Figure 3. Beyond just hearing your name from the clamor at a party, other words or concepts, particularly unusual or significant ones to you, can also snag your attention. [Image: Catholic Church (England and Wales), https://goo.gl/c3O8B3, CC BY-NC-SA2.0, goo.gl/iF4hmM]
Selective attention is the ability to select certain stimuli in the environment to process, while ignoring distracting information. One way to get an intuitive sense of how attention works is to consider situations in which attention is used. A party provides an excellent example for our purposes. Many people may be milling around, there is a dazzling variety of colors and sounds and smells, the buzz of many conversations is striking. There are so many conversations going on; how is it possible to select just one and follow it? You don’t have to be looking at the person talking; you may be listening with great interest to some gossip while pretending not to hear.
However, once you are engaged in conversation with someone, you quickly become aware that you cannot also listen to other conversations at the same time. You also are probably not aware of how tight your shoes feel or of the smell of a nearby flower arrangement. On the other hand, if someone behind you mentions your name, you typically notice it immediately and may start attending to that (much more interesting) conversation. This situation highlights an interesting set of observations. We have an amazing ability to select and track one voice, visual object, etc., even when a million things are competing for our attention, but at the same time, we seem to be limited in how much we can attend to at one time, which in turn suggests that attention is crucial in selecting what is important. How does it all work?
DICHOTIC LISTENING STUDIES
This cocktail party scenario is the quintessential example of selective attention, and it is essentially what some early researchers tried to replicate under controlled laboratory conditions as a starting point for understanding the role of attention in perception (e.g., Cherry, 1953; Moray, 1959). In particular, they used dichotic listening and shadowing tasks to evaluate the selection process. Dichotic listening simply refers to the situation when two messages are presented simultaneously to an individual, with one message in each ear. In order to control which message the person attends to, the individual is asked to repeat back or “shadow” one of the messages as he hears it. For example, let’s say that a story about a camping trip is presented to John’s left ear, and a story about Abe Lincoln is presented to his right ear. The typical dichotic listening task would have John repeat the story presented to one ear as he hears it. Can he do that without being distracted by the information in the other ear?
People can become pretty good at the shadowing task, and they can easily report the content of the message that they attend to. But what happens to the ignored message? Typically, people can tell you if the ignored message was a man’s or a woman’s voice, or other physical characteristics of the speech, but they cannot tell you what the message was about. In fact, many studies have shown that people in a shadowing task were not aware of a change in the language of the message (e.g., from English to German; Cherry, 1953), and they didn’t even notice when the same word was repeated in the unattended ear more than 35 times (Moray,1959)! Only the basic physical characteristics, such as the pitch of the unattended message, could be reported.
On the basis of these types of experiments, it seems that we can answer the first question about how much information we can attend to very easily: not very much. We clearly have a limited capacity for processing information for meaning, making the selection process all the more important. The question becomes: How does this selection process work?
MODELS OF SELECTIVE ATTENTION
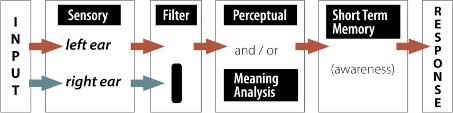
Broadbent’s Filter Model. Many researchers have investigated how selection occurs and what happens to ignored information. Donald Broadbent was one of the first to try to characterize the selection process. His Filter Model was based on the dichotic listening tasks described above as well as other types of experiments (Broadbent, 1958). He found that people select information on the basis of physical features: the sensory channel (or ear) that a message was coming in, the pitch of the voice, the color or font of a visual message. People seemed vaguely aware of the physical features of the unattended information, but had no knowledge of the meaning. As a result, Broadbent argued that selection occurs very early, with no additional processing for the unselected information. A flowchart of the model might look like this:
Figure 4. This figure shows information going in both the left and right ears. Some basic sensory information, such as pitch, is processed, but the filter only allows the information from one ear to be processed further. Only the information from the left ear is transferred to short-term memory (STM) and conscious awareness, and then further processed for meaning. That means that the ignored information never makes it beyond a basic physical analysis.
TREISMAN’S ATTENUATION MODEL
Broadbent’s model makes sense, but if you think about it you already know that it cannot account for all aspects of the Cocktail Party Effect. What doesn’t fit? The fact is that you tend to hear your own name when it is spoken by someone, even if you are deeply engaged in a conversation. We mentioned earlier that people in a shadowing experiment were unaware of a word in the unattended ear that was repeated many times—and yet many people noticed their own name in the unattended ear even it occurred only once.
Anne Treisman (1960) carried out a number of dichotic listening experiments in which she presented two different stories to the two ears. As usual, she asked people to shadow the message in one ear. As the stories progressed, however, she switched the stories to the opposite ears. Treisman found that individuals spontaneously followed the story, or the content of the message, when it shifted from the left ear to the right ear. Then they realized they were shadowing the wrong ear and switched back.
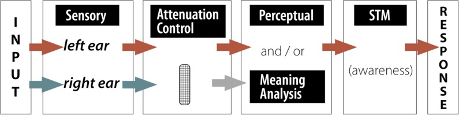
Results like this, and the fact that you tend to hear meaningful information even when you aren’t paying attention to it, suggest that we do monitor the unattended information to some degree on the basis of its meaning. Therefore, the filter theory can’t be right to suggest that unattended information is completely blocked at the sensory analysis level. Instead, Treisman suggested that selection starts at the physical or perceptual level, but that the unattended information is not blocked completely, it is just weakened or attenuated. As a result, highly meaningful or pertinent information in the unattended ear will get through the filter for further processing at the level of meaning. The figure below shows information going in both ears, and in this case there is no filter that completely blocks nonselected information. Instead, selection of the left ear information strengthens that material, while the nonselected information in the right ear is weakened. However, if the preliminary analysis shows that the nonselected information is especially pertinent or meaningful (such as your own name), then the Attenuation Control will instead strengthen the more meaningful information.
Figure 5. ATTENUATION MODEL
LATE SELECTION MODELS
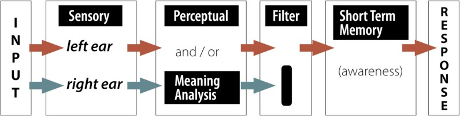
Other selective attention models have been proposed as well. A late selection or response selection model proposed by Deutsch and Deutsch (1963) suggests that all information in the unattended ear is processed on the basis of meaning, not just the selected or highly pertinent information. However, only the information that is relevant for the task response gets into conscious awareness. This model is consistent with ideas of subliminal perception; in other words, that you don’t have to be aware of or attending a message for it to be fully processed for meaning.
Figure 6. LATE SELECTION MODEL
You might notice that this figure looks a lot like that of the Early Selection model—only the location of the selective filter has changed, with the assumption that analysis of meaning occurs before selection occurs, but only the selected information becomes conscious.
MULTIMODE MODEL
Why did researchers keep coming up with different models? Because no model really seemed to account for all the data, some of which indicates that non-selected information is blocked completely, whereas other studies suggest that it can be processed for meaning. The multimode model addresses this apparent inconsistency, suggesting that the stage at which selection occurs can change depending on the task. Johnston and Heinz (1978) demonstrated that under some conditions, we can select what to attend to at a very early stage and we do not process the content of the unattended message very much at all. Analyzing physical information, such as attending to information based on whether it is a male or female voice, is relatively easy; it occurs automatically, rapidly, and doesn’t take much effort. Under the right conditions, we can select what to attend to on the basis of the meaning of the messages.
However, the late selection option—processing the content of all messages before selection—is more difficult and requires more effort. The benefit, though, is that we have the flexibility to change how we deploy our attention depending upon what we are trying to accomplish, which is one of the greatest strengths of our cognitive system.
This discussion of selective attention has focused on experiments using auditory material, but the same principles hold for other perceptual systems as well. Neisser (1979) investigated some of the same questions with visual materials by superimposing two semi-transparent video clips and asking viewers to attend to just one series of actions. As with the auditory materials, viewers often were unaware of what went on in the other clearly visible video. Twenty years later, Simons and Chabris (1999) explored and expanded these findings using similar techniques, and triggered a flood of new work in an area referred to as inattentional blindness. We touch on those ideas below, and you can also refer to another Noba Module, Failures of Awareness: The Case of Inattentional Blindness for a more complete discussion.