
1: Data, Datasets, SPSS, and Frequency Distribution Tables
- Page ID
- 186579

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)A. Welcome to statistics!
1.1. Statistics in action: movies and monarchy
 I have an 8 year old, and so watch my fair share of kids movies. I kept feeling annoyed that these movies featured monarchies and not democracies. Even the happy endings did not seem to problematize rule by monarch. Why was this being valorized in the United States, and in 2023? However, perhaps as a sociologist I was just more sensitized to this, and/or it irked me so it stood out. How common is it really for these movies to feature royaldoms? If I wanted an answer, I knew… I’d have to turn to statistics!
I have an 8 year old, and so watch my fair share of kids movies. I kept feeling annoyed that these movies featured monarchies and not democracies. Even the happy endings did not seem to problematize rule by monarch. Why was this being valorized in the United States, and in 2023? However, perhaps as a sociologist I was just more sensitized to this, and/or it irked me so it stood out. How common is it really for these movies to feature royaldoms? If I wanted an answer, I knew… I’d have to turn to statistics!
Statistics: data, the practice of using data for research
Statistics is useful for unveiling group patterns and variability. Statistics is an important gateway into understanding and describing the social world. Statistics can advance our knowledge, improve decision-making, and enable us to make statements about populations. Statistics are used in all kinds of literature, and by all kinds of people trying to influence you, so being able to evaluate and understand statistical claims being made is also a critical skill.
B. Unit of Analysis
Unit of analysis: Who or what you are analyzing
What is the entity your data is about (what does each case represent)? What are you trying to make claims about? These answers need to match, and their answer is your unit of analysis.
What would I need to analyze to find out how common it is for kids movies to feature royaldoms?
Would I be looking at the characteristics of countries? No!
Individual people? No!
I would need to analyze movies. The unit of analysis for my study is individual movies.
When you look at a dataset, the unit of analysis is what each row (or case) represents—be it individual people, states, books, countries, songs, or something else. Often survey data is going to be of individual people, but even then the data may have been aggregated (grouped) such that you have data at a different level of analysis. For example, if you have graduation rates for different schools, the school is the unit of analysis.
The Institute on Taxation and Economic Policy (ITEP) analyzed the federal income taxes paid by S&P 500 and Fortune 500 corporations. They found that 39 profitable corporations collectively generated $122 billion in profit from 2018 to 2020 yet paid no federal income tax. According to ITEP, "T-Mobile reported the largest profits. It reported $11.5 billion in profits over this time but had a federal income tax liability of negative $80 million, meaning the company received $80 million in tax refunds."
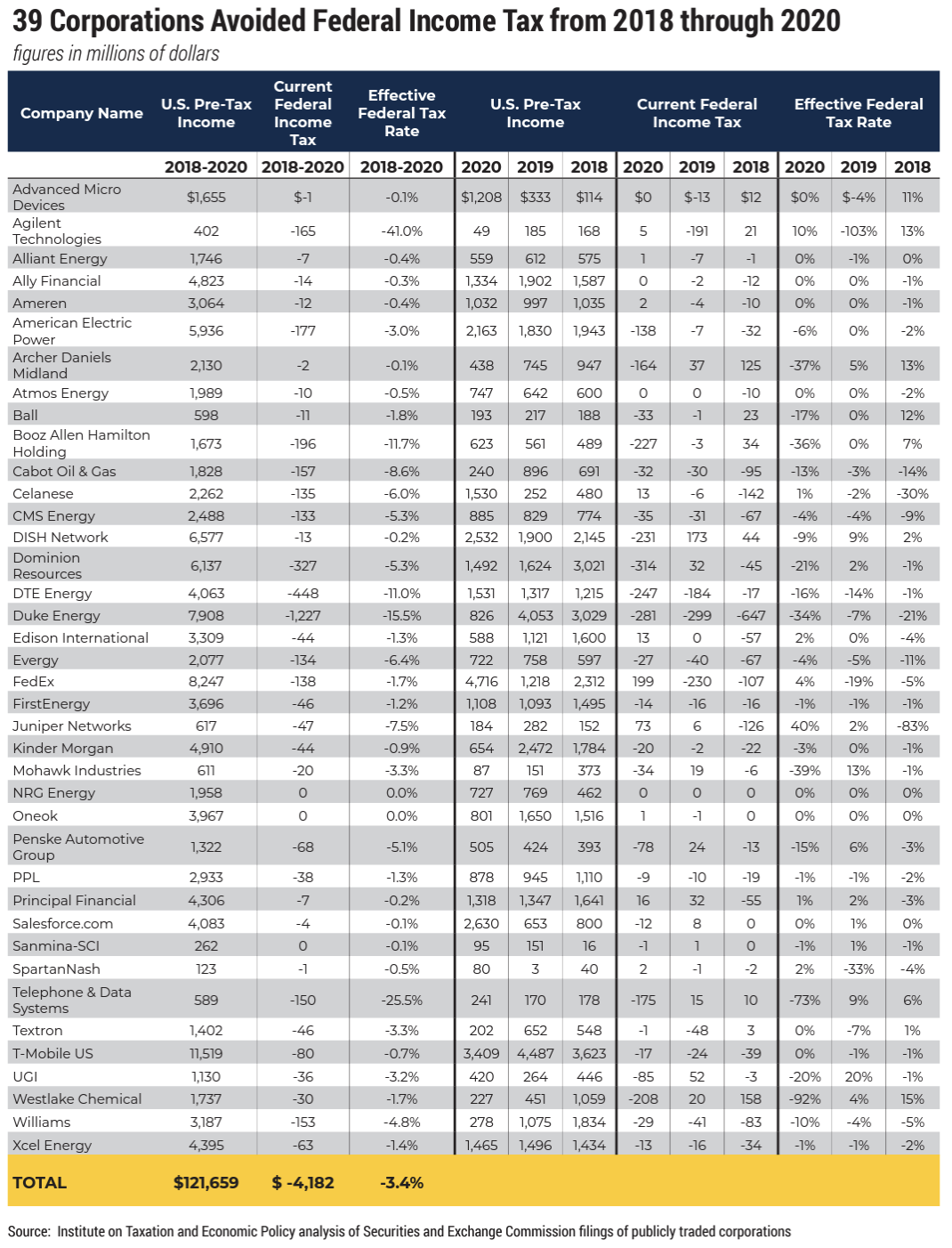
Source: https://itep.org/corporate-tax-avoid...-and-jobs-act/
What is the unit of analysis for this research?
What is ITEP analyzing? Here it is individual companies. Each row of the table is a company. They collected data on federal income taxes for each company.
While a study might give you ideas for future research at a different unit of analysis, you can only make claims at the unit of analysis you are using. For example, if I am studying university graduation rates (unit of analysis = individual universities), I may know that Harvard University has one of the highest graduation rates, around 98%. However, if I meet someone who goes to Harvard, I should not assume they will graduate, or if someone tells me they studied at Harvard, I should not assume they graduated (e.g., Bill Gates, Matt Damon, Mark Zuckerberg, William Randolph Hearst, and Pete Seeger all studied at Harvard but did not graduate). Likewise, I should not assume that the U.S. higher education graduation rate is comparable. (In reality, 64% of first-time, full-time undergraduate students who began seeking a bachelor's degree at a 4-year degree-granting institution in Fall 2014 had their degree within six years.)
C. Variables
Variable: Anything that can vary (differ), as opposed to something that must be constant (the same).
Other words you will come across that have a form of the word variable in them (variate) include:
univariate: having to do with one (uni) variable
bivariate: having to do with two (bi) variables
multivariate: having to do with multiple (multi) variables
Variables can be all kinds of things, such as height, temperature, birth weight, favorite color, income, partisan affiliation, number of pets in household, state voter turnout, etc. Generally large social datasets about individuals will all have variables like age, gender, and race. Age is a variable because not everyone has to have the same age.
If you are trying to ask a research question to find out if a relationship exists, you need to have variables that vary. If your variable is a constant, you won’t be able to find out relationships. For example, if you want to know if there is a relationship between age and political ideology, but all of the people in your dataset are the same age, you won’t be able to tell if political ideology varies as age changes.
For my study on movies and monarchy, the variables are the items I am going to collect attributes/characteristics regarding for each of the movies. This includes things like movie name, type of government represented in the movie, company that made the movie, and year the movie was released.
D. Data & Datasets
- It is estimated that less than 10% of U.S. drivers don't wear seatbelts, but that drivers without seatbelts constitute 50% of all vehicle passenger deaths.
- The average daily intake of plain water in the United States is about 4 cups per person.
- If current trends continue, within the next half-century Christians will constitute a minority of U.S.-Americans.
You have probably come across statistics that sound like these throughout your life. But where did they come from? These statistics were all the result of analyzing data, factual information that could be analyzed. The driver statistics came from the National Highway Traffic Safety Administration's (NHTSA) National Occupant Protection Use Survey and from Fatality Analysis Reporting System data NHTSA collects from every state government with information on all fatal crashes. The water statistic came from the National Health and Nutrition Examination Survey. The religion statistic was based on Pew Research Center analysis of their American Trends Panel, other Pew surveys, and NORC's General Social Survey. To do statistical analysis, first you need collected data. You can collect your own data through original research, or use data that has already been collected and conduct secondary data analysis.
Data: Information. In statistics, usually the values for variable(s).
Data is a plural word. The singular is datum.
If you asked 10 friends what religion they are, their responses constitute your raw data. For example, your raw data might look like this: {Unitarian, secular, refused to say, Protestant, Reconstructionist Jewish, Christian, recovering Catholic, Hindu, Muslim, half-Catholic half-Protestant}.
Back to my movies and monarchy study. I took a look at the top 20 kids films between 2015 (when my kiddo was born) and August 2023 (when I'm writing this). I determined what I'm considering the top 20 films for the purposes of this study by using Nash Information Services' data on the 25 top-grossing children's films ever in the United States, adjusted for ticket-price inflation (11 were from 2015-2023), and then added 9 more movies from their data on the top-grossing children's films worldwide (I added the first 9 films not already listed that were from 2015-2023, which were in their top 47 list). I collected information for each of these movies. I put my raw data into a spreadsheet using Microsoft Excel to keep track of them. Here's what my data looks like:
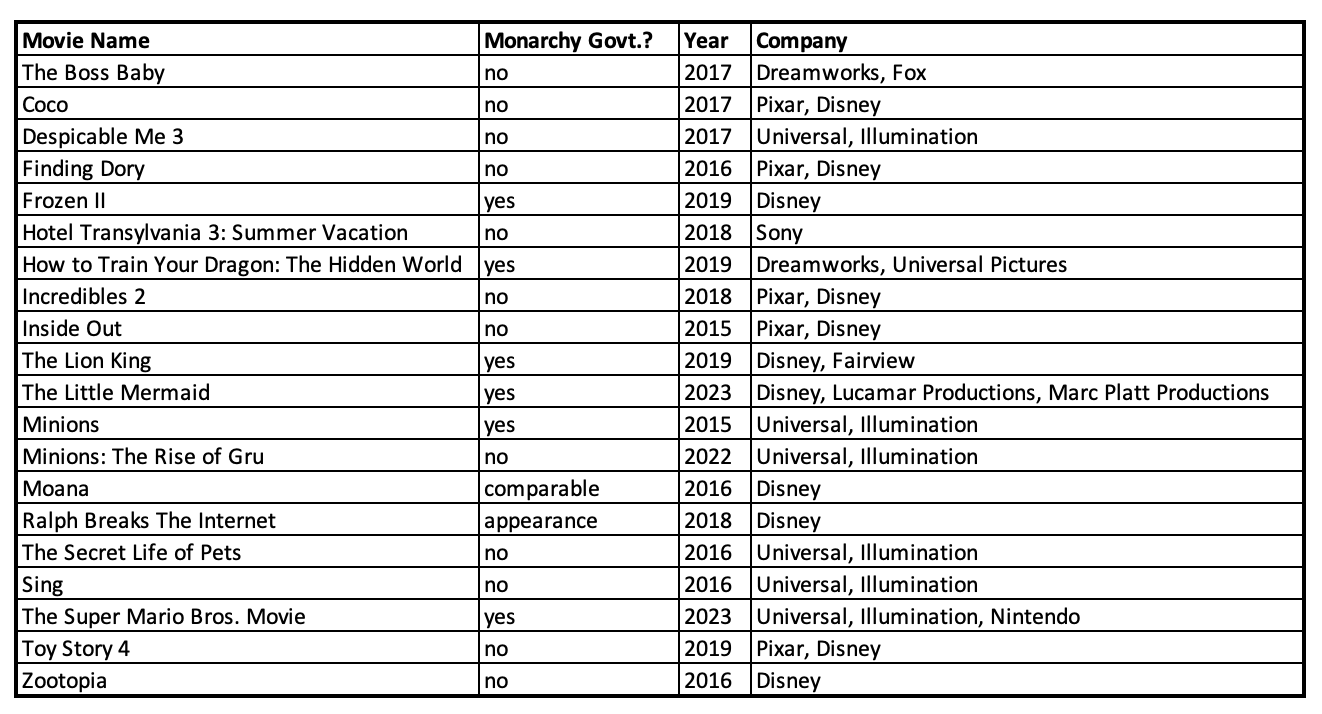
When I put a collection of data together in an organized fashion that can be used for analysis, it is called a dataset. In statistics, your dataset will be one file in spreadsheet form. A qualitative dataset could consist of something different like a set of interview transcripts.
Dataset: A collection of data organized for analysis
Because we're dealing with a small population of movies, I could do my own mathematical calculations, for example to figure out what percent of the movies featured monarchies. However, you are limited in what analyses you can do by hand, and what happens when you have a dataset with hundreds or thousands of cases? Either way, I would rather make the computer do the math for me. It's easier and more likely to be accurate. There are a number of statistical software programs. In sociology, the most popular ones include: SPSS, Stata, SAS, and R. One advantage of R is that it is free to use. This textbook uses SPSS. Specifically, the instructions for SPSS and the outputs shared here use SPSS Version 29. Other versions will be similar but sometimes have small differences. I like SPSS because I think it has the easiest learning curve. Its interface looks very similar to other applications you might use, and you can use drop-down menus to run commands and/or use its programming language. While you need a license to use SPSS, as an alternative, you can do almost all the analyses in this textbook using an open-source statistical software called PSPP, which is very similar to SPSS. It’s available for download here.
When you use statistical software, you want a dataset where all of your data is represented by numbers, not labels like "refused to say" or "Disney." The numbers that represent certain characteristics, values, or categories are called codes.
Codes: Numbers that represent variable attributes
Codebook: A document that tells you the codes for each variable in your dataset and what attributes they represent
When we enter data into a dataset to use in SPSS, we engage in coding, meaning we assign codes for each category of our variable. We then enter numbers into our dataset. For any given variable, a code matches particular numbers to particular responses. A codebook tells you the coding scheme for each variable—what the codes are for each variable and what they represent.
For my movies and monarchy study, I needed to get my dataset ready to analyze using SPSS. I replaced all of the text responses with numbers. I did not have to replace anything for year, because that was already a number. Here is my codebook:
Title
Name of Movie
1=The Boss Baby
2=Coco
3=Despicable Me 3
4=Finding Dory
5=Frozen II
6=Hotel Transylvania 3: Summer Vacation
7=How to Train Your Dragon: The Hidden World
8=Incredibles 2
9=Inside Out
10=The Lion King
11=The Little Mermaid
12=Minions
13=Minions: The Rise of Gru
14=Moana
15=Ralph Breaks The Internet
16=The Secret Life of Pets
17=Sing
18=The Super Mario Bros. Movie
19=Toy Story 4
20=Zootopia
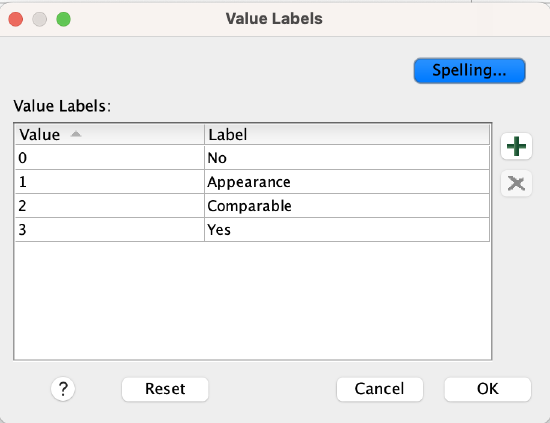
MonarchyPresent
Is monarchy a central form of government for the film's setting? Is there monarchy in the film?
0=no
1=appearance
2=comparable
3=yes
Year
Year of movie’s release
Company
Company/companies that produced and/or released the film
1=Dreamworks and Fox
2=Pixar and Disney
3=Universal and Illumination
4=Disney
5=Sony
6=Dreamworks and Universal
7=Disney and Fairview
8=Disney, Lucamar, and Marc Platt
9=Universal, Illumination, and Nintendo
So for example, for the Company variable, for Hotel Transylvania 3, I replaced "Sony" with "5".
Here's what my spreadsheet looked like after that:
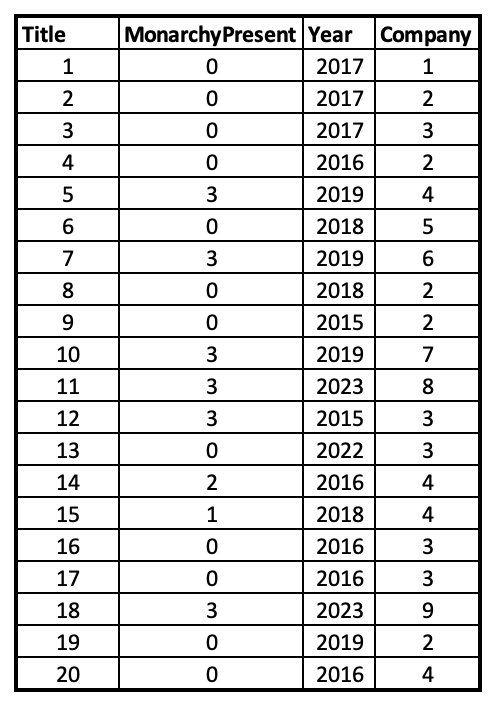
SPSS datasets are files that end in .sav (System for Analysis of Variables format). I can open up my Excel spreadsheet in SPSS as well, but all the data files specific to SPSS will end in .sav. To open up a dataset in SPSS, when you are in SPSS, go to File → Open → Data, and select your file.
SPSS datasets have a tab on the bottom that allows you to toggle between different views of the dataset. One view is called the Data View, which looks similar to the spreadsheet above. Each column is a unique variable and each row is a unique case. The other view is called Variable View, which gives you information about the variables: their name, "label," which is a description of the variable that will appear in many outputs, "values," which is the coding for the variable, and "missing," which will specify if any codes are supposed to be excluded from analyses.
Here is what my Monarchy in Movies dataset looks like in SPSS, in Data View and Variable View.
Data View:
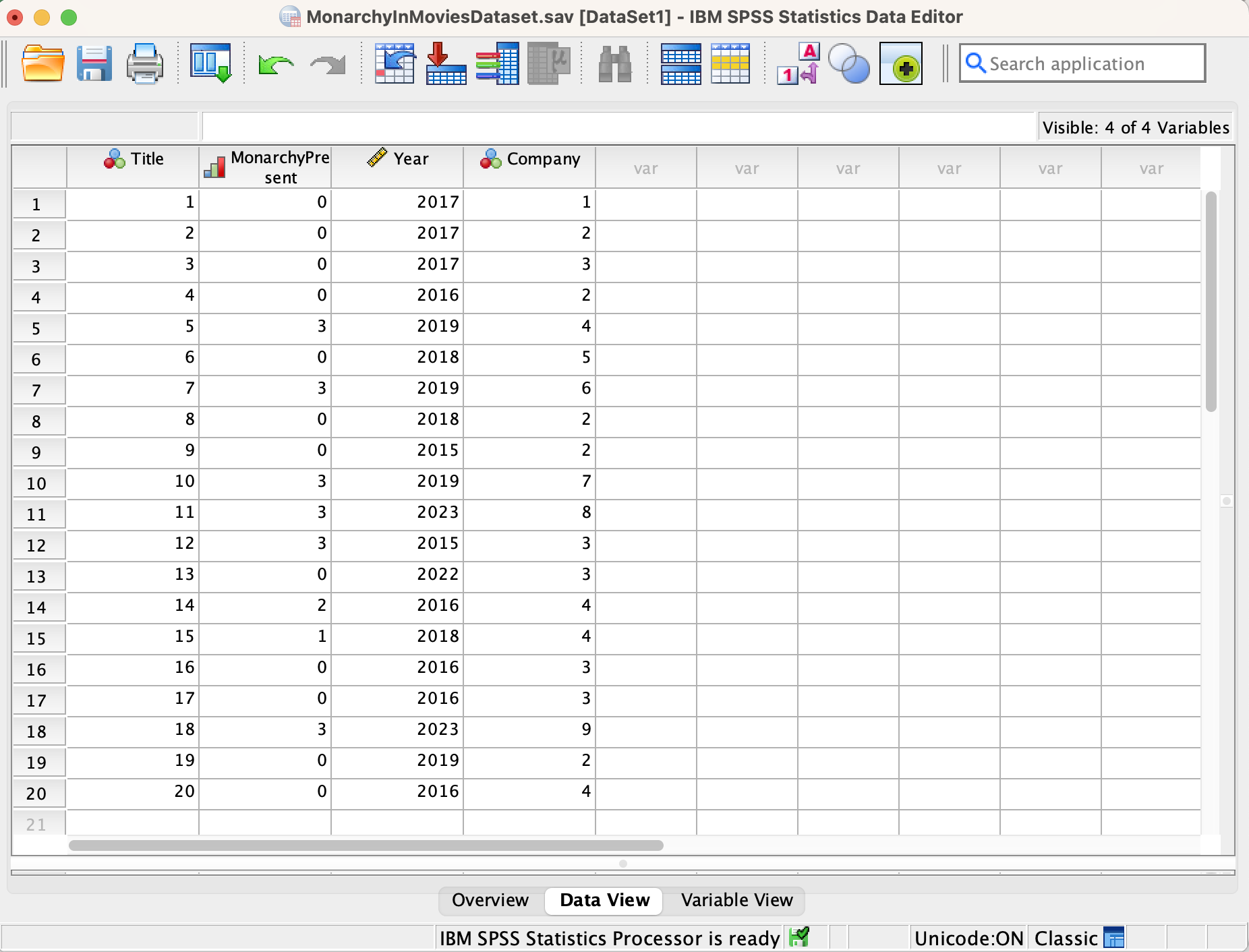
Using my codebook, I know that, for example, when I see a 2 in the Title column, that's Coco.
Variable View:
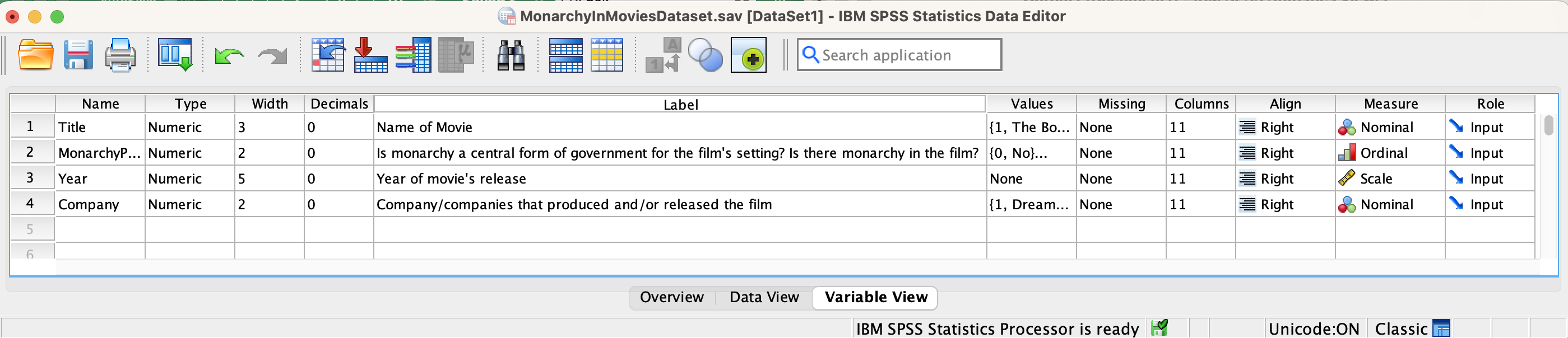
In Variable view, if I go to one of the Values column cells, I can click on a grey box with an ellipsis (three dots) in it. Here is the Values cell for the MonarchyPresent variable:  . Once I clicked on the cell, it looked like this:
. Once I clicked on the cell, it looked like this:  I clicked on the ellipsis, and a window popped up that showed me the coding for the variable:
I clicked on the ellipsis, and a window popped up that showed me the coding for the variable:
When there is no data for a particular case for a particular variable, in SPSS Data View you will see a . instead of a number in that particular cell. Answers can also be coded as "missing" if they are supposed to be excluded from your analysis.
Most of the time when you are told stories about data, you are not going to encounter the actual datasets. You are going to hear a story about aggregate, analyzed data. However, if you want to do your own data analysis, you need a dataset. You are learning social statistics, so you are going to spend a lot of time with datasets. Datasets can come from data you collect yourself (e.g., your own original survey or content analysis), or you can engage in secondary data analysis—when you use existing data someone else already collected, but do your own analysis. There are plenty of public datasets available. Some with great social data include: the General Social Survey, U.S. Census Bureau datasets, the World Values Survey, Pew Research Center datasets, Uniform Crime Reporting Program data, the International Social Survey Programme, and American National Election Studies data. One popular source for finding data sets is the Interuniversity Consortium for Political and Social Research (ICPSR); ICPSR has over 3500 data sets researchers can search through to potentially find one that will address their research question.
E. Frequency Distributions
In social statistics, frequency is synonymous with count. In some disciplines, the term frequency refers only to rates.
A frequency distribution table shows you each category of a variable and the number of cases for each category.
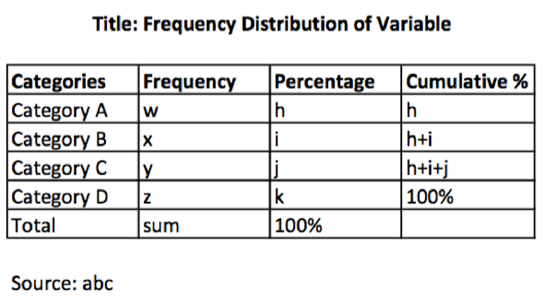
In addition to the count or frequency, frequency distribution tables have percentages and cumulative percentages. Percent means "out of 100." Cumulative is the total amount when you add everything together. So above, the cumulative percentage for Category B would be the total percentage for both Category A and Category B.
When you see frequency tables in publications, they may be formatted differently.
Here is an example from a USC Annenberg Inclusion Initiative report by Stacy L. Smith, Katherine Pieper, and Sam Wheeler with an intersectional analysis of gender and race for directors of the 100 top-grossing domestic fictional films in North America from 2007 to 2022 (fewer films were included in 2020 and 2021 due to pandemic-related performance).
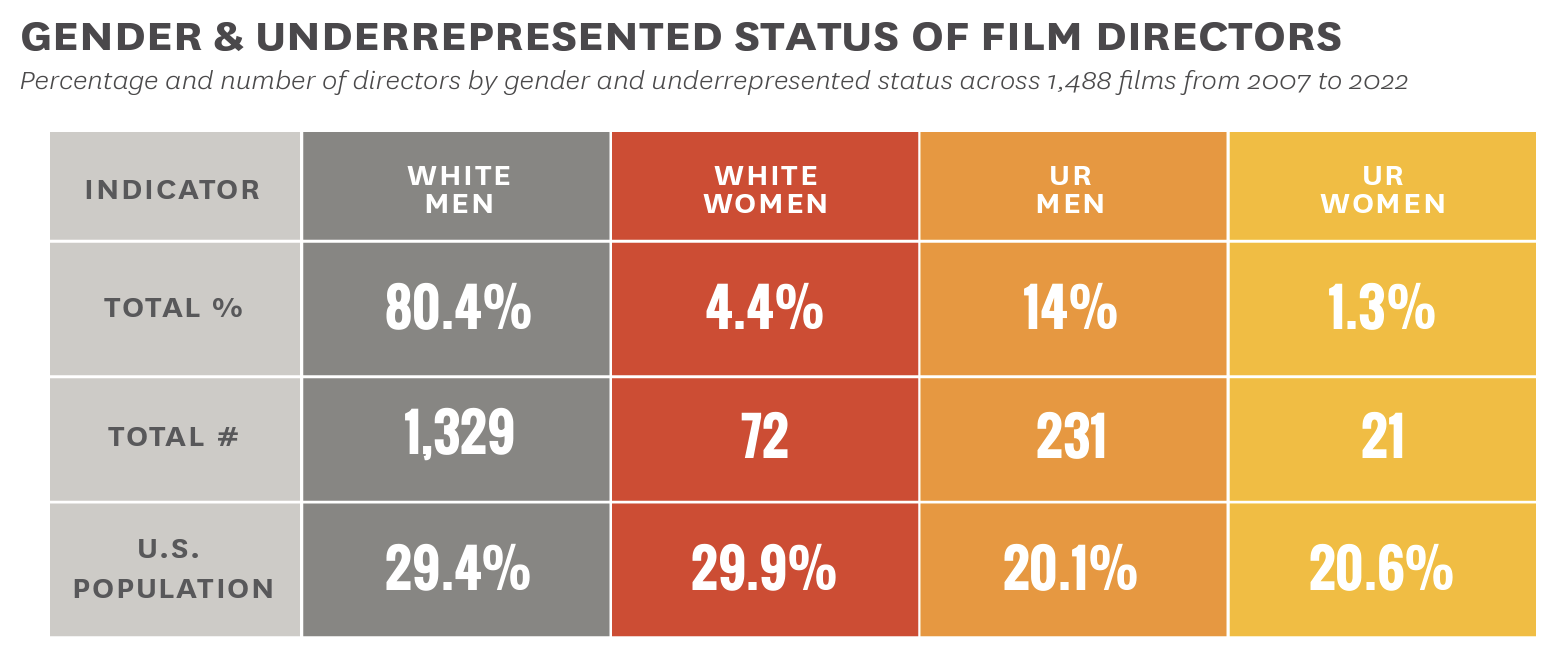
In this table, you can see the total number of directors for each demographic (frequencies), what percentage of directors were from that demographic, and also the percentage of the U.S. population for that demographic, for comparison purposes. This table quickly captures social patterns of the underrepresentation of women and people of color among director positions.
The table is presented in the full report as well, in a less stylized format: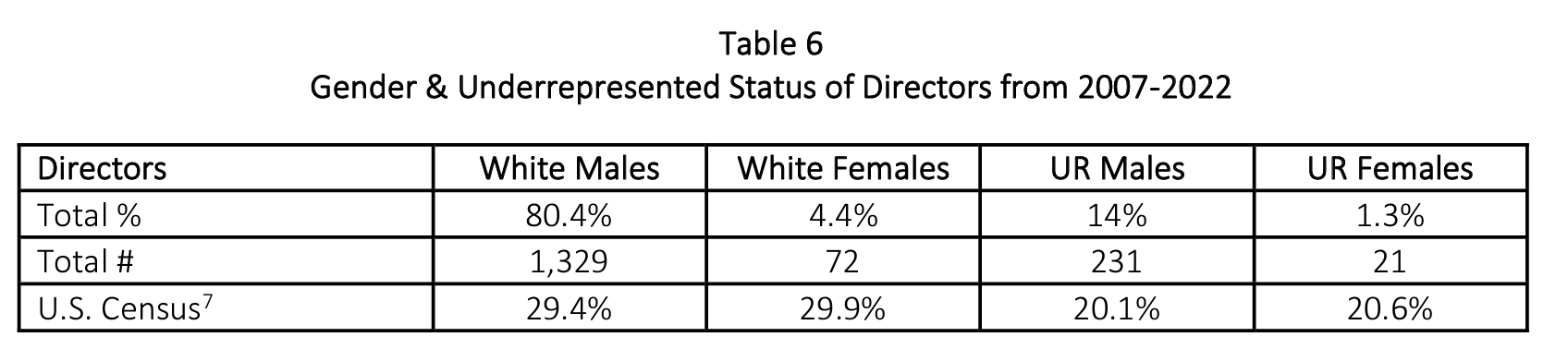
7. U.S. Census (2021). Quick facts. Retrieved December 7, 2022 from https://www.census.gov/quickfacts/fa...e/US/PST045221.
Source: https://assets.uscannenberg.org/docs/aii-inclusion-directors-2023.pdf
When you create a frequency table, you want to select a variable that does not have too many categories. Imagine if the Annenberg Report had included a frequency table with statistics for each of the 1,488 films! That would be a really long table. If you were making a frequency table broken down by age, and have a range of adult ages, you would likely want to collapse the age variable into age groups (e.g., Google Analytics does age reporting based on the groups 18-24, 25-34, 35-44, 45-54, 55-64, and 65+). If you were looking at voting preferences, you might combine any candidates with less than 1% support into an "other" category. If there are too many categories, you should likely either collapse them into fewer grouped categories. There are times you may want a larger frequency table, such as if you are doing a state-by-state comparison and analysis. However, even then such a table is probably more useful to have and provide for reference and less useful for highlighting the main story of your findings.
To make a frequency distribution table in SPSS, you can either use the menus in the SPSS application (i.e., the drag-and-drop / point-and-click method), or you can use syntax, SPSS's programming language. Once you tell SPSS to generate the frequency table, it will open in a new Output window where all your outputs will go.
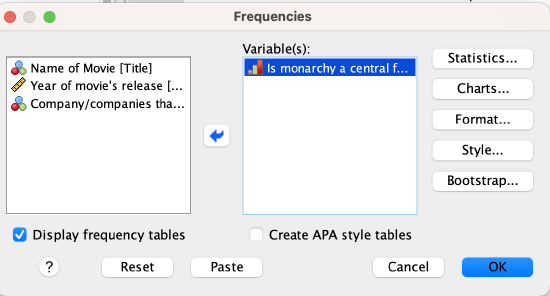
Menu method: In SPSS, go to Analyze → Descriptive Statistics → Frequencies. Make sure there is a check mark next to "Display frequency tables." Select your variable from the left window/box and either drag it to the right window ("Variable(s):") or click the blue arrow to bring it over. Then click OK.
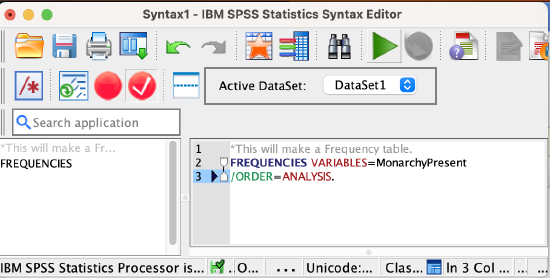
Syntax method: You can open the provided syntax file (see online resources, and go File → Open → Syntax, then select the .sps file ) and edit the variable name. Alternatively, you can create a new syntax file (go File → New → Syntax) and then type in the language below, substituting the actual name of the variable for "VariableName". One nice feature of SPSS syntax language is that variable names are not case-sensitive.
FREQUENCIES VARIABLES=VariableName
/ORDER=ANALYSIS.
Click the green play button to run the command.
Notes to Self: Want to make your own notes right on your syntax file?
*When you precede your writing with an asterisk and end with a period, that portion of your writing will not be interpreted as programming language to run a command and simply as a note for you to have for yourself.

Syntax is a great way to keep track of your work and allow transparency into it as well as being able to check that you did things accurately. Also, if you do something by mistake that messes up your dataset, you can always start again with a clean dataset and just run through your syntax.
Generating syntax logs with your output
While you have a syntax file provided, what happens if you don’t know the syntax, don’t have the file or want to open it, or don’t want to look it up? Or what happens if you use the menus to run a command, but want to keep track of your work?
You can generate syntax with your output, both when using syntax or when using the drop-down menus. The default for SPSS Versions 28 and 29 is for this feature to be off. To turn it on, either:
- Go to Edit → Options → Viewer, and check the box labeled “Display commands in the log,” or
- Run the following syntax: SET PRINTBACK=ON.
If you don't know the syntax for something, you can always click Help → Command Syntax Reference, but the syntax manual it will bring you gives you over 2500 pages to search through! An easier way is to use a syntax file you already have and just copy-and-paste then edit the syntax, or to use the drop-down menus and then copy-and-paste the syntax that generates in the output window.
The exception to this is that if you edit the actual dataset (the Data View or Variable View windows, e.g., adding variable descriptions, coding schemes, deleting a variable, etc.), this will not generate a syntax log.
I am ready to analyze my data and answer my research question!
First, I need to tell SPSS to run a frequency table for the government/monarchy variable.
Menu method:
Syntax method:
Once I run either of these, a frequency table pops up in my output window:
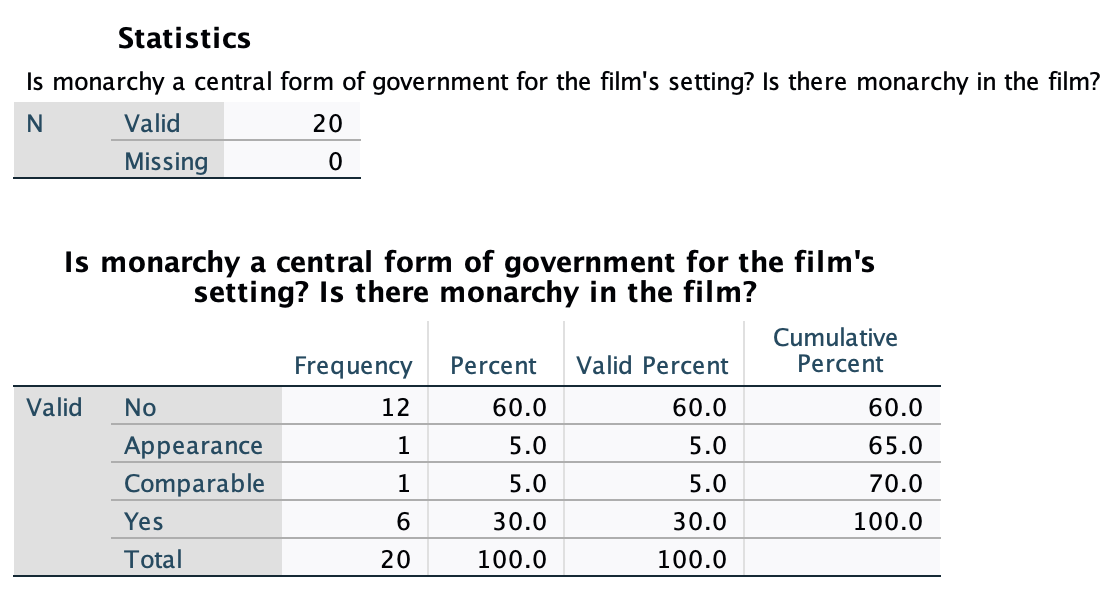
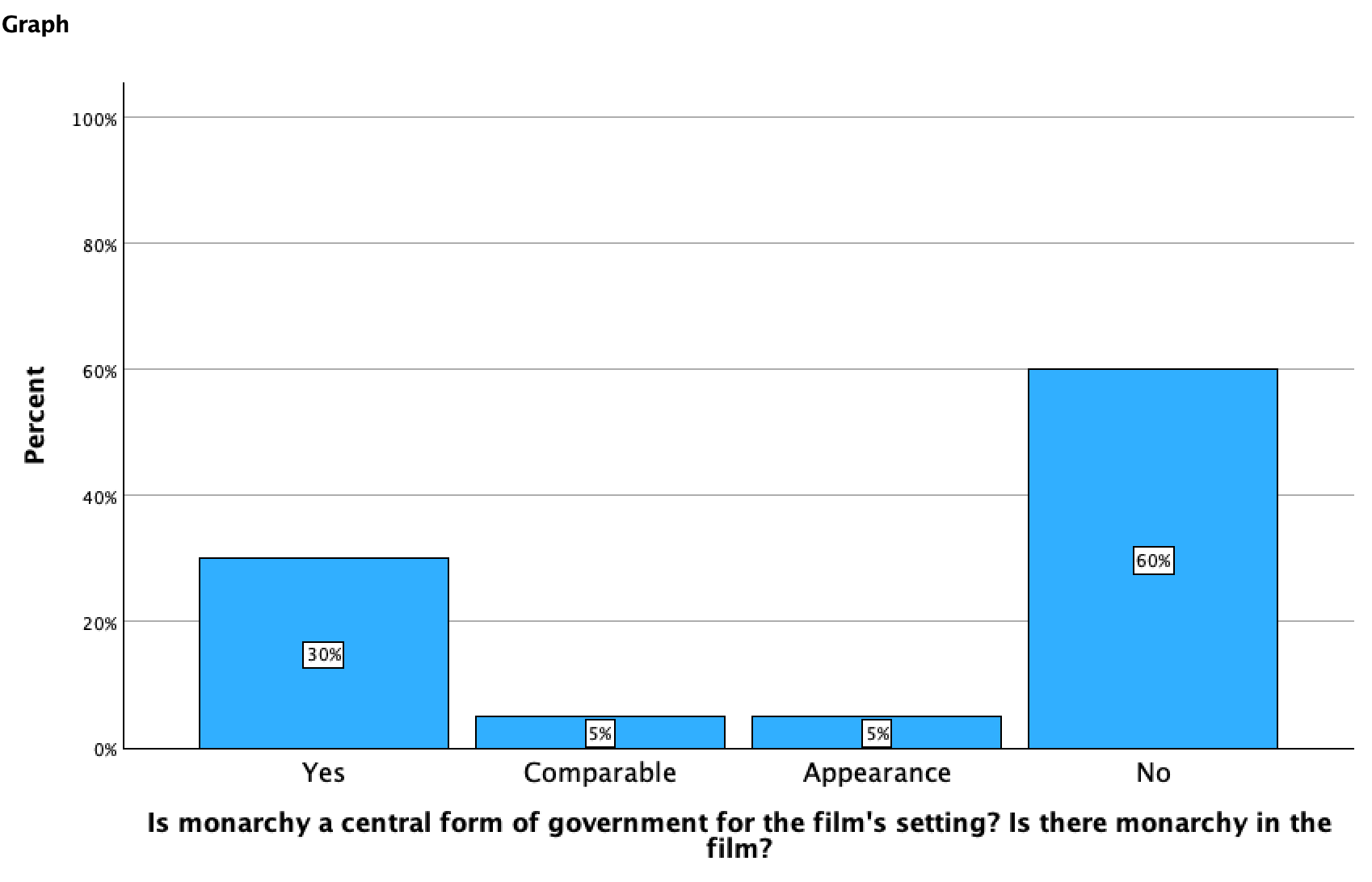
At the top, the Valid N tells me the number of cases in my dataset that had data being analyzed for this variable. The 20 reflects that there were 20 movies where I had an answer about form of government. Below that it indicates there are 0 missing cases, meaning there were not any that were excluded from the analysis.
The frequency table looks similar to the template above, except there is an extra column, "Valid Percent." This is usually the column you want to look at for percent, as it excludes the missing cases. "Percent" is the percent out of all cases, including missing cases. In our case these columns are identical since there were no missing cases. (If you want to delete the "percent" column, you can edit the table by double-clicking on it. Delete the column, close the pop-up window, and your table will update.)
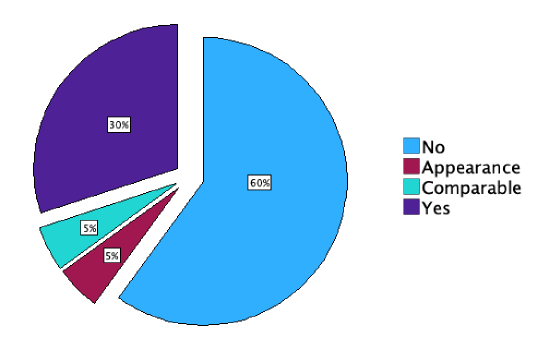
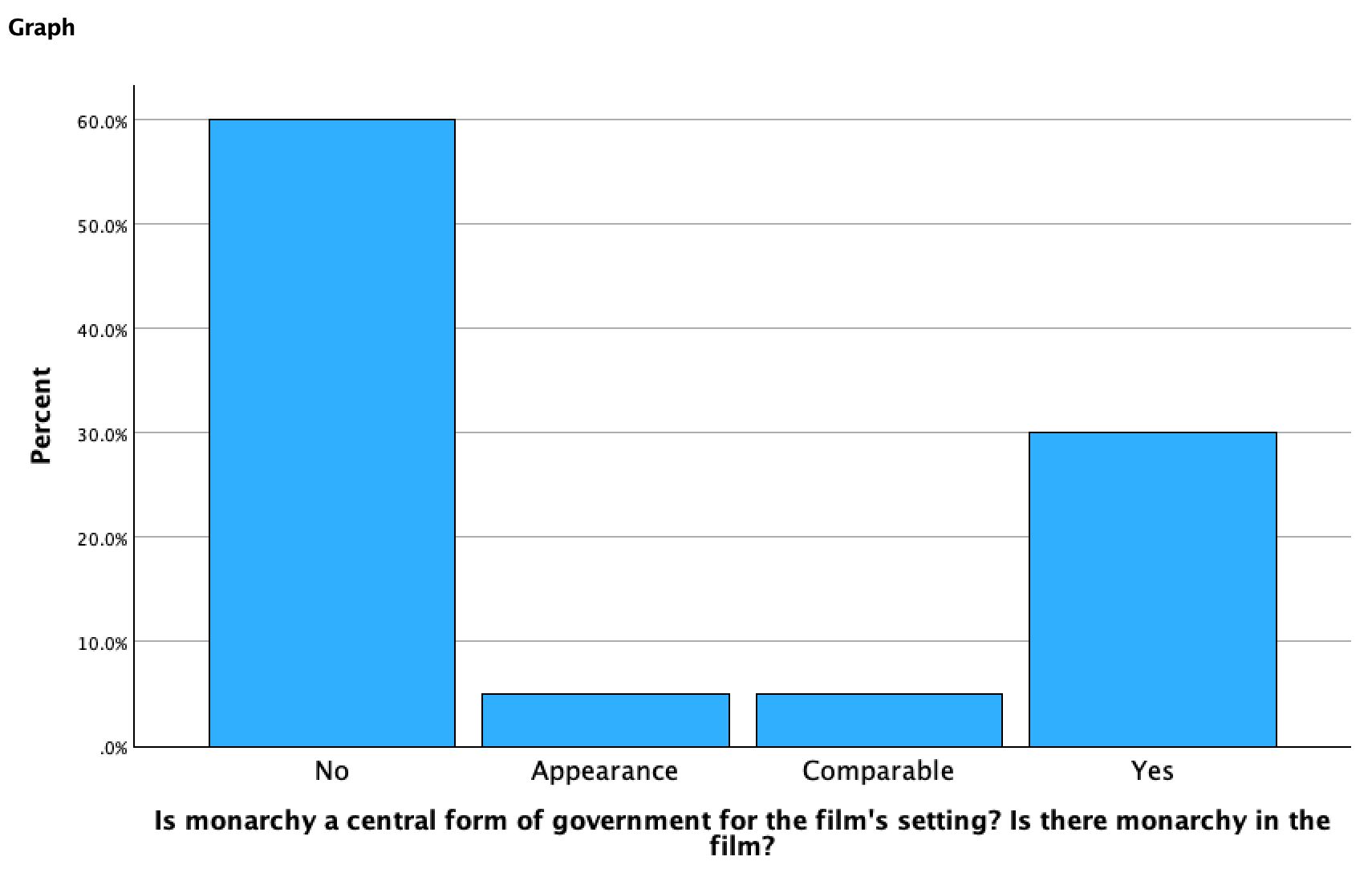
So, 30% of the films had monarchy as a central form of government, and 35% had monarchy or something comparable. That's over 1/3 of the films! Monarchy movies may be money-makers.
If I told you "30% of cases were a yes; 35% were yes or comparable" that would not mean much of anything. Maybe it would to you since you've been following along with me as I conducted this study, but otherwise it would be pretty meaningless. When you interpret statistics, it's important to provide their story in real-life context, so that it makes sense to someone not familiar with your data or dataset, coding, or analysis. In this case, I might say something like, "I looked at 20 of the most popular kids movies from the past 8 years. About 1/3 of them featured monarchies."
F. Pie Charts
Pie charts are useful for showing relationships of parts to the whole (slices of the pie) when you do not have too many categories.
Menu: Graphs → Pie → Summaries for groups of cases; Define. Under "Slices Represent" check the circle for "% of cases." Put your variable into "Define Slices by:". Click OK.
Syntax: Replace "VariableName" with your variable's actual name.
GRAPH
/PIE=PCT BY VariableName.
Let's put the same data we put into a frequency table into a pie chart.
Menu:
Syntax:

Output:

If you double-click on a graph (or table) in the output, it will pop out into a new window and you can make edits to it. Once you're done editing, just exit the pop-up window and the graph in the Output window will update. I decided to add data labels to the pie chart, explode the pieces, and make the legend text bigger.
G. Bar Graphs
Use bar graphs when you have frequencies of categories. If you use a bar graph on a variable with a Strongly Disagree to Strongly Agree scale, each bar will get a label stating what category it is. In Chapter 3 we will look at histograms. Those are a form of bar graph for when you have frequencies for numerical rather than categorical data (e.g., salary, number of pets, etc.).
Menu: Graphs → Bar → Simple; Summaries for groups of cases; Define. Under "Bars Represent" check the circle for "% of cases." Put your variable into "Category Axis:". Click OK.
Syntax: Replace "VariableName" with your variable's actual name.
GRAPH
/BAR(SIMPLE)=PCT BY VariableName.
Let's put the same data we put into a frequency table into a bar graph.
Menu:
Syntax:

Output:
I double-clicked on the graph and made a few edits.
Revised output:
H. Critical Consumption
I wouldn’t write a statistics book if I didn’t think statistics have awesome utility. But with a powerful tool comes responsibility. You should be accurate and transparent when you share your own data analysis. You also have to be a critical consumer of statistics.
I was in a university meeting and we were looking at differences over time for the proportion of the university student population that is non-Hispanic white. It looked like the school had almost 1 in 10 more graduate students of color in 2010 than 2009.
However, data analysis is only as good as one's data. In 2010, there were new race/ethnicity reporting requirements, which included the addition of "unknown" to the university's race/ethnicity data. There were not actually any substantial changes in the racial-ethnic make-up of the university between 2009 and 2010.
My conclusion that about 1/3 of the top 20 kids movies from the past 8 years feature monarchies seems trustworthy. But if you just hear a statistics like that, you do not know if it is accurate unless you know it came from valid data and that the analysis was done correctly. Even then, you need to be careful about generalizations and how the constructs in the claim were operationalized, and how that impacts its meaning.
My analysis gave preference to U.S. rankings. It measured popularity based on revenue. Originally I said I was interested in whether the movies my kid and I were watching really did have as many monarchies as it seemed. To answer a question at that individual level, I could probably go through my viewing history on streaming services and list the movies I've gone to in the theatre. My child and I have watched many more films than the ones that made it to this top 20 list (and there are a few on the list I haven't seen). We've watched other movies featuring monarchies (e.g., Aladdin, Cinderella) and others that do not. The list excludes films that are originals by streaming services. If I expanded or changed my criteria, the distribution of monarchy to non-monarchy movies might look different. Furthermore, how did I classify whether or not a movie featured a monarchy? If a movie is set in Canada or the United Kingdom, should that count? To what extent does the monarchy need to be central to the film for me to classify it as being a movie with a monarchy government. What happens if the film takes place in multiple locations and some are and some are not monarchies? Without clear criteria for how I went about classifying the films, you may not want to trust the dataset I made. Finally, it is very easy to make simple mistakes when recording and entering data, entering codes, etc. A few typos and the results could be very different. There are ways to safeguard against these issues and improve validity, but this is also one reason replication is important.
You should also pay attention to the phrasing and framing of the story I am telling about my data, and what claims I am actually making. It is just as technically accurate for me to say, "Most of the top 20 kids movies do not feature monarchies." That tells a very different story. Even specifying "About 2/3 of the top 20 kids movies from the past 8 years did not include monarchies" focuses your attention on most movies not having monarchies, whereas "about 1/3... did include monarchies" focuses your attention on the fact that a substantial number of the films did.