a fully palatalized sound. In Spanish, it's an [oxa], so that [x] is an even further palatalization. Yes, I know there's an ‘h’ there and that's another discussion. Yet, what you can see is the various progressions of this yod and this palatalization rule.
With respect to Grimm’s Law and the Romance palatalization rule, you do not have to remember the individual steps at this time. In an upper division historical linguistics course, that's a totally different thing. What is important to understand is that these changes happen, that they are relentless. In fact, even if we go back to this first y'all and we think about the Spanish pronunciation that pronunciation has changed, and is still changing and continues to go on. For example, the pronunciation of the written ‘j’ in Spanish depends greatly on what dialect you're speaking.
When we talk about Proto-Indo-European, what we're really thinking at this moment—and I say ‘at this moment’, this is a map from 2007 and reflects the latest that we know with respect to historical linguistics and specifically the Indo-European group—this family started most likely in this Ukrainian Steppe region, near the Balkans and Greece. It seems to start with the Yamna culture or Kurgan culture. ‘Kurgan’ refers to the fact that they had burial mounds; it's a really specific type of burial that you learn about in anthropology. We know that this culture existed 4500 to 2500 Before the Common Era (BCE)—we don't say ‘BC’/’AD’ anymore, we say ‘Common Era’ (CE), ‘Before Common Era’ (BCE). This Kurgan or Yamna culture, we're talking for 6000 years ago, Proto-Indo-European is what we believe, to our best estimation, was spoken between 3000 and 5000 years ago. It could be older, it could be a little younger, but that's our best attempt at dating it right now. We do know that there are early splits so the earliest split would be to the Afanaseco culture, which is in Central Europe, or excuse me, Central Asia, and then the Maykopf, which is down to the south. We know that there's also the Anatolian branch, which splits off very early; this is where the Hittites are. We know that that branch was existent at least 1000 to 2000 years before the Hittite’s kingdom comes to be, so we believe it to be about 4000 BCE. It's in the second millennia BCE, about 1700 BCE, that we start seeing the Hittite kingdom. Notice that we have multiple expansions into Asia; it's not just Europe. Remember, this is the Indo-European language family. This family also includes the Tocharians, which I still find to be the most fascinating group because we still only know pieces about them. This language family was in Central Asia and Western China; the Wusun are kind of in that realm, as well. These two families had a kind of writing system, but we are still trying to decipher it. The Ancient Chinese writings very rarely talk about them, so there's a lot more that we still have to learn; I’m hoping that there's some archaeological dig yet to be found that has more data.
When we're talking about the Indo-Aryan languages, we're talking about Persian or Farsi and its ancestors that's the Aryan branch—Vedic or Aryuvedic is part of that, as is the Iranians who are a different branch. The Vedic branch is where you get Sanskrit and then the subsequent Indic languages. Armenian is an Indo-European language—people forget about that, but it is—and then you have the various branches in the early first and second millennia BCE, you notice that there are various splits.
Below, I have included two SoundCloud links, examples of what we believe Proto-Indo-European sounded. They are a couple of stories. This is a really fascinating just piece to hear. Again, it’s hypothetical, but our best guess so far.