
2.2: Articulators and Airstream Mechanisms
- Page ID
- 111893
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)How Humans Produce Language, in Anderson's Essentials of Linguistics
Video Script
The field of phonetics studies the sounds of human speech. When we study speech sounds we can consider them from two angles. Acoustic phonetics, in addition to being part of linguistics, is also a branch of physics. It’s concerned with the physical, acoustic properties of the sound waves that we produce. We’ll talk some about the acoustics of speech sounds, but we’re primarily interested in articulatory phonetics, that is, how we humans use our bodies to produce speech sounds. Producing speech needs three mechanisms.
The first is a source of energy. Anything that makes a sound needs a source of energy. For human speech sounds, the air flowing from our lungs provides energy.
The second is a source of the sound: air flowing from the lungs arrives at the larynx. Put your hand on the front of your throat and gently feel the bony part under your skin. That’s the front of your larynx. It’s not actually made of bone; it’s cartilage and muscle. This picture shows what the larynx looks like from the front.
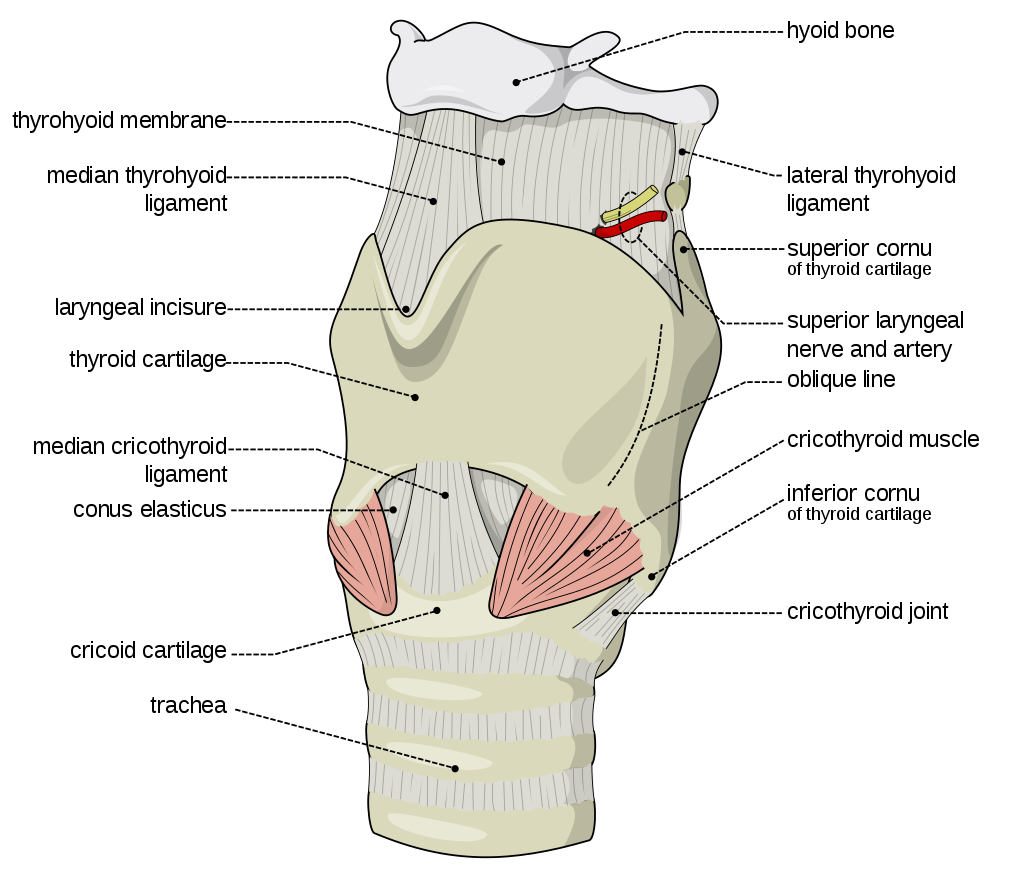
This next picture is a view down a person’s throat.
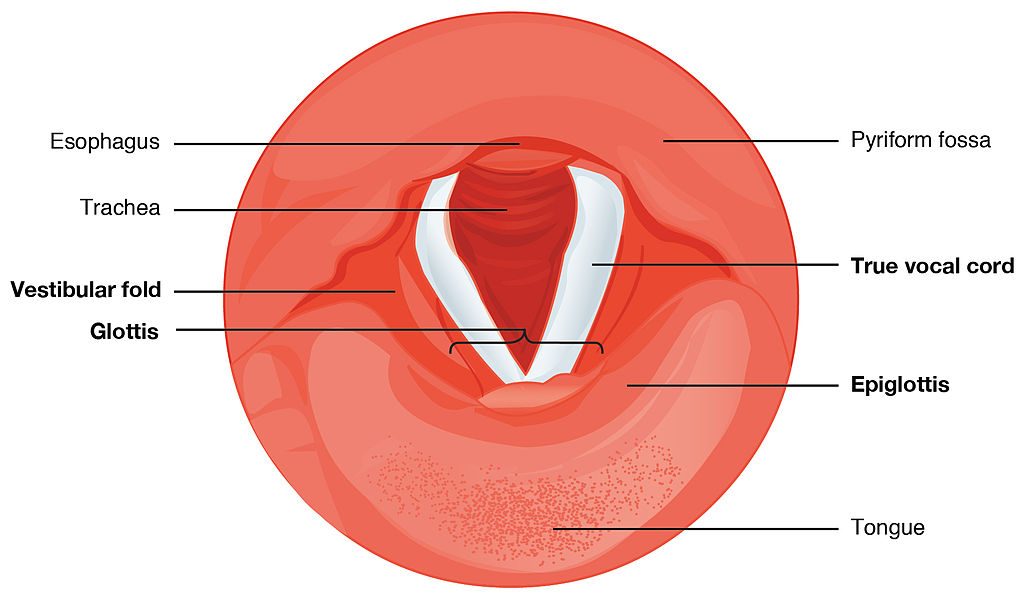
What you see here is that the opening of the larynx can be covered by two triangle-shaped pieces of skin. These are often called “vocal cords” but they’re not really like cords or strings. A better name for them is vocal folds.
The opening between the vocal folds is called the glottis.
We can control our vocal folds to make a sound. I want you to try this out so take a moment and close your door or make sure there’s no one around that you might disturb.
First I want you to say the word “uh-oh”. Now say it again, but stop half-way through, “Uh-”. When you do that, you’ve closed your vocal folds by bringing them together. This stops the air flowing through your vocal tract. That little silence in the middle of “uh-oh” is called a glottal stop because the air is stopped completely when the vocal folds close off the glottis.
Now I want you to open your mouth and breathe out quietly, “haaaaaaah”. When you do this, your vocal folds are open and the air is passing freely through the glottis.
Now breathe out again and say “aaah”, as if the doctor is looking down your throat. To make that “aaaah” sound, you’re holding your vocal folds close together and vibrating them rapidly.
When we speak, we make some sounds with vocal folds open, and some with vocal folds vibrating. Put your hand on the front of your larynx again and make a long “SSSSS” sound. Now switch and make a “ZZZZZ” sound. You can feel your larynx vibrate on “ZZZZZ” but not on “SSSSS”. That’s because [s] is a voiceless sound, made with the vocal folds held open, and [z] is a voiced sound, where we vibrate the vocal folds. Do it again and feel the difference between voiced and voiceless.
Now take your hand off your larynx and plug your ears and make the two sounds again with your ears plugged. You can hear the difference between voiceless and voiced sounds inside your head.
I said at the beginning that there are three crucial mechanisms involved in producing speech, and so far we’ve looked at only two:
- Energy comes from the air supplied by the lungs.
- The vocal folds produce sound at the larynx.
- The sound is then filtered, or shaped, by the articulators.
The oral cavity is the space in your mouth. The nasal cavity, obviously, is the space inside and behind your nose. And of course, we use our tongues, lips, teeth and jaws to articulate speech as well. In the next unit, we’ll look in more detail at how we use our articulators.
So to sum up, the three mechanisms that we use to produce speech are:
- respiration at the lungs,
- phonation at the larynx, and
- articulation in the mouth.
Check Yourself
- Answer
-
"Voiceless"
The reason: [p] is a voiceless sound. When we pronounce it on its own, our vocal cords don't vibrate.
- Answer
-
"Voiceless"
The reason: The last sound is [f], which is a voiceless sound. When we pronounce it on its own, our vocal cords don't vibrate.
- Answer
-
"Voiced"
The reason: The last sound is [m], which is a voiced sound. When we pronounce it on its own, our vocal cortds vibrate.
Articulators, in Anderson's Essentials of Linguistics
Video Script
We know that humans produce speech by bringing air from the lungs through the larynx, where the vocal folds might or might not vibrate. That airflow is then shaped by the articulators.

This image is called a sagittal section. It depicts the inside of your head as if we sliced right between your eyes and down the middle of your nose and mouth. This angle gives us a good view of the parts of the vocal tract that are involved in filtering airflow to produce speech sounds.
Let’s start at the front of your mouth, with your lips. If you make the sound “aaaaa” then round your lips, the sound of the vowel changes. We can also use our lips to block the flow of air completely, like in the consonants [b] and [p].
We also use our teeth to shape airflow. They don’t do much on their own, but we can place the tip of the tongue between the teeth, for sounds like [θ] and [ð]. Or we can bring the top teeth down against the bottom lip for [f] and [v].
If you put your finger in your mouth and tap the roof of your mouth, you’ll find that it’s bony. That is the hard palate. English doesn’t have very many palatal sounds, but we do raise the tongue towards the palate for the glide [j].
Now from where you have your finger on the roof of your mouth, slide it forward towards your top teeth. Before you get to the teeth, you’ll find a ridge, which is called the alveolar ridge. If you use the tip of the tongue to block airflow at the alveolar ridge, you get the sounds [t] and [d]. We also produce [l] and [n] at the alveolar ridge, and some people also produce the sounds [s] and [z] with the tongue at the alveolar ridge (though there are other ways of making the [s] sound.)
When we block airflow in the mouth but allow air to circulate through the nasal cavity, we get the nasal sounds [m] [n] and [ŋ].
Some languages also have nasal vowels. Make an “aaaaa” vowel again, then make it nasal. [aaaaa] [ããããã]
The articulator that you move to allow air into the nasal cavity is called the velum. You might also know it as the soft palate. For sounds made in the mouth, the velum rests against the back of the throat. But we can pull the velum away from the back of the throat and allow air into the nose. We can also block airflow by moving the body of the tongue up against the velum, to make the sounds [k] and [ɡ].
Farther back than the velum are the uvula and the pharynx, but English doesn’t use these articulators in its set of speech sounds.
Every different configuration of the articulators leads to a different acoustic output.
Check Yourself
- Answer
-
"Lips"
The reason: The first sound is [m], which is a bilabial sound. Only the lips are involved in that sound.
Which articulators are responsible for the final sound in the word wit?
- Answer
-
"Lips"
The reason: The first sound is [w], which is a bilabial sound. Only the lips are involved.
Note: It's actually a labio-velar sound, but more on that soon.
- Answer
-
"Lips and teeth"
The reason: The first sound is [f], which is a labiodental sound. Both the bottom lip and the top teeth are involved.
Articulators and Airstream Mechanisms, from Sarah Harmon
Video Script
There's only a little bit more than I’m going to add to Catherine Anderson's discussion on articulators and air stream mechanisms, not much more, because what she puts up there is really good really detailed and I can't do much better so I’ll let her take that wheel. There's only a couple of things I want to add.
When we talk about the air stream mechanism, yes, most all sounds that are used for human language are pulmonic, meaning that the air comes from the lungs and then goes out. It is there, and it is pushed out from the lungs all the way. There are, however, some languages that do include sounds that are not pulmonic; they can be either glottalic or velaric. Let me explain what those are.
Glottalic sounds you hear in a number of languages that are indigenous to South America; Quechua is one of them; the early version of it was spoken by the Inca Empire and continues to be spoken to this day. They have, for example, an egressive [t’]. So, take a regular [t] sound, and instead of that pulmonic [t] (the is pushed all the way from the lungs), if you are stopping the air also at the glottis and ejecting it out forcefully, that is what a glottalic sound is. It's an egressive, meaning the air flow coming out of the glottis. With the egressive, the air starts from the lungs, but it is stopped also at the glottis and then ejected it out, as I say, the [t’]. You can hear like a [t] but it's got more push behind it, and that is the sound. In theory, you could have an ingressive glottalic, but that doesn't really happen.
Velaric sounds, at the velum, meaning the air is stopped at the velum, the back of the mouth, and then pushed out. We have two different kinds: you have ingressive and egressive. With the egressive, air goes out and the famous one is blowing a raspberry. That is a bilabial, ingressive, fricative, velaric. Ingressive velaric, now we're talking about the very famous clicks that we hear in the Bantu languages. The Bantu languages are spoken in central and especially southern Africa. Zulu is, for example, a Bantu language; !Xhosa is a Bantu language; there's a few others. Even when I said that second language name, !Xhosa, and you heard that [click] in front, that's a click. We use clicks all the time, but maybe not to communicate within a human language. Certainly, a lot of us in Europe and the Americas, for example, when we want to call our pet will go right that little kissy sound. That the click you're pulling in air is the second comes from the back of the mouth and it's a bilabial ingressive velaric. Some of us do a different kind of velaric sound when we are disapproving of something. [tsk tsk] The tip of your tongue is up against the back of your teeth and you're sucking in, pulling in from the back of your mouth of the velum. Sometimes, some of these clicks are associated when we're trying to talk or communicate to our pack animals, like horses or oxen or donkeys. Those are all clicks.
When we're talking human language, there are some languages—and the Bantu family is one—that use clicks. It's really cool to see and hear. In the video below this one, you will see a song on YouTube. It's being sung by Miriam Makeba; she was a very famous South African singer. She is among a wide group of black artists from Africa, mostly South Africa. They're all speakers have a Bantu language and they're singing in those languages frequently. A lot of it came out in the jazz movements in the 60s and 70s; Miriam Makeba certainly was part of that. I love her music; her music is amazing and inspiring. Even if I cannot understand it most of the time, it's just the way she conveys sound. But what is really cool is she made a very common Bantu cultural song –I can't remember what exactly it's called in !Xhosa, but it is translated into French and English and etc, as “The Click Song.” It's a song about a beetle; she's going to explain more in this video. What is really cool, though, is she sings that in !Xhosa, and then the spelling of the !Xhosa words is there, and under it is the English. In the captioning you can watch and read and listen all at the same time.
Click languages are really awesome; they're amazing and they are unique to the Bantu languages. There are no other language families that are recorded in human history that have the sounds. So where did they come from? That's the mystery and discussion for another time.
"Qongqothwane" by Miriam Makeba, with captions in English and !Xhosa
Unfortunately, the video that I originally had in this text was taken off of YouTube; there are other videos of the same performance, but the captions are not there. Fortunately, I found a different performance of the same song with the captions in both !Xhosa and English. However, the video quality is quite poor.