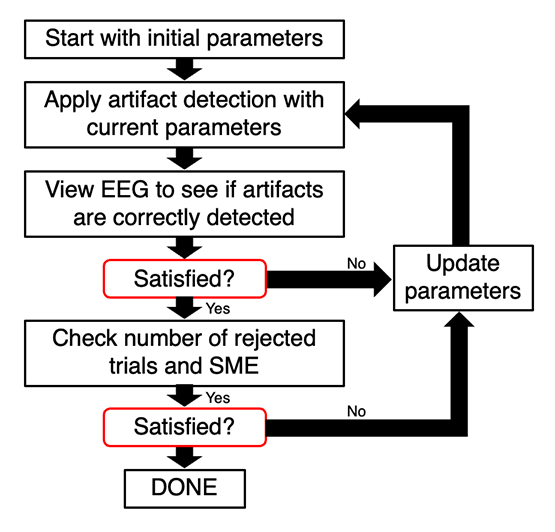
Many researchers use a preset artifact detection threshold for all participants, but this is not optimal. A threshold that works well for one participant might fail to flag all the blinks for another participants and might lead many non-blink epochs to be flagged in a yet another participant. I therefore recommend the interactive and iterative approach shown in Figure 8.1. It involves starting with an initial set of best-guess parameters, seeing whether these parameters adequately flag the epochs that should be rejected, and then adjusting the parameters as necessary until you are satisfied. As will be described in the next section, it also involves using the standardized measurement error (SME) to help you determine which parameters lead to the best balance of eliminating noisy trials while still having enough trials to obtain a good averaged ERP waveform.
Make sure you keep a record of the parameters you choose for each participant. I recommend using a spreadsheet for this. The example script at the end of the chapter shows you how a script can read the artifact detection parameters from a spreadsheet and then perform the artifact detection with these parameters. That will keep you from having a meltdown when you need to reprocess your data the seventh time. In fact, it’s a good idea to set the parameters manually and then immediately reprocess the data using a script with those parameters. It’s easy to make a mistake when you’re processing data by pointing and clicking in a GUI, and this approach of manually selecting the parameters and then implementing them in a script gives you the customized parameters that you want while avoiding point-and-click errors.
I find this iterative approach to be reasonably quick (5-10 minutes for most participants once you’ve become well practiced). And it does an excellent job of addressing the three types of problems that were described at the beginning of the chapter. However, other approaches may be better in certain cases.
If you have a small number of trials per participant (as in many infant studies) or a small number of highly valuable participants (as in some studies of lesion patients), you may want to manually mark epochs for rejection during the visual inspection process. That is, you can mark an epoch for rejection by simply clicking on it (select EEGLAB > Tools > Reject data epochs > Reject by inspection; see the ERPLAB documentation for information about how to integrate these marks with ERPLAB). However, this approach is slow and awkward when you have more than ~20 trials per participant or more than ~20 participants.
Another alternative is to use one of the algorithms that automatically set the parameters for each participant (e.g., Jas et al., 2017; Nolan et al., 2010; Talsma, 2008). This approach is best suited for very large datasets (e.g., >100 participants), and it should be followed by manual verification for each participant. Note that most current algorithms assess the overall noise level of the data rather than assessing the data quality for the specific amplitude or latency measure that you will be using as the main dependent variable to test your scientific hypotheses (which is what the SME does). As a result, these algorithms may not actually select optimal parameters in terms of statistical power.
Figure 8.1. Iterative procedure for setting artifact detection parameters. If no satisfactory parameters can be found without exceeding the maximal allowable percentage of trials with artifacts, then the participant must be excluded from the final analyses.