
4.11: Chord Classification by a Multilayer Perceptron
- Page ID
- 35739

Artificial neural networks provide a medium in which to explore empiricism, for they acquire knowledge via experience. This knowledge is used to mediate an input-output mapping and usually takes the form of a distributed representation. Distributed representations provide some of the putative connectionist advantages over classical cognitive science: damage resistance, graceful degradation, and so on. Unfortunately, distributed representations are also tricky to interpret, making it difficult for them to provide new theories for cognitive science.
However, interpreting the internal structures of multilayered networks, though difficult, is not impossible. To illustrate this, let us consider a multilayer perceptron trained to classify different types of musical chords. The purpose of this section is to discuss the role of hidden units, to demonstrate that networks that use hidden units can also be interpreted, and to introduce a decidedly connectionist notion called the coarse code.
Chords are combinations of notes that are related to musical scales, where a scale is a sequence of notes that is subject to certain constraints. A chromatic scale is one in which every note played is one semitone higher than the previous note. If one were to play the first thirteen numbered piano keys of Figure \(\PageIndex{1}\) in order, then the result would be a chromatic scale that begins on a low C and ends on another C an octave higher.
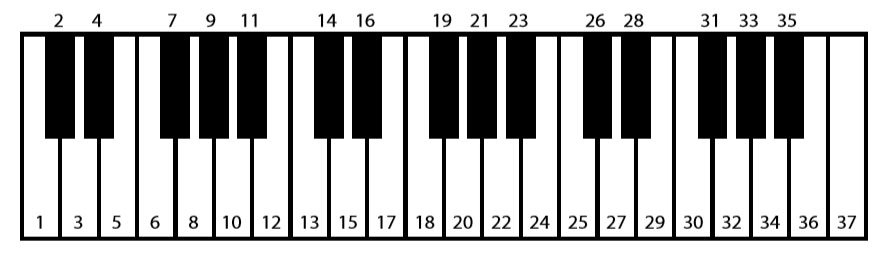
A major scale results by constraining a chromatic scale such that some of its notes are not played. For instance, the C major scale is produced if only the white keys numbered from 1 to 13 in Figure \(\PageIndex{1}\) are played in sequence (i.e., if the black keys numbered 2, 4, 7, 9, and 11 are not played).

The musical notation for the C major scale is provided in the sequence of notes illustrated in the first part of Figure \(\PageIndex{2}\). The Greeks defined a variety of modes for each scale; different modes were used to provoke different aesthetic experiences (Hanslick, 1957). The C major scale in the first staff of Figure \(\PageIndex{2}\) is in the Ionian mode because it begins on the note C, which is the root note, designated I, for the C major key.
One can define various musical chords in the context of C major in two different senses. First, the key signature of each chord is the same as C major (i.e., no sharps or flats). Second, each of these chords is built on the root of the C major scale (the note C). For instance, one basic chord is the major triad. In the key of C major, the root of this chord—the chord’s lowest note—is C (e.g., piano key #1 in Figure \(\PageIndex{1}\)). The major triad for this key is completed by adding two other notes to this root. The second note in the triad is 4 semitones higher than C, which is the note E (the third note in the major scale in Figure \(\PageIndex{2}\)). The third note in the triad is 3 semitones higher than the second note, which in this case is G (the fifth note in the major scale in Figure \(\PageIndex{2}\)). Thus the notes C-E-G define the major triad for the key of C; this is the first chord illustrated in Figure \(\PageIndex{2}\).
A fourth note can added on to any major triad to create an “added note” tetrachord (Baker, 1982). The type of added note chord that is created depends upon the relationship between the added note and the third note of the major triad. If the added note is 4 semitones higher than the third note, the result is a major 7th chord, such as the Cmaj7 illustrated in Figure \(\PageIndex{2}\). If the added note is 3 semitones higher than the third note, the result is a dominant 7th chord such as the C7 chord presented in Figure \(\PageIndex{2}\). If the added note is 2 semitones higher than the third note, then the result is a 6th chord, such as the C6 chord illustrated in Figure \(\PageIndex{2}\).
The preceding paragraphs described the major triad and some added note chords for the key of C major. In Western music, C major is one of twelve possible major keys. The set of all possible major keys is provided in Figure \(\PageIndex{3}\), which organizes them in an important cyclic structure, called the circle of fifths.
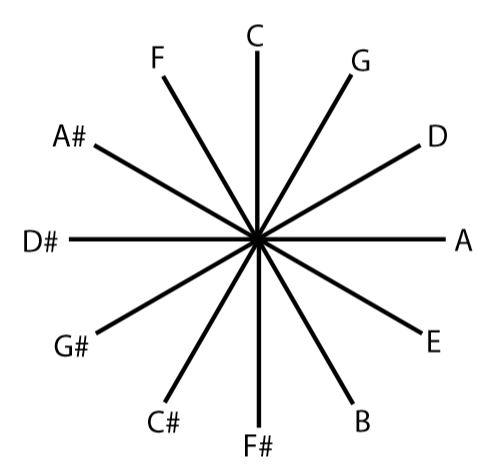
Figure \(\PageIndex{3}\). The circle of fifths.
The circle of fifths includes all 12 notes in a chromatic scale, but arranges them so that adjacent notes in the circle are a musical interval of a perfect fifth (i.e., 7 semitones) apart. The circle of fifths is a standard topic for music students, and it is foundational to many concepts in music theory. It is provided here, though, to be contrasted later with “strange circles” that are revealed in the internal structure of a network trained to identify musical chords.
Any one of the notes in the circle of fifths can be used to define a musical key and therefore can serve as the root note of a major scale. Similarly, any one of these notes can be the root of a major triad created using the pattern of root + 4 semitones + 3 semitones that was described earlier for the key of C major (Baker, 1982). Furthermore, the rules described earlier can also be applied to produce added note chords for any of the 12 major key signatures. These possible major triads and added note chords were used as inputs for training a network to correctly classify different types of chords, ignoring musical key.
A training set of 48 chords was created by building the major triad, as well as the major 7th, dominant 7th, and 6th chord for each of the 12 possible major key signatures (i.e., using each of the notes in Figure \(\PageIndex{3}\) as a root). When presented with a chord, the network was trained to classify it into one of the four types of interest: major triad, major 7th, dominant 7th, or 6th. To do so, the network had 4 output units, one for each type of chord. For any input, the network learned to turn the correct output unit on and to turn the other three output units off.
The input chords were encoded with a pitch class representation (Laden & Keefe, 1989; Yaremchuk & Dawson, 2008). In a pitch class representation, only 12 input units are employed, one for each of the 12 different notes that can appear in a scale. Different versions of the same note (i.e., the same note played at different octaves) are all mapped onto the same input representation. For instance, notes 1, 13, 25, and 37 in Figure \(\PageIndex{1}\) all correspond to different pitches but belong to the same pitch class—they are all C notes, played at different octaves of the keyboard. In a pitch class representation, the playing of any of these input notes would be encoded by turning on a single input unit—the one unit used to represent the pitch class of C.
A pitch class representation of chords was used for two reasons. First, it requires a very small number of input units to represent all of the possible stimuli. Second, it is a fairly abstract representation that makes the chord classification task difficult, which in turn requires using hidden units in a network faced with this task.
Why chord classification might be difficult for a network when pitch class encoding is employed becomes evident by thinking about how we might approach the problem if faced with it ourselves. Classifying the major chords is simple: they are the only input stimuli that activate three input units instead of four. However, classifying the other chord types is very challenging. One first has to determine what key the stimulus is in, identify which three notes define its major chord component, and then determine the relationship between the third note of the major chord component and the fourth “added” note. This is particularly difficult because of the pitch class representation, which throws away note-order information that might be useful in identifying chord type.
It was decided that the network that would be trained on the chord classification task would be a network of value units (Dawson & Schopflocher, 1992b). The hidden units and output units in a network of value units use a Gaussian activation function, which means that they behave as if they carve two parallel planes through a pattern space. Such networks can be trained with a variation of the generalized delta rule. This type of network was chosen for this problem for two reasons. First, networks of value units have emergent properties that make them easier to interpret than other types of networks trained on similar problems (Dawson, 2004; Dawson et al., 1994). One reason for this is because value units behave as if they are “tuned” to respond to very particular input signals. Second, previous research on different versions of chord classification problems had produced networks that revealed elegant internal structure (Yaremchuk & Dawson, 2005, 2008).
The simplest network of value units that could learn to solve the chord classification problem required three hidden units. At the start of training, the value of m for each unit was initialized as 0. (The value of m for a value unit is analogous to a threshold in other types of units [Dawson, Kremer, & Gannon, 1994; Dawson & Schopflocher, 1992b]; if a value unit’s net input is equal to m then the unit generates a maximum activity of 1.00.) All connection weights were set to values randomly selected from the range between –0.1 and 0.1. The network was trained with a learning rate of 0.01 until it produced a “hit” for every output unit on every pattern. Because of the continuous nature of the activation function, a hit was defined as follows: a value of 0.9 or higher when the desired output was 1, and a value of 0.1 or lower when the desired output was 0. The network that is interpreted below learned the chord classification task after 299 presentations of the training set.
What is the role of a layer of hidden units? In a perceptron, which has no hidden units, input patterns can only be represented in a pattern space. Recall from the discussion of Figure 4-2 that a pattern space represents each pattern as a point in space. The dimensionality of this space is equal to the number of input units. The coordinates of each pattern’s point in this space are given by the activities of the input units. For some networks, the positioning of the points in the pattern space prevents some patterns from being correctly classified, because the output units are unable to adequately carve the pattern space into the appropriate decision regions.
In a multilayer perceptron, the hidden units serve to solve this problem. They do so by transforming the pattern space into a hidden unit space (Dawson, 2004). The dimensionality of a hidden unit space is equal to the number of hidden units in the layer. Patterns are again represented as points in this space; however, in this space their coordinates are determined by the activities they produce in each hidden unit. The hidden unit space is a transformation of the pattern space that involves detecting higher-order features. This usually produces a change in dimensionality—the hidden unit space often has a different number of dimensions than does the pattern space—and a repositioning of the points in the new space. As a result, the output units are able to carve the hidden unit space into a set of decision regions that permit all of the patterns, repositioned in the hidden unit space, to be correctly classified.
This account of the role of hidden units indicates that the interpretation of the internal structure of a multilayer perceptron involves answering two different questions. First, what kinds of features are the hidden units detecting in order to map patterns from the pattern space into the hidden unit space? Second, how do the output units process the hidden unit space to solve the problem of interest? The chord classification network can be used to illustrate how both questions can be addressed.
First, when mapping the input patterns into the hidden unit space, the hidden units must be detecting some sorts of musical regularities. One clue as to what these regularities may be is provided by simply examining the connection weights that feed into them, provided in Table \(\PageIndex{1}\).
| Input Note | Hidden 1 | Hidden 1 Class | Hidden 2 | Hidden 2 Class | Hidden 3 | Hidden 3 Class |
|---|---|---|---|---|---|---|
| B | 0.53 | Circle of Major Thirds 1 | 0.12 | Circle of Major Thirds 1 | 0.75 | Circle of Major Seconds 1 |
| D# | 0.53 | 0.12 | 0.75 | |||
| G | 0.53 | 0.12 | 0.75 | |||
| A | -0.53 | Circle of Major Thirds 2 | -0.12 | Circle of Major Thirds 2 | 0.75 | |
| C# | -0.53 | -0.12 | 0.75 | |||
| F | -0.53 | -0.12 | 0.75 | |||
| C | 0.12 | Circle of Major Thirds 3 | -0.53 | Circle of Major Thirds 3 | -0.77 | Circle of Major Seconds 2 |
| G# | 0.12 | -0.53 | -0.77 | |||
| E | 0.12 | -0.53 | -0.77 | |||
| F# | -0.12 | Circle of Major Thirds 4 | 0.53 | Circle of Major Thirds 4 | -0.77 | |
| A# | -0.12 | 0.53 | -0.77 | |||
| D | -0.12 | 0.53 | -0.77 |
Table \(\PageIndex{3}\). Connection weights from the 12 input units to each of the three hidden units. Note that the first two hidden units adopt weights that assign input notes to the four circles of major thirds. The third hidden unit adopts weights that assign input notes to the two circles of major seconds.
In the pitch class representation used for this network, each input unit stands for a distinct musical note. As far as the hidden units are concerned, the “name” of each note is provided by the connection weight between the input unit and the hidden unit. Interestingly, Table \(\PageIndex{1}\) reveals that all three hidden units take input notes that we would take as being different (because they have different names, as in the circle of fifths in Figure \(\PageIndex{3}\)) and treat them as being identical. That is, the hidden units assign the same “name,” or connection weight, to input notes that we would give different names to.
Furthermore, assigning the same “name” to different notes by the hidden units is not done randomly. Notes are assigned according to strange circles, that is, circles of major thirds and circles of major seconds. Let us briefly describe these circles, and then return to an analysis of Table \(\PageIndex{1}\).
The circle of fifths (Figure \(\PageIndex{3}\)) is not the only way in which notes can be arranged geometrically. One can produce other circular arrangements by exploiting other musical intervals. These are strange circles in the sense that they would very rarely be taught to music students as part of a music theory curriculum. However, these strange circles are formal devices that can be as easily defined as can be the circle of fifths.
For instance, if one starts with the note C and moves up a major second (2 semitones) then one arrives at the note D. From here, moving up another major second arrives at the note E. This can continue until one circles back to C but an octave higher than the original, which is a major second higher than A#. This circle of major seconds captures half of the notes in the chromatic scale, as is shown in the top part of Figure \(\PageIndex{4}\). A complementary circle of major seconds can also be constructed (bottom circle of Figure \(\PageIndex{4}\)); this circle contains all the remaining notes that are not part of the first circle.
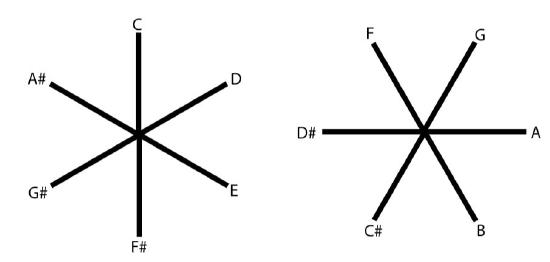
Figure \(\PageIndex{4}\). The two circles of major seconds.
An alternative set of musical circles can be defined by exploiting a different musical interval. In each circle depicted in Figure \(\PageIndex{5}\), adjacent notes are a major third (4 semitones) apart. As shown in Figure \(\PageIndex{5}\) four such circles are possible.
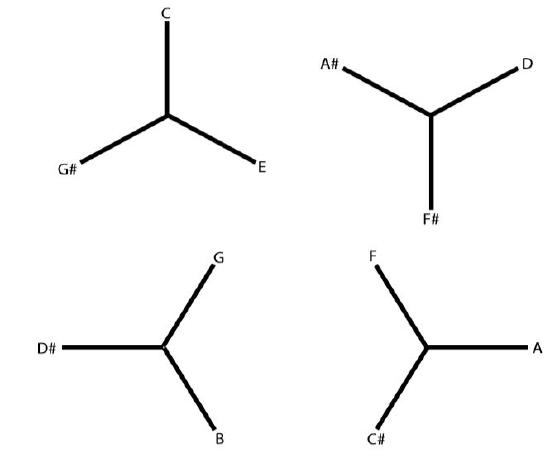
What do these strange circles have to do with the internal structure of the network trained to classify the different types of chords? A close examination of Table \(\PageIndex{1}\) indicates that these strange circles are reflected in the connection weights that feed into the network’s hidden units. For Hidden Units 1 and 2, if notes belong to the same circle of major thirds (Figure \(\PageIndex{5}\)), then they are assigned the same connection weight. For Hidden Unit 3, if notes belong to the same circle of major seconds (Figure \(\PageIndex{4}\)), then they are assigned the same connection weight. In short, each of the hidden units replaces the 12 possible different note names with a much smaller set, which equates notes that belong to the same circle of intervals and differentiates notes that belong to different circles.
Further inspection of Table \(\PageIndex{1}\) reveals additional regularities of interest. Qualitatively, both Hidden Units 1 and 2 assign input notes to equivalence classes based on circles of major thirds. They do so by using the same note “names”: 0.53, 0.12, –0.12, and –0.53. However, the two hidden units have an important difference: they assign the same names to different sets of input notes. That is, notes that are assigned one connection weight by Hidden Unit 1 are assigned a different connection weight by Hidden Unit 2.
The reason that the difference in weight assignment between the two hidden units is important is that the behavior of each hidden unit is not governed by a single incoming signal, but is instead governed by a combination of three or four input signals coming from all of the units. The connection weights used by the hidden units place meaningful constraints on how these signals are combined.
Let us consider the role of the particular connection weights used by the hidden units. Given the binary nature of the input encoding, the net input of any hidden unit is simply the sum of the weights associated with each of the activated input units. For a value unit, if the net input is equal to the value of the unit’s m then the output generates a maximum value of 1.00. As the net input moves away from m in either a positive or negative direction, activity quickly decreases. At the end of training, the values of m for the three hidden units were 0.00, 0.00, and –0.03 for Hidden Units 1, 2, and 3, respectively. Thus for each hidden unit, if the incoming signals are essentially zero—that is if all the incoming signals cancel each other out—then high activity will be produced.
Why then do Hidden Units 1 and 2 use the same set of four connection weights but assign these weights to different sets of input notes? The answer is that these hidden units capture similar chord relationships but do so using notes from different strange circles.
This is shown by examining the responses of each hidden unit to each input chord after training. Table \(\PageIndex{2}\) summarizes these responses, and shows that each hidden unit generated identical responses to different subsets of input chords.
| Input Chord | Activation | |||
| Chord | Chord Root | Hid1 | Hid2 | Hid3 |
|
Major |
C,D,A,F#,G#,A# | 0.16 | 0.06 | 0.16 |
| C#,D#,F,G,A,B | 0.06 | 0.16 | 0.16 | |
|
Major7 |
C,D,A,F#,G#,A# | 0.01 | 0.12 | 1.00 |
| C#,D#,F,G,A,B | 0.12 | 0.01 | 1.00 | |
|
Dom7 |
C,D,A,F#,G#,A# | 0.27 | 0.59 | 0.00 |
| C#,D#,F,G,A,B | 0.59 | 0.27 | 0.00 | |
|
6th |
C,D,A,F#,G#,A# | 0.84 | 0.03 | 1.00 |
| C#,D#,F,G,A,B | 0.03 | 0.84 | 1.00 | |
Table \(\PageIndex{2}\). The activations produced in each hidden unit by different subsets of input chords.
From Table \(\PageIndex{2}\), one can see that the activity of Hidden Unit 3 is simplest to describe: when presented with a dominant 7th chord, it produces an activation of 0 and a weak activation to a major triad. When presented with either a major 7th or a 6th chord, it produces maximum activity. This pattern of activation is easily explained by considering the weights that feed into Hidden Unit 3 (Table \(\PageIndex{1}\)). Any major 7th or 6th chord is created out of two notes from one circle of major seconds and two notes from the other circle. The sums of pairs of weights from different circles cancel each other out, producing near-zero net input and causing maximum activation.
In contrast, the dominant 7th chords use three notes from one circle of major seconds and only one from the other circle. As a result, the signals do not cancel out completely, given the weights in Table \(\PageIndex{1}\). Instead, a strong non-zero net input is produced, and the result is zero activity.
Finally, any major triad involves only three notes: two from one circle of major seconds and one from the other. Because of the odd number of input signals, cancelation to zero is not possible. However, the weights have been selected so that the net input produced by a major triad is close enough to m to produce weak activity.
The activation patterns for Hidden Units 1 and 2 are more complex. It is possible to explain all of them in terms of balancing (or failing to balance) signals associated with different circles of major thirds. However, it is more enlightening to consider these two units at a more general level, focusing on the relationship between their activations.
In general terms, Hidden Units 1 and 2 generate activations of different intensities to different classes of chords. In general, they produce the highest activity to 6th chords and the lowest activity to major 7th chords. Importantly, they do not generate the same activity to all chords of the same type. For instance, for the 12 possible 6th chords, Hidden Unit 1 generates activity of 0.84 to 6 of them but activity of only 0.03 to the other 6 chords. An inspection of Table \(\PageIndex{2}\) indicates that for every chord type, both Hidden Units 1 and 2 generate one level of activity with half of them, but produce another level of activity with the other half.
The varied responses of these two hidden units to different chords of the same type are related to the circle of major seconds (Figure \(\PageIndex{4}\)). For example, Hidden Unit 1 generates a response of 0.84 to 6th chords whose root note belongs to the top circle of Figure \(\PageIndex{4}\), and a response of 0.03 to 6th chords whose root note belongs to the bottom circle of Figure \(\PageIndex{4}\). Indeed, for all of the chord types, both of these hidden units generate one response if the root note belongs to one circle of major seconds and a different response if the root note belongs to the other circle.
Furthermore, the responses of Hidden Units 1 and 2 complement one another: for any chord type, those chords that produce low activity in Hidden Unit 1 produce higher activity in Hidden Unit 2. As well, those chords that produce low activity in Hidden Unit 2 produce higher activity in Hidden Unit 1. This complementing is again related to the circles of major seconds: Hidden Unit 1 generates higher responses to chords whose root belongs to one circle, while Hidden Unit 2 generates higher responses to chords whose roots belong to the other. Which circle is “preferred” by a hidden unit depends on chord type.
Clearly each of the three hidden units is sensitive to musical properties. However, it is not clear how these properties support the network’s ability to classify chords. For instance, none of the hidden units by themselves pick out a set of properties that uniquely define a particular type of chord. Instead, hidden units generate some activity to different chord types, suggesting the existence of a coarse code.
In order to see how the activities of the hidden units serve as a distributed representation that mediates chord classification, we must examine the hidden unit space. The hidden unit space plots each input pattern as a point in a space whose dimensionality is determined by the number of hidden units. The coordinates of the point in the hidden unit space are the activities produced by an input pattern in each hidden unit. The three-dimensional hidden unit space for the chord classification network is illustrated in Figure \(\PageIndex{6}\).
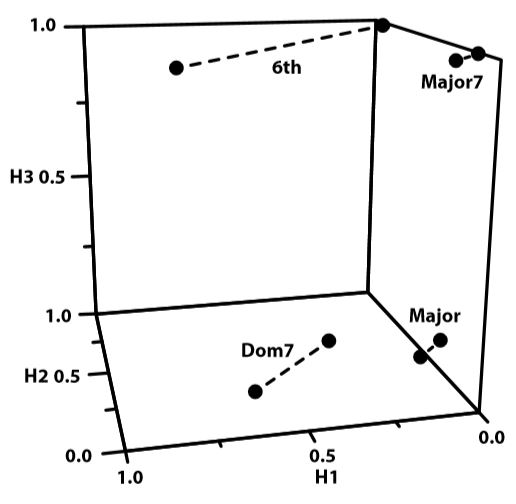
Because the hidden units generate identical responses to many of the chords, instead of 48 different visible points in this graph (one for each input pattern), there are only 8. Each point represents 6 different chords that fall in exactly the same location in the hidden unit space.
The hidden unit space reveals that each chord type is represented by two different points. That these points capture the same class is represented in Figure \(\PageIndex{6}\) by joining a chord type’s points with a dashed line. Two points are involved in defining a chord class in this space because, as already discussed, each hidden unit is sensitive to the organization of notes according to the two circles of major seconds. For each chord type, chords whose root belongs to one of these circles are mapped to one point, and chords whose root belongs to the other are mapped to the other point. Interestingly, there is no systematic relationship in the graph that maps onto the two circles. For instance, it is not the case that the four points toward the back of the Figure \(\PageIndex{6}\) cube all map onto the same circle of major seconds.
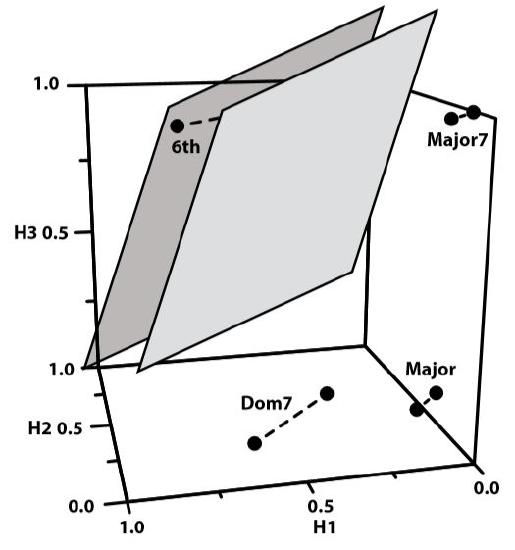
Figure \(\PageIndex{7}\). An example of output unit partitioning of the hidden unit space for the chord classification network.
Figure \(\PageIndex{7}\) illustrates how the output units can partition the points in the hidden unit space in order to classify chords. Each output unit in this network is a value unit, which carves two parallel hyperplanes through a pattern space. To solve the chord classification problem, the connection weights and the bias of each output unit must take on values that permit these two planes to isolate the two points associated with one chord type from all of the other points in the space. Figure \(\PageIndex{7}\) shows how this would be accomplished by the output unit that signals that a 6th chord has been detected.