
3: A Typology of Social Forms for Learning
- Last updated
- Save as PDF
- Page ID
- 81800
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)A TYPOLOGY OF SOCIAL FORMS FOR LEARNING
The beginning of wisdom is to call things by their right names. Chinese proverb
The Internet era forces each of us to deal with an often bewildering and continuous set of technology-induced changes. When an infrastructure of powerful computational and communications tools is matched with a ubiquitous communication network, the stage is set for rapid innovation. Some of these innovations are sustaining and help us to communicate, play, and learn more effectively using familiar ideas and behaviours. Other innovations are disruptive—forcing users to go outside the economic and social boundaries set by previous technologies and pedagogies to use them effectively (Christensen, 2008; C. Christensen, Horn, & Johnson, 2008). Learning, however, is universal, and thus humans invent means and applications to use both disruptive and sustaining technologies to enhance their lives and those of others on the planet. In this chapter we introduce an organizational scheme, or heuristic, designed to create a conceptual home for both sustaining and disruptive networked technologies—and those with elements of both when applied in particular contexts.
We developed this guiding heuristic for learning and education in 2007 (Dron & Anderson, 2007) and it has been used in our work, and by others, to help make sense of the changing social patterns in learning that cyberspace has engendered (e.g., Buus, Georgsen, Ryberg, Glud, & Davidsen, 2010; Conole, 2010; Dalsgaard & Paulsen, 2009; Gray, Annabell, & Kennedy, 2010; Kop, 2011; Ryberg, Dirckinck-Holmfeld, & Jones, 2010; Thompson, 2011).
Though it proved to be of some value in its original form, we have since modified and refined our model for clarity and explanatory power. In brief, the evolved form illustrates three kinds of aggregation of learners in either formal or informal learning: groups, networks, and sets. We originally conflated sets with a further emergent entity that is not a social form as such, which we have referred to as the collective. The collective is an embodiment of collective intelligence, and it plays a binding and, in many cases, extremely active role in enabling social software systems to do things that were difficult or impossible in the past. Collectives are not a social form, but an emergent actor that arises from actions taken by people in a crowd.
To distinguish these forms, it may help to think of an example drawn from everyday life. Imagine that you are sitting in a café in the square of a busy city. Around you is a teeming multitude of people—the set of people in this part of the city. You do not know who they are, and they are not part of your social network though you may be learning things from them, such as whether it is raining or not: you might, for example, note how many are carrying unfurled umbrellas. As you look around, you see subsets of this set: men, women, children, people dressed in red coats, people running, people going to work. Some of these people come in groups—families, friends, classes of schoolchildren—that share a purpose and are, in some way, coordinated in their movements and activities. They may be there for the purpose of learning together: children on field trips, surveyors mapping out the land, or tourists being shown the sights of the city. Every now and then you see people running into friends, colleagues, and people they know. Strung between the people in the crowd are networks, exchanging information and co-constructing knowledge. Then you notice a cluster of people forming, gathering around a street entertainer performing in the middle of the square. No one has organized the gathering—a small crowd seems to attract more members, as though there were an invisible force pulling them together, a leaderless form of coordination, an emergent order: a collective. The crowd is acting as a signal for others to join it, playing a role not unlike that of a teacher telling a class to pay attention to some reading or performance.
Figure 3.1 illustrates the three social forms for learning, representing the fact that there is a continuum between the forms, each blurring into the next.
All of these social forms are bound by common attributes of sharing and communication that can contribute to the learning of others. Collectives, a particular form of collective intelligence, can emerge from any or all of these social forms and are characterized by algorithmic aggregation, filtering, data mining, clustering, and pattern-matching. These algorithmic processes may be internal to crowd members (e.g., responding to others in a crowd) and/or externally imposed, typically by computers (e.g., recommender systems) but sometimes by individuals (e.g., people who count votes in an election).
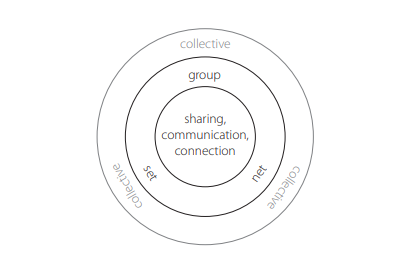
Figure 3.1 Social forms for learning: Sets, nets, and groups.
Our model is derived from our observations about collections of learners and how they benefit from one another’s knowledge and actions. While these social forms can and do exist in contexts other than learning, it is not our intention to provide a complete model of human society, or to suggest that the model would be useful in all other contexts. This model is useful because, as we will demonstrate in the ensuing chapters, it helps to make sense of not only how social learning occurs in traditional educational settings but also how the different ways that we can connect using cyberspace technologies may contribute to our learning trajectories in informal and personal settings. These social forms can and do exist in many circumstances beyond learning, and we will from time to time provide examples of their use in other contexts in order to help illustrate what we mean, but it is not our intention to tread outside the boundaries of a learning context in applying this model.
Individuals
Before we move into the realm of truly social forms that involve multiple participants, it is important to observe that much learning involves only the most tenuous links between people. When we as individuals read a book, paper, web page, or news feed, transactional distance is extremely high. However, even for the most solitary of learners, other people are necessarily involved in the learning transaction as authors and creators of content. In many cases, this involves a form of guided didactic conversation (Holmberg, 1986) in which the learner engages in internalized dialogue with the very distant tutor. Even where this is not the case, the author’s voice may be apparent and there is a strong sense that almost every learning process involves, at one or more steps removed, another human being. At a small scale, all textual communication and many that use voice, video, or avatars include a process of turn-taking in which we read/absorb and, potentially, respond. The difference for the individual learner is that the possibility of an ongoing exchange is not available.
Dyads
In 1984, B. S. Bloom famously posed the 2-sigma problem, referring to the finding that an average student tutored one-to-one performed two standard deviations better than an average student tutored using conventional one-to-many instructional methods. We are a little skeptical about the validity of the assessment used to take this measurement, since such objective-driven testing does not reveal all of the learning that may have occurred in a transaction, and does not look at creative gains or serendipitous discoveries that may have been made in larger groups or with different methods of learning and teaching.
However, the general point is hard to ignore: when compared to traditional institutional educational forms, where the goal is to transfer replicable knowledge, one-to-one tutoring works extremely well. Since Bloom’s original challenge, one-to-one tutoring (assuming appropriate methods are applied) has remained the gold standard for effective instruction, and no other teaching model has consistently reached or bettered the same 2-sigma improvement that results from it. Unfortunately, one-to-one tutoring is very expensive and, in formal learning, only common in a limited range of situations such as Ph.D. mentoring, project work, and personal tutoring. More than that, there are gains to be had from a diversity of perspectives, heuristics, interpretations, and predictive models that may be found in a large number of people (S. E. Page, 2008).
Though a pair of people communicating may be seen, in some ways, as a very small network or group, one-to-one conversation is different from other forms of learning conducted with more than one person. Rainie and Wellman (2012) observe that as soon as a third person is introduced, the potential for coalitions arises, and the persistence of the group no longer stands or falls on the actions of a single individual: if one leaves, interaction does not necessarily cease. Greater numbers have many other benefits that differ from dyadic communication in scale, if not in kind. Diversity increases with more people, allowing greater types and levels of interaction to occur, providing multiple perspectives, different interpretations, heuristics, and predictive models (S. E. Page, 2008), all of which can contribute to learning: more possibilities mean greater breadth and depth of discourse, more creative opportunities, and better problem-solving capacity.
For all the benefits of many individuals learning together, from a learning perspective dyadic communication typically affords the greatest possible level of freedom of delegation for the learner: the tutor can respond directly to questions, adapt teaching to the learner’s stated or implied reactions, and the learner can choose whether to intervene in the course of his or her own tuition without contest with others (Dron, 2007a). Although it may occur in the context of a large group, a great deal of dyadic communication underpins most forms of social learning, from email exchanges to telephone conversations, face-to-face mentoring to instant messages. While the title of this book makes it clear that we are mostly concerned with learning in larger groups, one-to-one dialogue represents an “ideal” form of guided learning, at least where there is a teacher who knows more than the learner and is able to apply methods and techniques to help that learner to learn. It continues to play an important role in network forms of sociality because of the essentially oneto-one edges between nodes that lead to what Rainie and Wellman (2012) refer to as “networked individualism”—a focus on an individual and their many one-toone connections with others. It is also an important form in sets, where we may interact with an unknown other in the same direct way.
Groups
The most familiar social form in an educational context is the group. In a formal educational context, these are just a few of the common forms that groups may take:
| Classes | Schools | Administrative departments |
| Tutorial groups | Colleges | Panels |
| Seminar groups | Committees | Special Interest Groups |
| Cohorts | Working groups | Study groups |
| Divisions | Workshops | Sports teams |
| Centres | Conferences | Playground gangs |
| Faculties | Project teams | Houses |
| Universities | Academic departments | Year groups |
| Learning technology groups | Research groups | |
| Boards of governors | Senior management teams |
Each of these groups may be more or less formally constituted, and each can play a role in the learning experience for anyone affected by them. Groups are cohesive: they are identifiable as distinct entities with existences of their own that are, in principle, independent of their members. However, one of their defining characteristics is that their members are, in principle and often in practice, listable. Groups often have formal lines of authority and roles, such as a designated chairperson, team leader or teacher, enrolled student, and so on, with implicit and/or explicit rules that govern behaviour and structure. They are structured around particular tasks or activities that may be term-based or ongoing, and institute various levels of access control to restrict participation, review of group artifacts, or transcripts to members, providing a less public domain. Groups often have schedules: members frequently use and create opportunities to meet faceto-face or online through synchronous activities, and their modes of interaction are typically many-to-many or one-to-many.
Nets
Our second major social form is the network. The distinction between groups and networks that we employ is a common one, used by many researchers in the field as well as in fields like community studies, sociology, and community informatics (e.g., Downes, 2007; Rainie & Wellman, 2012; Sloep et al., 2007; Wenger et al., 2011). Networks consist of nodes—such as people, objects, or ideas—and edges, the connections between them. In the social form of a network, networks connect distributed individuals and groups of individuals, one node and edge at a time. They are not designed from the top down, though we may create channels that make their emergence more likely. Instead, they evolve through our many and varied interactions with others. Entry and exit to networks is usually simple— we connect in some way with another person, or we don’t: although we might occasionally cut our ties with other individuals, for the most part it is enough to simply not engage with someone for them to drift out of our network. Every individual’s network is different from those of others because it is defined by social connections and therefore it matters whose perspective and connections are being observed. People may drift in and out of network activity and participation based on relevance, time availability, context, needs, and other personal constraints.
Networks have always been channels of knowledge diffusion and discovery: we learn from and with the people we know, whether connected via networked technologies or in person. Online, net forms are typically enabled by technologies incorporating social networking systems. Learners can be connected to other learners either directly or indirectly, and may not even be aware of all those who form part of the wider network to which they belong.
Many social networking sites such as Facebook, LinkedIn, and MySpace provide network support and facilitation tools, yet the form has been used by distance learners for much longer: earlier email lists and threaded discussions also support networked learning and physical social networks, and have long been important channels of knowledge diffusion.
It is important to distinguish some shifting notions in the concept of a network: the Internet, for example, is as much a physical network of machines and connections between them, as it is a network of people. Indeed, that physical network is the means through which people can come together. It is also important to recognize that, quite apart from a means of transport, a network can include or be entirely composed of things (physical and conceptual), not just people. Indeed, it is possible to view the entire universe as a network. Our concern here is not with the abstract topological form of networks in general, but with the social form of the network. Physical networks may be fundamentally required to connect people in a group, for example, but the group social form is different from the net social form even though both are, in several meaningful ways, describable as networks. Net modes of interaction can be one-to-one, one-to-many, and many-to-many.
Sets
Our final social form is the set. Sets are made up of people who are bound together by commonalities or shared interests. People may be unaware that they are part of a set (e.g., people with a particular genetic marker), or they may identify with it (e.g., people who are fans of football or constructivist teaching methods). Sets involve interactions with others, but typically these are impersonal or even anonymous. When an author publishes a textbook, he or she is writing for a set—an unknown number of people with a particular shared interest. Library books are categorized with metadata that puts them into sets, allowing individuals to seek items of interest.
In the past, the social interaction in most sets tended to be one-way, with a few exceptions such as a speaker’s engagement with crowds in lecture theatres, for example. Online, the set form has become more significant. A blog post or public tweet (especially when tagged or given a subject line to indicate its content) is not usually aimed at an individual, a group, or a network of friends (though they may be included), but at others who share that interest. While learners seeking information about a topic may well take individuals and networks into account when choosing a blog post to read or article in an online journal, it is more often than not the topic that attracts them, not the network. Much of the time there will be no expectation of engagement, no new network formed, no group joined. When individuals browse YouTube videos, networks may well play a role but, for the most part, discovery is based on content similarity and shared keywords. When we pick curated items or those that have been highly rated, the network is simply the underlying infrastructure: what matters are the metadata that classify and organize social content. This does not make the social ties of sets unimportant: sets can be central to our identity and we may feel closeness with and trust others simply because they share attributes with us: people with the same religious beliefs, who like the same kind of music, or who support the same football team, for instance. Set modes of interaction are typically one-to-many and many-to one, though they can enable many-to-many engagement.
Social Software Support for Social Forms
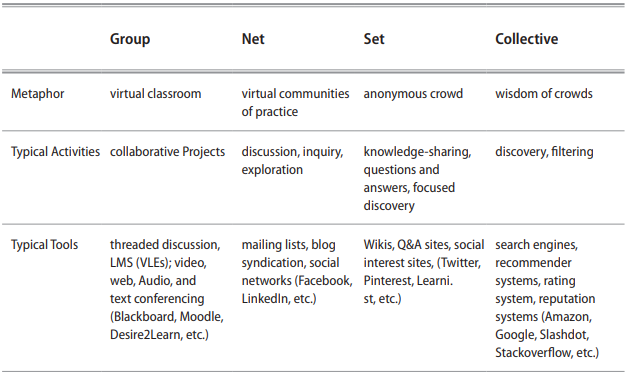
Different kinds of social software support various social forms in diverse ways. Group-oriented systems tend to provide features like variable roles, restricted membership, and role-based permissions. Network-oriented systems tend to provide features like friending, linking, and commenting. Set-oriented systems tend to provide tools like topic- or location-based selections, tags, and categories. Very few substantial systems are limited to any single mode, but most have varying strengths or emphases in different areas. The more complex or multi-featured the system, the more likely it will be to support different modes, and most can, with sufficient effort, be cajoled into performing different roles even though their intended purpose may be at odds with a particular use. Table 3.1 provides a few examples of popular social systems categorized according to what we perceive to be the predominant forms they support at the time of writing: but the reader must bear in mind that this is a shifting arena where changes and enhancements are constantly being introduced and that our perceptions may differ from those of others that use them in different ways. These are all soft technologies composed not just of tools but of the methods, processes, and intentions of their users. Almost any tool can be ben to support almost any social form, even if the fit is poor.
Table 3.1 Support for social forms in some common social software.
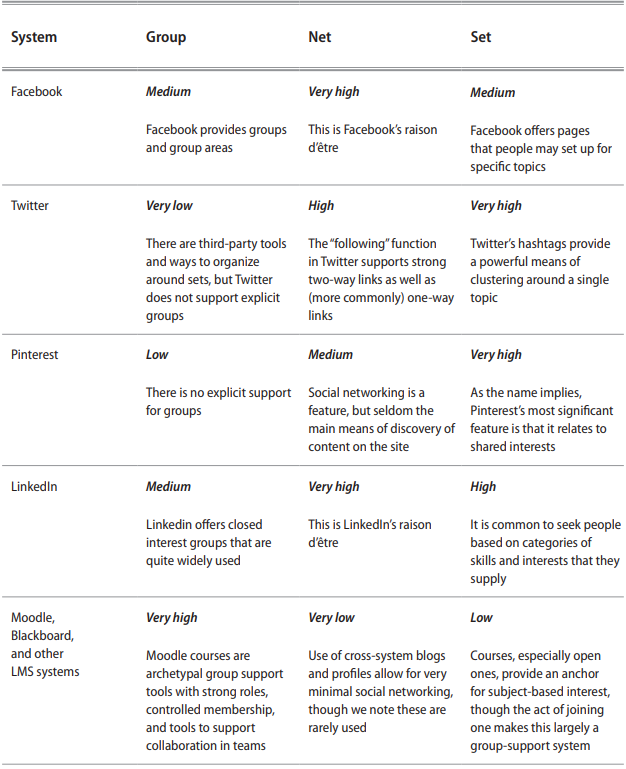
Many, if not most, social sites and software systems incorporate facilities to support and/or gain benefit from each social form. For instance, Facebook is primarily a social networking platform, yet it supports the formation of closed groups, individual-to-individual communication, and a host of collective aggregations such as voting systems, data mining to identify people you may know but have not connected to already, and add-in applications such as music/movie/ book recommenders. An archetypal group such as a face-to-face class may contain many networks of friends that extend beyond and within the group, its members may be categorized in sets relating to, say, ability, interests, or opinions, and collectives may occur in many ways, such as a teacher counting a show of hands or collating the results of clicker presses.
Intersections
There are many hybrid types of each of the main social structures we have identified that are as significant as the pure forms themselves. The “pure” forms of sets, nets, and groups may be mixed in different proportions to combine their features, producing some of the social organizational forms we are familiar with.
Group-Net: The Community of Practice
The classic intersection of a group and network is a community of practice (CoP). CoPs emerge, typically in workplace contexts, as networks of people who are within a group or groups. The notion of legitimate peripheral participation attests to the network-like features of a CoP, and yet there are many ways that members might regard them as cohesive units. It is helpful to think of these as clusters: a number of people in a network who share a purpose, practice, and often location, but without the explicit hierarchies, exclusions, and roles of a more defined group.
Group-Set: The Tribe/Community of Interest
Shifting from the pure group toward the set, communities of interest gather due to shared interests, and typically engage in more or less formal ways. They are often bound by interest in a topic more than by the group itself, though this may change over time. Some communities of interest occur at boundaries between sets and nets as well, if there are no formal kinds of engagement. When there is a shift beyond communities of interest toward more set-like engagement, we define this blurred category between groups and sets at the “set” end of the continuum as “tribes,” a label that applies not just to actual tribes but also to a range of forms that share some characteristics of sets and some of groups: these include companies, universities, nations, and academic groupings.
Like groups, many tribes have hierarchies, social norms, explicit and implicit rules, and shared purposes. In a learning context, unlike groups, they are seldom time-limited, and few individuals know everyone in the tribe. They are bound by one distinct shared attribute, but this always comes with a range of other attributes, otherwise they would be pure sets. For example, those who share the same religion will also be bound by moral codes, belief systems, and expectations of behaviour, or other features that mark them as members of the tribe. As they become more set-like—for example, Goths, fans of a hockey team, learning technology researchers—the deliberate hierarchies disappear, becoming more diffuse and abstract, though the characteristics that make them a set may still be firmly associated with their sense of identity.
Set-Net: The Circle
It is commonplace to divide networks into more or less arbitrary categories that are often described as ‘circles,’ such as in ‘my circle of friends.’ We might, say, think of sets of people we know who live nearby and those who don’t, or those who are friends and those we work with. Technologies such as Google+ Circles, Facebook Lists, and Elgg Collections are explicitly designed to allow us to classify people in multiple ways, reflecting the differences in how we relate to them, what we reveal about ourselves to them, and what we hide. Communities of interest may also occupy this blurred line between nets and sets, where the shared interest is the set attribute but where there are no formal or informal norms, rules, exclusions or inclusions. For example, followers of a particular band may come to know one another and cluster together at band concerts, without any formal, group-like constitution.
Kinds of Collections of People
As E. O. Wilson observed, “every person is a compulsive group-seeker” (2012, Chapter 24, Para. 10), a statement that is embodied in the phenomenal range of words that we have in the English language to distinguish different aggregations of people. In analyzing existing social forms to test our model, we came up with over 120 different words commonly used to refer to a collection of people, from alliances to workforces, without taking into account any of the millions of distinct proper nouns used to refer to specific groupings like banks, cities, countries, or scout troops. In our analysis, we discovered a few interesting things of note about this very incomplete example list. In the first place, many formal words relate to distinct organizational forms, especially those that occur in military, religious, business, and scholarly contexts—squads, sororities, flocks, federations, and the like. Bearing in mind that language has evolved slowly, this speaks to an important feature of many human groupings: they are technologized.
Many social groupings come with associated processes, methods, rules, legislations, procedures, rites of passage, rituals of entry and leaving, and are such an embedded feature that they have acquired their own vocabularies. Others categorize people according to things they share in common or that others perceive them as sharing in common such as race, class, dwelling place and so on, sometimes with implications that relate to other characteristics. Words like “tribe,” “nation,” “race,” “working class,” and “neighbours,” for instance, indicate set-like characteristics that are used to fit people into slots.
Identifying Social Forms
In determining the dominant social forms, the distinctions we have made are:
- Sets are social forms where people may have no knowledge of others in the set but are clustered by commonalities between them. This may lead to strong identification and trust in some cases, but not typically.
- Groups are social forms where individuals deliberately join others with shared goals and identify with group norms and behaviours.
- Nets are social forms where the connections between individuals and sometimes clusters of individuals are what bind them together.
While sometimes it can be hard to identify whether one collection of people is a group, net, or set, there are rules of thumb to follow. In brief:
- If the social entity persists even if there are no participants, likely it is a group.
- If there is little consequence to knowing who is involved and the topic is the most significant aspect, it is likely to be a set.
- If identifiable people are recognized by one another, it is probably a net.
In many cases, it is possible for all three to be true. It is helpful to visualize the typology as a Venn diagram of overlapping sets, the overlap indicating not only that we choose to see a particular social form within a collection of people and this does not exclude us from having other perspectives—all groups are both sets and nets, for instance—but also that there are often overlaps and fuzzy borders between them. Figure 3.2 shows the typology with some examples of the kinds of social entities relevant to learning found within them. Alternatively, you could see it as a continuum (see figure 3.3).
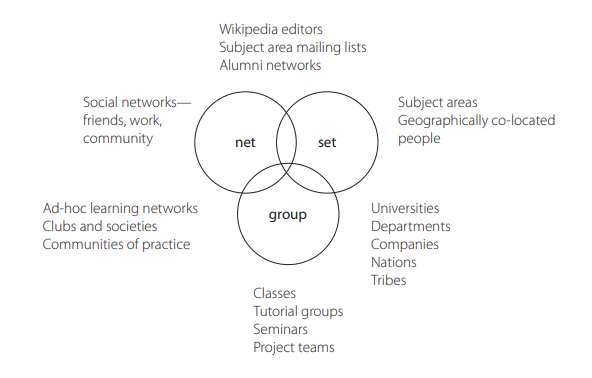
Figure 3.2 Venn diagram view of the typology
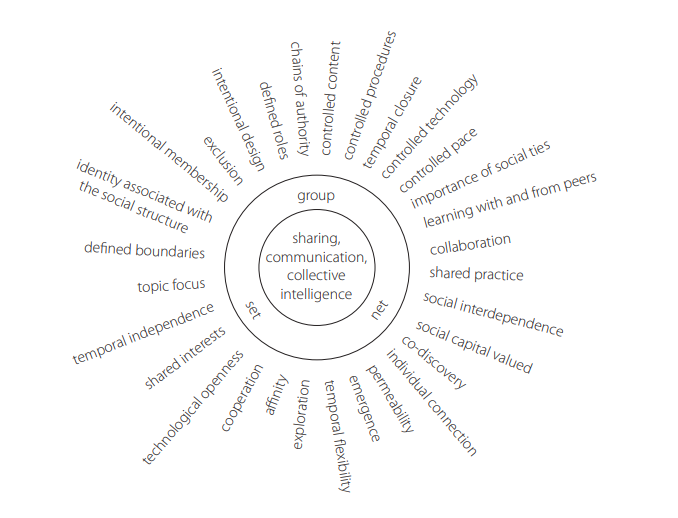
Figure 3.3 View of the typology as a continuum.
Each social form blends into the next. For example, many tribal forms such as affinity groups like hockey fans, Goths, or actor network theorists, are closer to sets than groups; others, like universities, nations, and international conferences are more group-like. Communities of practice exist somewhere on the continuum between groups and nets, often with limited or non-existent power structures but showing greater intentional cohesiveness than a simple network. The notion of blending is useful as it suggests an analogy to colours: an infinite variety of different shades and hues can be created by combining the three primary colours.
Collectives
Having defined the three social forms, we now turn our attention to collectives, which are perhaps the most intriguing of entities enabled by social software. Collectives, as we use the term, make the crowd behave as a single actor. They are not social forms like groups, nets, and sets, but are the machine- and/or human-aggregated results of the activities of a collection of individuals. Collectives achieve value by extracting information from the individual, group, set, and network activities of people, and then using that information to perform some action. Typically in cyberspace, these activities are aggregated by software and the results presented through computer interfaces, but humans can intentionally perform the aggregation role too. However, there need be no external agent involved for a collective to form: the individuals who form the crowd may themselves perform the aggregation, leading to emergent behaviours of the crowd.
Prior to the advent of the Internet, intentional collectives were used in, for instance, voting in elections or shows of hands in a classroom, but unintentional collectives occur in a more widespread manner, such as the formation of distinct footpaths in forests, the gathering of crowds around a street entertainer, and the movements of the stock market.
On the Internet, there are perhaps millions of applications that create value through aggregation, analysis, processing, and re-presentation of crowd activities, collecting user actions such as links placed on web pages (e.g., Google PageRank), photo and video tags, annotations and downloads (e.g., Flickr, YouTube, Instagram), article or solution evaluations (e.g., Digg, Mixx, Slashdot, StackOverflow), recommendations (e.g., Amazon, ratemyteacher.ca), and those that employ individuals’ reputations for some other purpose (e.g., eBay). Crowd behaviour can be mined from implicit choices or contributions made at the individual, group, or network levels, from explicit behaviours such as rating or tagging, or by combinations of each approach. Collectives generally improve in value as the size of the group’s/ network’s/ set’s sampled actions grows. When large numbers of resources are sorted, annotated, and rated by many, for example, the resultant resource listing can gain considerable collective value compared to a list rated by a single unknown individual.
Collectives behave as active agents within a system in ways that are analogous to the agency of human beings: in fairly predictable ways they make choices, value statements, expressions of belief, and act to bring about changes in the behaviour of others. This is of great importance in the context of learning in networks and sets because, in the absence of a formal teaching or cognitive presence, collectives often play that role. Collectives may sometimes act as mirrors of the group mind, or aspects of network consciousness that system designers or members of the crowd have chosen as significant. Because they represent chosen aspects of group, set, or network activity, the reflection of the collective mind is always shown through a distorting mirror that may be aggregating, refining, concentrating, selecting, filtering, averaging or otherwise processing aspects of crowd behaviour.
Typically, but not exclusively, collectives affect their own members in an iterative and self-organizing cycle. For instance, in social navigation, cues are often emphasized or de-emphasized as a result of individuals within a group or network moving around a system, which in turn affects the later navigation of that same group or network. However, this does not have to be the case. For example, the results of voting for a candidate by one group may influence the voting behaviour of another, or the tagging of photos within a system such as Flickr may influence the behaviour of outsiders and visitors to that system’s resources.
Size of Groups, Networks, and Sets
E.O. Wilson notes that “to form groups, drawing visceral comfort and pride from familiar fellowship, and to defend the group enthusiastically against rival group— these are among the absolute universals of human nature and hence of culture” (2012, Chapter 7, Para. 1). Groups in early human societies reached practical limits that were related to their function as humans evolved. The limits were constrained by available food sources to support communities, difficulties of coordination and allocation of work, and the laws of physics. Family-sized groups and workgroups are not viable persistent units in evolutionary terms because there are insufficient gains to be had from the division of labour and spread of innovation (Ridley, 2010). However, to extend beyond a certain size in the past required complex structures that evolved quite late in our species development, such as macrodemes and trade.
Moreover, with limited means of communicating over long distances, interactions were, of necessity, local: physics places limits on how far a voice can carry or the distance at which a person can be seen. While large herds are possible in many species, they emerge through individuals’ coordination with others in the vicinity (Miller, 2010). For coordination of the kind seen in human communities, large sizes posed distinct limits.
British psychologist Robin Dunbar (1993) examined the size of groups among many primate species. He noted that the size of the group is related to the amount of social grooming engaged in by that species. Humans, however, have much larger brains than most primates, and limiting our interactions to those with whom we could be mutually engaged in social hair grooming would be both costly in time and likely very boring. Dunbar used statistical mapping techniques to suggest that our brains allow us to expand the size of groups with which we can interact and “can have a genuinely social relationship, the kind of relationship that goes without knowing who they are and how they relate to us” (1996, p. 77). Based on the size of our brains and validated by observations of both primitive and modern communities, online groups, army units, businesses, and other groups, Dunbar estimated this size is 150 persons, often referred to as Dunbar’s Number. Interestingly, this coincides broadly with what Caporael (1997) distinguished as “macrodemes”: originally seasonal gatherings of bands (demes of around 30 individuals that could sustainably hunt together) and later instantiated as the typical size of villages for around 15,000 years.
In reality, we operate in groups of significantly greater size than Dunbar’s number suggests, though we may not, and in many cases cannot have a personal relationship with all the people in them. Companies, towns, universities, countries, religions, and many other group forms have developed primarily through the use of hierarchies and processes, methods and technologies that facilitate the exchange of knowledge between them. As Dunbar (1993) himself notes, language makes it possible for us to form groups with hierarchies and divisions of labour, so the actual size of human groups is considerably larger than what our brain capacity alone would suggest is possible (p. 689).
But what of broader networks in a technologically mediated age? Dunbar’s notion of relationships in virtual spaces in the mid-1990s was decidedly jaded. He felt deception and fraud by “shadowy ciphers” would result in such an excess of deceit that face-to-face interaction would be necessary to restore trust, resulting in the number of trustworthy acquaintances conforming to earlier norms of around 150. However, technology changes that, and he was probably wrong in the first place. Apart from anything else, the definition of a “genuinely social relationship” that he uses is neither clear nor precise. Moreover, far from reducing genuine human interaction, it appears that the connections formed online strengthen and increase those that are face-to-face. As a probable result of improved Internet and mobile contact, the average number of friends whom American adults see in person grew 20% in the five years between 2002 and 2007 (Rainie & Wellman, 2012). More recent research suggests that the number of networked ties maintained by individuals in present-day developed societies tends to be closer to 600 (DiPrete, Gelman, McCormick, Teitler, & Zheng, 2011; T. H. McCormick, Salganick, & Zheng, 2010) and Dunbar himself explains close ties as only one of a series of layers of embedded relationships (Rainie & Wellman, 2012).
Donath (2007) brought the arguments on group size in virtual space to bear on popular social networks such as MySpace and LinkedIn. Using signalling theory, she notes the means by which individuals signal to each other using fashion, linguistic shortcuts, and public displays of “friendships” to build and maintain social networks and trust. Her speculations appear to explain the ways that sets can transition into networks and groups. Sets are, however, unbound by intrinsic size restrictions. They can be as small as an individual or as large as the population of the universe: we are all in the set of physical things, for example. All that is required for a set of unlimited size is the capacity to identify and present it. Modern search engines, classification schemes, aggregation tools, and filters make it possible to engage with enormous sets of people.
There is a loose correlation between size and the levels of our social typology. Most groups are smaller than most networks; many networks are smaller than many sets. However, technological mediation can make groups, nets, and sets of any size a possibility.
Aggregation and the “wisdom of crowds” arise at many levels, but the results generally become more useful as numbers increase and the benefits of large aggregation among otherwise non-related choices become apparent. This is the power of the long tail (C. Anderson, 2004), whereby even very small tendencies and interests arise in significant enough numbers to be of value. More is nearly always better. A classic example of a collective is the fairground game of guessing the number of candies in a jar. In this collective, a number of independent decisions which are, when considered individually likely to be wrong, are usually, when averaged together, very close to correct (Surowiecki, 2004). However, when there are only two people guessing, it is far less likely to be accurate than when there are a hundred, and the accuracy rises when there are a thousand. In the online world, Amazon’s success at predicting books you will like is, in large measure, due to the number of people’s independent choices that are available. If there were fewer people than books, to take an extreme example, it is quite unlikely that the results would be valuable.
Summary of the Values of Different Social Forms and Collectives
When designing a social system to support learning, it is important to bear in mind what kinds of activities and what goals are intended, and to choose approaches and social forms that best serve the needs identified. To summarize the main strengths and weaknesses of each form:
- Groups offer the greatest value when the object of knowing is known and the process of knowing is complex. They are especially helpful when a sustained effort is needed. Groups are powerful motivators, exploiting our innate need for belonging and the ways that we have grown up and/ or evolved to live in hierarchies. However, groups require commitment and come with a large overhead of design and management; they are also expensive. Tools built to support groups should normally provide support for roles, processes, and procedures.
- Networks are embedded in practice, extend beyond the specifiable, and allow us to benefit from diversity and knowledge that transcends boundaries and easily specified objectives. Networks are great for topical, just-in-time learning, and expose us to serendipity and change. Networks, like groups, exploit social capital for both contribution and motivation. However, networks take effort to be exploited for learning. Without structure and guidance, we have to make decisions for ourselves. Generally speaking, network tools should help manage and sustain relationships, make and break connections, and deal with the organization of subsets of the network, with discretionary access and privacy controls.
- Sets are most useful when the knowledge we seek cannot be easily found in our groups and networks, when we need to know something but do not know who to ask. They are also a valuable means of gaining diverse insights and knowledge about a subject. However, like networks, they demand effort from us to decide what to learn in the first place and then to make decisions about reliability, relevance, and truthfulness. Sets need tools for organization and, on the whole, benefit most from the availability of collectives to support them.
- Collectives provide the means for us to make sense of, in particular, sets, to a lesser extent nets, and occasionally, groups. Like teachers, collectives tell us what to do, who to trust, what is interesting, and how to approach a subject. However, collectives are only as smart as the crowd, the means by which the crowd is selected, defined by the algorithms and presentations that perform the work. The learning needs, rather than simply the preferences, of their users should be supported.
The form or forms that an individual learner may make use of in his or her learning journey will always depend upon context and needs, but these will be codetermined by external structures like the need for assessment and accreditation, the formal and informal rules of behaviour in a given context, as well as other financial, personal, ethical, and social constraints.
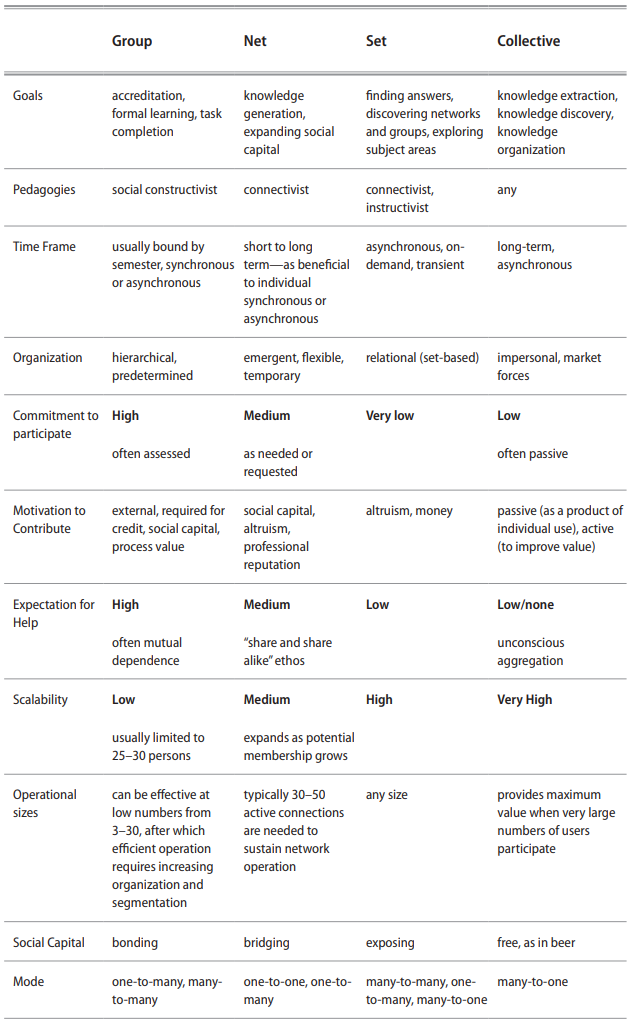
Table 3.2 summarizes a range of attributes and their typical values of groups, nets, sets, and collectives so that the reader may match them with the needs of their own communities with which they are concerned.
Table 3.2 Groups, nets, sets, and collectives compared.
In many cases, the lines between the different social forms may be blurred or shifting. It is common, for example, to encourage communities of practice that share emergent properties with networks and, at least in their early stages of formation, have weak structures and limited hierarchies. Similarly, a tribal group may often be more set-like than group-like in terms of the interactions between people. For example, we may know no one in a large organization beyond our own groups, and so interactions beyond the group share many commonalities with interactions between strangers in a set. It is also, as we have observed, common for there to be blends of forms in any given community. There can be people that we know within an anonymous set, for instance, and we may have many crosscutting networks within and beyond the groups we are members of.
Conclusion
We have presented a typology of the kinds of aggregation that social software can support and of collectives that can emerge from them. It is not the only possible means of categorizing such things, but it makes sense of the different ways that social software systems can support a social learning process, and helps us to unpack the sometimes subtle differences between ways of teaching and learning on the Net. We hope to show, as the book progresses, that the differences (though sometimes blurred or mixed) are profound, and failure to recognize the kind of entity with which we are dealing can, at best, lead to lost opportunities and, at worst, can undermine the educational endeavour.
Choosing names is an important task, and getting the right name matters. As the British philosopher J.L. Austin put it, “Words are our tools, and, as a minimum, we should use clean tools: we should know what we mean and what we do not, and we must forearm ourselves against the traps that language sets us” (1979, p. 182). The names we have chosen were the result of much debate and cogitation, but they may not fit with your own understanding of the words. If that is so, then we ask that you suspend your existing preconceptions for a while and, if you wish, substitute words that you find more appropriate. It is not the words we use that are important here, but what they signify.