Probability sampling is a technique in which every unit in the population has a chance (non-zero probability) of being selected in the sample, and this chance can be accurately determined. Sample statistics thus produced, such as sample mean or standard deviation, are unbiased estimates of population parameters, as long as the sampled units are weighted according to their probability of selection. All probability sampling have two attributes in common: (1) every unit in the population has a known non-zero probability of being sampled, and (2) the sampling procedure involves random selection at some point. The different types of probability sampling techniques include:
Simple random sampling. In this technique, all possible subsets of a population (more accurately, of a sampling frame) are given an equal probability of being selected. The probability of selecting any set of n units out of a total of N units in a sampling frame is 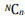 . Hence, sample statistics are unbiased estimates of population parameters, without any weighting. Simple random sampling involves randomly selecting respondents from a sampling frame, but with large sampling frames, usually a table of random numbers or a computerized random number generator is used. For instance, if you wish to select 200 firms to survey from a list of 1000 firms, if this list is entered into a spreadsheet like Excel, you can use Excel’s RAND() function to generate random numbers for each of the 1000 clients on that list. Next, you sort the list in increasing order of their corresponding random number, and select the first 200 clients on that sorted list. This is the simplest of all probability sampling techniques; however, the simplicity is also the strength of this technique. Because the sampling frame is not subdivided or partitioned, the sample is unbiased and the inferences are most generalizable amongst all probability sampling techniques.
. Hence, sample statistics are unbiased estimates of population parameters, without any weighting. Simple random sampling involves randomly selecting respondents from a sampling frame, but with large sampling frames, usually a table of random numbers or a computerized random number generator is used. For instance, if you wish to select 200 firms to survey from a list of 1000 firms, if this list is entered into a spreadsheet like Excel, you can use Excel’s RAND() function to generate random numbers for each of the 1000 clients on that list. Next, you sort the list in increasing order of their corresponding random number, and select the first 200 clients on that sorted list. This is the simplest of all probability sampling techniques; however, the simplicity is also the strength of this technique. Because the sampling frame is not subdivided or partitioned, the sample is unbiased and the inferences are most generalizable amongst all probability sampling techniques.
Systematic sampling. In this technique, the sampling frame is ordered according to some criteria and elements are selected at regular intervals through that ordered list. Systematic sampling involves a random start and then proceeds with the selection of every 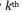 element from that point onwards, where k = N/n, where k is the ratio of sampling frame size N and the desired sample size n, and is formally called the sampling ratio. It is important that the starting point is not automatically the first in the list, but is instead randomly chosen from within the first k elements on the list. In our previous example of selecting 200 firms from a list of 1000 firms, you can sort the 1000 firms in increasing (or decreasing) order of their size (i.e., employee count or annual revenues), randomly select one of the first five firms on the sorted list, and then select every fifth firm on the list. This process will ensure that there is no overrepresentation of large or small firms in your sample, but rather that firms of all sizes are generally uniformly represented, as it is in your sampling frame. In other words, the sample is representative of the population, at least on the basis of the sorting criterion.
element from that point onwards, where k = N/n, where k is the ratio of sampling frame size N and the desired sample size n, and is formally called the sampling ratio. It is important that the starting point is not automatically the first in the list, but is instead randomly chosen from within the first k elements on the list. In our previous example of selecting 200 firms from a list of 1000 firms, you can sort the 1000 firms in increasing (or decreasing) order of their size (i.e., employee count or annual revenues), randomly select one of the first five firms on the sorted list, and then select every fifth firm on the list. This process will ensure that there is no overrepresentation of large or small firms in your sample, but rather that firms of all sizes are generally uniformly represented, as it is in your sampling frame. In other words, the sample is representative of the population, at least on the basis of the sorting criterion.
Stratified sampling. In stratified sampling, the sampling frame is divided into homogeneous and non-overlapping subgroups (called “strata”), and a simple random sample is drawn within each subgroup. In the previous example of selecting 200 firms from a list of 1000 firms, you can start by categorizing the firms based on their size as large (more than 500 employees), medium (between 50 and 500 employees), and small (less than 50 employees). You can then randomly select 67 firms from each subgroup to make up your sample of 200 firms. However, since there are many more small firms in a sampling frame than large firms, having an equal number of small, medium, and large firms will make the sample less representative of the population (i.e., biased in favor of large firms that are fewer in number in the target population). This is called non-proportional stratified sampling because the proportion of sample within each subgroup does not reflect the proportions in the sampling frame (or the population of interest), and the smaller subgroup (large-sized firms) is oversampled. An alternative technique will be to select subgroup samples in proportion to their size in the population. For instance, if there are 100 large firms, 300 mid-sized firms, and 600 small firms, you can sample 20 firms from the “large” group, 60 from the “medium” group and 120 from the “small” group. In this case, the proportional distribution of firms in the population is retained in the sample, and hence this technique is called proportional stratified sampling. Note that the non-proportional approach is particularly effective in representing small subgroups, such as large-sized firms, and is not necessarily less representative of the population compared to the proportional approach, as long as the findings of the non-proportional approach is weighted in accordance to a subgroup’s proportion in the overall population.
Cluster sampling. If you have a population dispersed over a wide geographic region, it may not be feasible to conduct a simple random sampling of the entire population. In such case, it may be reasonable to divide the population into “clusters” (usually along geographic boundaries), randomly sample a few clusters, and measure all units within that cluster. For instance, if you wish to sample city governments in the state of New York, rather than travel all over the state to interview key city officials (as you may have to do with a simple random sample), you can cluster these governments based on their counties, randomly select a set of three counties, and then interview officials from every official in those counties. However, depending on between-cluster differences, the variability of sample estimates in a cluster sample will generally be higher than that of a simple random sample, and hence the results are less generalizable to the population than those obtained from simple random samples.
Matched-pairs sampling. Sometimes, researchers may want to compare two subgroups within one population based on a specific criterion. For instance, why are some firms consistently more profitable than other firms? To conduct such a study, you would have to categorize a sampling frame of firms into “high profitable” firms and “low profitable firms” based on gross margins, earnings per share, or some other measure of profitability. You would then select a simple random sample of firms in one subgroup, and match each firm in this group with a firm in the second subgroup, based on its size, industry segment, and/or other matching criteria. Now, you have two matched samples of high-profitability and low-profitability firms that you can study in greater detail. Such matched-pairs sampling technique is often an ideal way of understanding bipolar differences between different subgroups within a given population.
Multi-stage sampling. The probability sampling techniques described previously are all examples of single-stage sampling techniques. Depending on your sampling needs, you may combine these single-stage techniques to conduct multi-stage sampling. For instance, you can stratify a list of businesses based on firm size, and then conduct systematic sampling within each stratum. This is a two-stage combination of stratified and systematic sampling. Likewise, you can start with a cluster of school districts in the state of New York, and within each cluster, select a simple random sample of schools; within each school, select a simple random sample of grade levels; and within each grade level, select a simple random sample of students for study. In this case, you have a four-stage sampling process consisting of cluster and simple random sampling.

