
7: Learning with Collectives
- Last updated
- Save as PDF
- Page ID
- 81804
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Learning with Collectives
But here is the finger of God, a flash of the will that can, Existent behind all laws, that made them and, lo, they are! And I know not if, save in this, such gift be allowed to man, That out of three sounds he frame, not a fourth sound, but a star. Robert Browning, “Abt Vogler”
So far we have looked at collections of people. Networks, sets, and groups are aggregations of individuals that define the relationships, norms, behaviours, and activities they perform, together and alone. We have seen that, though nets and sets offer many benefits to the learner, the loss of the technological structures of groups combined with the lack of teacher input can place a large onus on the learner to make decisions he or she may not be suitably equipped for, potentially leading to sub-optimal paths and, occasionally, fear and confusion that stands in the way of effective learning. In this chapter we turn to a different kind of entity, composed not of people but an amalgamation of their actions and products. We describe this entity as the collective. The collective can, under the right circumstances, replicate or even improve upon the organizational value of groups, networks, and sets without the overhead of group processes, and take on many of the roles of a teacher. Collectives are thus crucial to realizing the potential of the crowd; they are perhaps more than anything else, what gives modern social software the potential to be a truly radical departure from traditional educational approaches. We are only beginning to realize the benefits of collectives for learning, and there are many pitfalls and obstacles to overcome before they can fulfill their promise, some of which we address in this chapter. Collectives may be teacher-like, but without great care, they can be very bad teachers.
This chapter is organized much like those on groups, nets, and sets, but the emphasis in each section will be somewhat different for two main reasons:
- A collective plays the role of a teacher, not of a collection of learners. We are interested therefore not so much in how to learn in a collective as we are in how a collective can teach, or how we can learn from collectives.
- In cyberspace, a collective is usually a cybernetic technology, composed of both people and software. We will thus pay more attention to technological design principles for collectives in learning.
In terms of learning, the relationship is not between many and one or many and many in the same sense as we find in a group, set, or net, but is instead a oneto-one relationship between an individual and a single entity composed of many parts. Thus, in many ways, a collective plays the role of a teacher in a one-to-one dyad. The potential benefit of collectives as educational tools is great. Done right, they offer the benefit of human judgment as a driver of artificial intelligence. Traditional AI approaches attempt to mimic the thinking behavior of humans or other creatures, whether as a direct analogue (e.g., neural nets) or as an identifiably alien means of giving the appearance of thought. Collectives do neither: done right, they are simply a means of mining and using crowd activities to create wisdom. If we are able to harness such tools to help the learning process, then the wisdom of the crowd could guide us on our learning journeys. Mishandled, they can magnify and enable mob stupidity, and will only guide us in unhelpful directions.
Different Meanings of Collective
The word “collective” may stir up many associations of loss of personal identity. There is something threatening about the loss of individuality associated with the hive mind or fictional Borg collective, of course amplified when human choice to participate is eliminated, as exemplified in the Borg’s assertion, “Resistance is Futile.” Sandberg (2003) explores this concept, drawing unfavorable analogies between hive minds and those of humans, where the benefits of the super-organism are available only to those who have given up their individualism. Turchin and Joslyn in their Cybernetic Manifesto similarly describe metasystems that are created “when a number of systems become integrated so that a new level of control emerges” (1989, para. 5). They show that these higher control systems have developed from the control of movement, through control of individual thinking to the emergence of human culture. Again, we don’t like the coercive connotation of the word control, but we acknowledge that as life has evolved into more complex entities, metasystems are necessary for survival. However, there is no reason that a human collective should subsume its participants. It grows as a result of their activities, in principle taking nothing away from the individuals who form it. We see collective activity in a more tool-like fashion where one exerts individual agency to exploit an affordance provided by collective tools. We realize activities in cyberspace are constantly being extracted and shared at high speeds, and that there is a great risk to becoming enmeshed in a single world view, or caught in an echo chamber as the victim of a filter bubble (Pariser, 2011). But we don’t think this entails more loss of control than what we give to a traffic engineer or a radio station traffic reporter counting the number of vehicles using an intersection at any given moment. Indeed, it is less controlling because the whole Internet is only one URL away, and we do not need to use that intersection to get there. As the Internet ingeniously routes itself around damaged nodes, knowledge of the collective activity and possibility helps us make individual decisions. A collective is an addition, not a subtraction.
Of course, the collective can and often does make mistakes, and we see evidence of groupthink, erroneous or slanderous meme proliferation, filter bubbles that strain out uncomfortable ideas, echo chambers that amplify mundane or even evil ideas, path dependencies, preferential attachment, confirmation biases and more, not to mention illegal or immoral extraction of individual and identifiable activity from collective activities. There are potential dangers in collective creation that need to be dealt with through careful design, and we will discuss these at greater length, but such weaknesses are not strictly features of collectives: misuse and inefficiencies accompany all forms of human organization. One must judge the value of the tool’s use as compared to these costs, and the collectives of which we speak are tools, not mindsets. Even though, as a quotation attributed to Marshall McLuhan (1994) reminds us, “we shape our tools, and thereafter our tools shape us” (p. xi), we need practice and time to develop tool use in ways that allow us to optimize our individual and social selves in a complex universe. Resistance may not be futile, for in the resistance we recreate the technologies to meet our individual and social needs.
Many authors have attempted to grapple with what defines collective intelligence, but in ways that significantly depart from our usage. Malone, Laubacher, and Dellarocas (2009) describe a set of design patterns for different forms of collective intelligence of which the Collective itself, as we define it, is only one. For many, collective intelligence is the result of the combination of coordinated behaviors that represent the ability of a group to solve bigger, more complex problems, or to solve simpler problems more effectively than an individual alone could. Howard Bloom, for example (2000, pp. 42–44), lists five essentials for this kind of successful group intelligence:
- Conformity enforcers—mechanisms to ensure similarity among members
- Diversity generators—mechanisms to ensure some differences
- Inner judges—mechanisms to enable individuals to make their own decisions
- Resource shifters—mechanisms to reward success and punish failure
- Intergroup tournaments—competitions between subgroups.
Howard Bloom’s notion of the collective is both broader than ours, and narrower. Broader, because he sees collective intelligence as a combinatorial effect of many intentionally coordinated individuals, in which technology may play only a supporting role. Narrower, because his concern is with leveraging conventional group processes to achieve a good outcome. A slightly different way of viewing collective intelligence is provided in the field of distributed cognition. This is similarly concerned with a form of collective intelligence that is spread among many, including the artifacts they create: cognition necessarily occurs with others as a result of the shared objects and tools we use, and in the different skills and abilities of people who work and learn together. These definitions are compelling, but differ from our more bounded use of the term as they are concerned with ways we consider collective intelligence to spread among individuals and their artifacts, not as a distinctive agent in itself. We are not just concerned with collective intelligence as a form of distributed cognition, but with distinctive individual entities. This is why we call them “collectives” rather than “collective intelligence.” We are treating the combined behaviors of crowds as identifiable objects that in their own right embody a kind of collective intelligence.
Defining the Collective
Collectives are composite entities made up of the aggregated effects of people’s activities in groups, sets, and networks. In the natural and human world, collectives are commonplace. They are emergent, distinct actors formed from multiple local interactions between individual parts, either directly or mediated through signs, without top-down control. For example, ants leave a trail of pheromones when returning to the nest with food, and they act as a guide to the food for other ants, who leave their own pheromone trails in turn, thus reinforcing the trail and attracting other ants until the food runs out, when the trail evaporates (Bonabeau, Dorigo, & Theraulaz, 1999). The collective is the combination of ants’ interpretations of the signals they leave and those signals, which lead to the self-organizing behaviour of the whole that is distinct from the behaviour of any single individual. Similarly, a crowd gathered in a street acts as a magnet to individuals to join the crowd, which in turn increases the attraction of the crowd. Trading in currency, stocks, or shares reciprocally influences the market for those items, encouraging buying or selling by others, which in turn affects the behaviors of those who initiated the action and those who follow. It is not solely the actions of individuals that affect other individuals, but the emergent patterns left by the multiple interactions of many that engender changes in the behaviour of single individuals. Each individual interacts with a single collective of which he or she is a part.
Collectives can be intentionally created and mediated: for instance, when a teacher asks for a show of hands, or voters vote in an election, individual decisions are aggregated by some central authority and in turn influence the later decisions of those who make up the crowd. This can, for instance, help to swing undecided voters one way or another in an election. In cyberspace, a collective is often this kind of intentionally designed cyber-organism, with a computer or computers collecting and processing the behaviors of many people. Such collectives are formed from the intentional actions of people linked algorithmically by software and made visible through a human-computer interface. It is partially composed of software and machines, partially of the individual behaviors and cognitions of human beings. It is important to distinguish the role of the mediator in such a collective from an independent artificial intelligence. For example, a search engine that returns results solely based on words or groupings of words is not mediating the actions of a crowd: it is simply processing information. However, if that search engine uses explicit or implicit signals from its users or preferences that are implied by links in web pages—such as Google’s PageRank—then it is making use of the aggregated actions of many people to influence those who follow: it is a collective. It can be seen as a substrate for interaction more than a processing machine. While natural phenomena like ant trails and termite mounds are utilizing the physical properties of the world, computers allow us to manipulate the physics of interaction and create new ways of aggregating and processing what people have done, greatly extending the adjacent possibilities.
Groups, sets, and networks are defined by membership, commonalities, and relationships between people who usually share a common interest. Collectives involve no social relationship with other identifiable persons at all, unless social relationships happen to play a part in what is being combined. A collective behaves as a distinct individual agent: we do not interact with its parts but with the whole, to which our own actions may contribute. A collective thus becomes a distinct and active entity within a system, with its own dynamics and behaviors that are not necessarily the same as those actions of the individuals who caused it.
Collectives as Technologies
Most human collectives can be thought of as cyborgs, composed of human parts and a set of processes and methods for combining them that are, whether enacted in people’s heads or mediated via a computer, deeply technological in nature. As much as groups, collectives are defined by the technologies that assemble them. Just as a group is inconceivable without the processes and methods that constitute it, a collective is inconceivable without an algorithm (a set of procedures) enacted to make it emerge. While an algorithm is essential, this does not necessarily imply a technological basis for all collectives: there are plenty of natural collectives, such as flocks of birds, herds of cattle, swarms of bees, and nests of termites that are not assisted by any technology, at least not without stretching the definition of “technology” beyond bounds that we normally recognize. However, when an algorithm is enacted as a piece of software, as is the case in most cyberspace collectives, the collective is part machine, part crowd.
Some Corollaries of the Collective
From our definition of a collective, it follows that
- Someone or something has to perform the grouping of actions that make up the collective. This may be distributed among the collection of individuals, or centralized by an individual or machine.
- The subset of specific actions to observe must be chosen by someone (or some collection of people, or by a machine) from the range of all possible actions.
- What is done with the aggregated or parcellated behaviors has to follow one or more rules and/or principles: an algorithm is used to combine and process them.
- The result has to be presented in a form that influences actions by individuals (who may or may not have contributed to the original actions). Were this not the case, then the collective would have no agency within the system, and there would be little point to creating it in the first place.
We illustrate the collective graphically in figure 7.1. Note that individual components of the collective can be people, machines, or both, at each stage of the process.
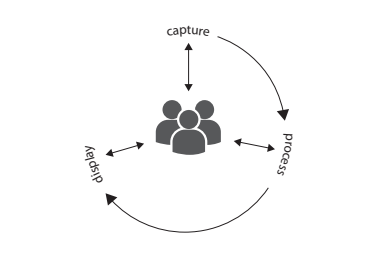
Figure 7.1 A model of how a collective forms.
A collective often involves a feedback loop of mediated and transformed interactions. Behaviors of individuals are
- Captured (by observation or by technological mediators such as computers or vote collectors) Processed and transformed by algorithms (which may be applied by those individuals or by some other agent, human or machine) and
- Fed back or displayed more or less directly to those and potentially other individuals who, in turn, affect their behaviors.
A computer may or may not be involved with any part of that continuum. Significantly, it is possible for all the necessary processing and presentation that drives the system to be facets of individuals’ cognition and behavior, as we see in the formation of crowds on a street. Each individual makes a decision, the aggregate forming a crowd, which itself then acts as a recommendation to join the crowd, thus driving its own growth. The crowd is both a sign and the result of that sign. Equally, even when a collective is mediated, the computation and presentation may be performed by a human agent: a teacher collecting and summing a show of hands in a classroom to allow students to choose between one of two options, for example, is using collective intelligence to affect his or her behaviour. The decision that a teacher makes is not based on dialogue with an individual but with the complete set he or she aggregates, so that the whole class becomes a decision-making agent. Sometimes both human and computer are combined.
People and/or machines may perform the shaping and filtering. This may occur at several points in a continuum:
- During the selection of relevant actions filtering is likely to occur, where the machine (controlled by a programmer) decides which actions to record from which people.
- During processing, where the machine allocates priority or relevance in order to produce rankings and/or reduce the number of results returned.
- During presentation, where the machine filters the items displayed or shapes the form of the display so that some are more prominent than others (e.g., through visual emphasis, list order, or placing at different points in a navigational network or hierarchy).
Because a collective may be seen as an individual agent, then recursively, it is possible to treat one as a part of other collectives. For example, when a collective such as Delicious, CoFIND (Dron, Mitchell, Boyne, et al., 2000) or Knowledge Sea (Farzan & Brusilovsky, 2005) is used to aggregate links pointing to other sites on a single page, that page is treated by Google Search (a collective) very much the same as one that has been created by an individual person. This recursion can reach considerable depth.
Stigmergic Collectives
The term “stigmergy,” from the Greek words for sign and action, was coined by the biologist Pierre-Paul Grassé to describe the nest-building behavior of termites and other natural systems where indirect or direct signs left in the environment influence the behavior of those who follow, leading to self-organized behavior.
Many collective systems are stigmergic, and in nature they afford many advantages. Stigmergy fosters actions and ideas that collectively allow the performance of “problem-solving activity that exceeds the knowledge and the computational scope of each individual member’’ (Clark, 1997, p. 234). Stigmergy can be seen in many systems, from money markets (where money is the signal), to nest-tidying in ants (where untidiness is the signal). It is rife in cyberspace, influencing search results returned by Google, for example (Gregorio, 2003), and is the foundation of educational systems that employ social navigation (e.g. Dron, 2003; Dron, Boyne, & Mitchell, 2001; Farzan & Brusilovsky, 2005; Kurhila, Miettinen, Nokelainen, & Tirri, 2002; Riedl & Amant, 2003), allowing users to become aware of the actions, interests, categorizations, and ratings of others.
Many systems that collect and display user-generated content have some stigmergic characteristics whereby individuals are influenced by the collected behaviors of the whole. For instance, users are influenced by the ratings or number and depth of postings to a forum, or by the number of viewings of changes on a social site’s front page. In each case, the system provides an interface that shows some aspect of crowd behaviour, which in turn affects the future behaviour of individuals making up the crowd.
Non-Stigmergic Collectives
While very common in collective applications, stigmergy is not a defining characteristic of a collective, or at least, not in a direct and straightforward manner. There is a variation on the theme that is as useful and in some ways superior to the self-organizing, dynamic form in which the choices and decisions of a crowd are mined, applying similar principles to other collectives to identify some decision, trend, or calculation. Such systems are almost all based around the use of sets, because those in groups and nets are usually far more aware of one another’s actions and are influenced by them. Classic examples of the genre are recommender systems and collaborative filters that make use of independently mined actions or preferences to identify future interests or needs. This is positive because as Surowiecki (2004) pointed out, crowds are only wise when they are unaware of what the rest of the crowd is doing. By definition, stigmergic systems break this rule, at least on the face of it. There is compelling evidence that Surowiecki’s assertion is true. The disastrous out-of-control stigmergic effects that fuel bank runs, where the people withdrawing money serves as a sign for others to follow suit, shows all too clearly the potential downside of people being aware of others’ actions. Similarly, Salganik, Dobbs, and Watts, (2006) show that when people can see the choices others have made for rating songs in a chart, it profoundly alters the overall charts: social influence in their study made for unrecognizably dissimilar chart results when compared to independent choices, and when compared to individual choices, the rankings are less satisfying for all concerned. This is not an entirely simple equation, however.
Author Dron performed a study to explore the influence of others’ choices on behaviour that showed a mix of behaviors from copying to rational decision-making, and on to deliberate obtuseness in selecting items that were as different from the items selected by others as possible (2005a). At the time, such effects seemed surprising: the expected behaviour was that people would generally make worse choices by copying those who came before, not deliberately avoid such behaviour. These results are, however, borne out by other research. Ariely (2009), for example, discovered that the beer-ordering behaviors of individuals in a group, as opposed to independent individuals, was significantly different. In this experiment, participants showed a tendency to deliberately order differently from their peers, even though their preference without such influence might have been for a beer that had already been ordered. While the influence of earlier people can skew results of collective decisions so that they are, at best, only as good as the first contributor, aggregated independent choices are far more successful at eliciting crowd wisdom.
We have a tendency to be influenced by decisions that came before, whether positively (we follow them) or negatively (we deliberately do not follow them). This is clearly evidenced on social sites such as Twitter, where what is “trending” or most popular is promoted, leading to sometimes vast waves of viral interest. However, as we have already observed, this can be problematic. There are some simple solutions, however, which do not limit crowd wisdom but still bring the benefits of adaptation and dynamic change that a feedback loop engenders. The most effective of these is the simplest: to introduce delay to the feedback loop (Bateson, 1972). If a crowd does not know what the rest of the crowd is thinking, then it is far easier for it to be wise. This is evident when poll results are displayed as an incentive to vote, but only after one’s preferences are entered. Flickr uses this to good advantage when supplying tag clouds for the previous day, the previous week, and overall: recent tag clouds are seldom valuable, though they can occasionally show the zeitgeist of the crowd. But as delay creeps in, they provide more relevant and potentially useful classifications.
While many collectives are not directly stigmergic, stigmergy may nonetheless re-enter the picture when results are returned to individuals. Google, for example, mines independent implicit evaluations of websites, but because it plays such a prominent role in helping people find pages of interest, it is more likely that pages appearing at the top of search results will be linked to, therefore reinforcing the position of those that are already successful in a stigmergic manner.
Cooperative Freedoms in Collective Learning
While the collective is not in itself a social form, and so is not directly comparable to individual, group, net, and set modes of learning (it relies upon those social forms in order to exist at all), there are some distinct benefits that emerge from its effective use. Most notably, although it will often inherit the limitations of its parent social form(s), it can be a gap-filler, adding freedoms that might have been unavailable in the other social forms. We do not present our customary diagram of cooperative freedoms for the collective, because it depends entirely upon the kind involved, but we describe some of the ways that collectives contribute to, or in rare cases, detract from cooperative freedoms.
Time
Collectives tend to inherit the limitations of the social forms they arise in. For instance, those that emerge in immersive and other synchronous contexts tend to appear in real-time, though timeline-based tools can add extra richness to such experiences and, if they are recorded, can add layers to the original interactions, for instance by showing patterns that may have occurred within the original interactions of earlier participants. Donath, Karahalios, and Viegas (1999), for example, used this to good effect in the stigmergic ChatCircles system, which was otherwise constrained to real-time dynamics. Similarly, when they emerge out of discussion tools, they can distil or mine patterns from them. For example, one of the earliest collaborative filters used for learning, PHOAKS (People Helping One Another Know Stuff), provided its recommendations by mining discussion forums for links to resources, and used those as implicit recommendations to others (Terveen, Hill, Amento, McDonald, & Creter, 1997), thus allowing freedom of time to engage with the system separately from the actual discussion that generated them.
Place
As with all networked tools, collectives provide few limitations on the location learning can occur in, except where they emerge in real time from collocated crowds.
Content
Freedom of content depends a great deal on the form that the collective takes. Many are used as recommenders of people or content, suggesting an assortment of alternatives that narrow down the choices that can be made. The effect of this can be very large and is always significant: the chances of a user clicking one of the first two items presented by Google Search, for example, are many times higher than they are for him or her clicking the last item on the page, even when results are deliberately manipulated to show the “worst” options first (Joachims, Granka, Pan, Hembrooke, & Gay, 2005). Interestingly, however, the chances of the user clicking on middle-ranked resources are even lower than they are for clicking the last item on a page. When we trust the collective, belief in its accuracy frequently overrides even our own judgments of quality (Pan et al., 2007). In some cases, such as when a user clicks “I’m feeling lucky” in a Google search, there may be no choice presented at all. Of course, we must remember that the user is always free to search somewhere else or for something different. We are aware of no collectives as yet that are used coercively; their role is always one of persuasion.
Delegation
The ability to delegate control to a collective is dependent on context. In many ways, accepting a recommendation or allowing a collective to shape an information environment is to intentionally delegate control to someone or something else. However, the typical context of collective use in current systems is that of the self-guided learner who has made an active decision to use the collective. Thus far, there have been few attempts made to use collectives to shape an entire learning journey, and those who have tried have not succeeded.
Relationship
Apart from the use of collectives to recommend people or shape dialogue use, collectives have very little effect on freedom of relationship. However, because a collective is an active agent akin to a human in terms of its behavior, it is often possible to engage more or less fully with the collective itself. Typically, one gives information to the collective in order for it to provide better information or advice. For example, the more information it has about you, the more Google will give you personalized and accurate results if you are logged in as a Google user, (i.e., it is more likely to give the results you are looking for). Similarly, many collaborative filters use explicit ratings and/or preferences (e.g., MovieLens or Netflix for movies, Amazon for books) to improve the accuracy of their predictions of what you may like.
Medium
As a rule, collectives are neutral to medium: they may or may not place constraints on the media used and, as we have already observed, they are usually used in a context where the learner has control over whether and which collectives are used for learning.
Technology
Many collective systems work equally well across various technology platforms. Again, however, the details depend on the precise context of use: a system that uses one’s location, for instance, is constrained to uses where the technology can provide that information.
Method
Once again, the context determines whether collectives provide a choice of method. Because they are mainly used by independent learners, the choice of method is more dependent on the learner than on the tool. Collectives on the whole act like controllable teachers, allowing the learner to choose what method suits him or her best. Very few existing collectives apply any intentional pedagogy, and this is an area that demands greater research.
Pace
There are few occasions where pace makes a difference when using a collective for learning, though there are sometimes constraints due to the time it may take for a collective to gain a sufficiently rich knowledge of both individuals and crowds to provide useful help. The vast majority of collective systems suffer from a cold-start problem: they only offer value when sufficient numbers of actions have been captured, so until then, there is no reason to use them, which creates difficulties for them to gain sufficient numbers to begin with. Most systems deal with this by making use of previously shared information (e.g., Google mines links from websites, PHOAKS mines posts in Usenet News, Facebook uses EdgeRank, and Delicious uses browser bookmarks), information from other domains (e.g., Amazon book “likes” may be used to identify similar people in order to recommend movies), or by using automated guesses based on content similarity or approximations from statistical data to provide reasonable recommendations earlier in the system’s development when there is insufficient crowd data.
Disclosure
For any collective to work at all, some disclosure of actions is required. However, in most mediated collectives, this is essentially anonymous. Though we may fear the motives of companies that provide collectives, this is a fear of disclosure to an organization, not to the collective itself. Where software is performing aggregation, it knows who you are but other people in the collective rarely, if ever, do. There are some exceptions, especially when collectives are concerned with establishing reputation. In such cases, there is a double concern: first, that one must disclose information about oneself to the software and, in principle, its owners in order to participate; and second, that it involves the delegation of one’s reputation to the crowd. In such cases, fear of exposure may be justified.
Transactional Distance in Collectives
The collective, as an emergent entity composed of a collection of people in sets, nets, and occasionally groups, plays the role of a teacher in a learning transaction, guiding, suggesting, collecting, clustering, and re-presenting the knowledge of the crowd. A learner interacting with a collective is engaged with something dynamic and responsive in a way that is quite different from engagement with a static book, website, or video, yet without the social engagement he or she experiences when interacting with an individual human being. At least for the foreseeable future, there will be little or no psychological connection between a human and a collective, or if there is, it will be one-way: collectives do not care about individual people. From the point of view of the individual, interacting with the collective is seldom more psychologically engaging than interacting with any artificial intelligence. This is not to suggest that the interaction is not powerful for the individual concerned, and one can claim that two-way communication has meaningfully occurred, just as with Furbies, Tamagotchis, or more recent AIBOs and Paros (robot baby seals intended to provide companionship for the elderly— www.parorobots.com; Turkle, 2011).
The two-way dialogue with a collective can occur in many ways. One of the motivations behind Kay & Kummerfeld’s (2006) scrutable user models is to allow people to talk back to the collective, which otherwise can make decisions on the behalf of users that are not helpful. Many people have deliberately watched content that they would not otherwise choose on collaborative filter-based TiVo devices, for example, to stop the machine from making wrong or embarrassing predictions about what they would like to see (Zaslow, 2002). A very distinctive feature of collectives is that the individuals who interact with them are also typically a part of them, active contributors to the collective intelligence. This is distinct from our engagement with people in social forms: we may be part of a net, set, or group, but the individuals within them are still distinct, and at least in principle, identifiable. The collective is an active individual agent of which we are a part. All of these complexities make transactional distance between learner and collective a very unusual but quite distinctive phenomenon. The collective creates high structure, shaping the information space that the learner inhabits, but the learner is part of the collective, and in many cases can control the results, whether through direct intervention (e.g., in Netflix, specifying the kinds of movie he or she would like to see), behavior modification intended to affect results, or simply by choosing from one of multiple options.
Examples of Collectives
Rating Systems
The majority of systems that provide a means to implicitly or explicitly rate someone or something make use of collectives. These vary in sophistication from simple aggregators to full-blown collaborative filters, where ratings are used to compare an individual with the crowd, and on to rich metadata that provide ratings across a range of dimensions.
A few examples include Slashdot Karma Points and categories, Facebook Likes, Google+ Plus-ones, and countless systems that provide Lickert scale-style ratings such as Amazon and YouTube.
Collaborative Filters
Collaborative filters are recommenders that make use of similarities between people (e.g., people who share a similar pattern of interest for things like books or movies) or similarities between crowds of people implicitly or explicitly liking particular items (e.g., people who bought this also bought that). Some examples are Amazon Recommends, Netflix, and MovieLens.
Data Mining and Analytics Tools
A number of collective applications mine existing content in order to identify patterns, preferences, and structures that might otherwise be invisible. For instance, Cite-U-Like and Google Scholar provide recommendations based on citations to scholarly papers, Google Search ranks results according to the number of links mined from web pages, and PHOAKS looks at links in newsgroup postings to identify implicitly recommended articles.
Swarm-based Systems
Swarm-based systems mimic the behaviours of groups of ants, birds, fish, and other naturally occurring crowds in order to bring about self-organization in a crowd based system. These are most often used to control work of very simple robots to collectively complete a complex job. Tattershall and his colleagues have used this process to provide sequencing recommendations for learners (2004; van den Berg et al., 2005). Though it can work reasonably well with a closed corpus such as a conventional course where there are limited potential paths and defined goals, this kind of approach falls flat in the large open corpuses of set and net interactions. Particle swarm optimization systems take a slightly different approach, and are typically used in goal-oriented systems to optimize multiple behaviors towards a single solution. They are sometimes used with Genetic algorithms (GAs) to rule out inappropriate resources to filter results (Huang, Huang, & Cheng, 2008).
Ant Colony Optimization Systems
Systems using ant colony optimization techniques make use of virtual pheromones to capture paths and actions taken by the crowd in order to adapt content, presentation, process, sequence, and other elements of a user’s experience. Some examples are AACS (Yang & Wu, 2009) and Paraschool (Semet, Lutton, & Collet, 2003).
Social Navigation Systems
Systems that employ social navigation capture browsing behaviors and actions such as tagging or commenting in order to modify an interface to emphasize or (sometimes) determine certain paths at the expense of others. For example, CoFIND used rank order, font style, and font size to indicate resources that are viewed as useful by the crowd (Dron et al., 2001). Educo used representations of individuals as clustered dots surrounding resources that were more widely used (Kurhila et al., 2002), Knowledge Sea 2 used color depth to indicate more visited resources (Farzan & Brusilovsky, 2005), and CoRead used different highlight colors to indicate passages of texts that have been more or less highlighted (Chiarella, 2009).
Social Network Discovery Engines
The vast majority of social networking sites use some means of discovering others with whom to connect. The algorithms may be quite simple, such as link analysis to discover friends of friends. Indeed, the commonly used FOAF protocol was explicitly built to exploit this. Others may simply identify other people in groups an individual belongs to, but some can be more complex, taking into consideration profile fields, browsing behaviors, and the content of posts. A sophisticated example is Facebook’s EdgeRank, which takes a range of factors (a trade secret) including not just connections but numbers and frequency of interactions into account when presenting content, as well as numerous set-oriented factors (Pariser, 2011). In a learning context, we have provided an Elgg plugin that assists discovery of both friends of friends and people in shared groups (community.elgg. org/plugins/869921/1.2/suggested-friends-18x).
Crowdsourcing Tools
Crowdsourcing systems typically rely on user-generated content in response to a particular problem, question, or project request. While some rely on the person posing the problem to sort through potential solutions, such set-oriented applications are very often enhanced with collective tools that solicit implicit or explicit ratings from the crowd in order to rank the effectiveness of the solution: these include Yahoo Answers, Quora, Amazon Mechanical Turk, and Innocentive.
Tools to Assess Reputation
A number of systems mine data such as citations and references in order to discover experts rather than content; for example, Cite-U-Like and Connotea. There is abundant literature on refinements to these approaches (Ru, Guo, & Xu, 2008; Smirnova & Balog, 2011). Social networking systems such as LinkedIn make use of networked endorsements to provide a collective indication of reputation within a field while others, such as academia.edu, make use of citations and papers to help emphasize reputation within a field.
In many network-oriented systems, the connections explicitly made between one individual and another by “friending,” providing links in a blogroll, commenting or linking within blog posts and so on, provide the necessary recommendations for us to trust others. If someone I admire admires someone else, that acts as an effective indicator of reputation. It is an old technique that can be quantified and turned into a collective with relative ease: weighted citation indexes use the same kind of approach to indicate the significance of an academic paper.
Going beyond those we know in a large network, reputation (apart from for a few of the most well-known people within the network) can be harder to identify, and collectives rapidly become the most important tool for identifying value. Systems such as Slashdot, Spongefish, or Graspr can be remarkably effective self-organizing learning resources because of the methods they use to identify reliable/useful contributors and resources. Slashdot and Graspr (now defunct) both make use of a karma-based system, whereby “good karma” is gained through a variety of crowd-driven mechanisms.
Spongefish (a how-to site that folded in 2008) took a simpler but more comprehensible approach where coins denoted social capital for a teacher. In each system, there is an economy: those who already have points/coins are able to distribute them to others, thus ensuring that reputation is decided by those who already have a reputation, an approach that ensures at least some assurance of quality. However, the failure of so many systems points to the difficulty of getting algorithms right and designing interfaces that do not overwhelm their users with complexity. Slashdot (with its tagline, “News for Nerds”), one of the earliest, and still the best of collectives, survives largely due to its target user base that not only tolerates but also revels in its complexity.
Within an educational setting, such systems can offer several affordances. For example:
- Learners can be encouraged to gain reputation and submit that as part of a formal assessment. Used with care, and bearing in mind the risks of subverting such a system, this can offer motivation in the right places.
- Learners can use such systems to identify resources and people of value, thus filtering out those who may be distracting or misleading.
- Learners can be encouraged to rate/rank/pass on points or coins to others, encouraging critical and reflective thinking and encouraging them to engage more deeply with the community.
Learning with Collectives
In previous chapters about groups, nets, and sets, we have labeled this section “Learning in x.” In this chapter we deliberately describe this as learning with collectives, as the collective is an active and influential participant in a learning process, far more akin to a teacher or content than it is to a collection of people. At once human and mechanical, the collective is an alien kind of teacher engaged in a dialogue with its parts.
There are many roles teachers must play in a traditional educational system. Here is a short list of some of the main ones:
- Model thinking and practice
- Provide feedback
- Design and assemble learning paths
- Schedule learning
- Convey information
- Clarify and explain complex topics
- Assess learning
- Select and filter resources and tools for learning
- Care for students and student learning
- Provide a safe environment for learning
The majority of these roles, if not all, can be played by a collective to some extent. It should be noted, however, that enthusiasm, caring, passion, and many of the most valuable personal attributes of a teacher will not be present, though they can be mimicked by a collective. The collective plays the functional roles a teacher might perform.
Modelling Thinking and Practice
Little will substitute for observing a real teacher modelling good practice and demonstrating how he or she thinks about an issue, but of course collectives occur within social communities where such things are already possible. However, some kinds of collective can be used to promote and aggregate such behaviors. Karma Points and ratings, for example, can combine to show the informed user not just relevant content, but also the cream of the crop—not just a single teacher, but the “best” of those who contribute to a discussion or a debate. The collective is, by the judgment of the crowd contextualized to the needs of the viewer, an “ideal” composite teacher.
Providing Feedback
Even a simple rating system of “thumbs-up” or page view counters can tell a learner his or her work is valued. However, this is not particularly rich feedback, serving a motivational purpose more than offering guidance. Moreover, in some cases this can be demotivating, if it is viewed by the learner as an extrinsic reward (Kohn, 1999). Such guidance is still more a function of the social modes of engagement, group, set, or net, than of the collective. Having said that, a range of collective systems have been developed that provide somewhat richer feedback, including the nuanced rating system of Slashdot, and the more freeform “qualities” used in CoFIND (Dron, Mitchell, Siviter, & Boyne, 2000). These systems allow ratings across multiple dimensions that, at least in the case of CoFIND, can be pedagogically useful. People may, for instance, choose to rate something as “complex,” “complete,” or “well-written,” thus giving valuable feedback that in some ways betters that of an individual teacher, if sufficient ratings are received. Such systems also show rater variability, which itself can be more instructive than the stated preference of a single teacher (even a wise one).
Designing and Assembling Learning Paths
A number of social navigation-based systems provide weighted lists of recommendations of what to do next (Brusilovsky, 2004; Dron, Mitchell, Siviter, & Boyne, 2000; Kurhila et al., 2002; Wexelblat & Maes, 1999). Others have used techniques such as ant-trail optimization, swarming, and other nature-inspired techniques to offer recommendations (Wong & Looi, 2010; Semet et al., 2003). Many recommender systems that use various forms of collaborative filtering similarly present alternatives of what to look at next, based on previous behaviours of other learners (Drachsler, Hummel, & Koper, 2007; Freyne & Smyth, 2006; Hummel et al., 2007). However, it has proved difficult to do more than present suggestions for the next step in the path. Generating a plan of activities for a learner to follow poses significantly greater challenges, though many have tried (Pushpa, 2012; van den Berg et al., 2005; Yang & Wu, 2009). There are several reasons why they have not yet been wholly successful: learning is a process of change in which it is hard to predict in advance how a learner will develop as a result of each step.
When teachers design courses well, they do so based on their experience and conceptions of the topic as well as pedagogical considerations and knowledge of learners, resulting in an assembly that is intricately connected and cohesive, involving deep content knowledge, and importantly, an understanding of how to tell a story about it. Many adaptive systems have attempted to do the same and can work fairly well for individuals or group-based learners, but few (if any) have succeeded when dealing with an open corpus of knowledge, which is commonplace in net-based and set-based learning situations.
Some have used ontologies for connecting sequences of resources that are collectively generated (Karampiperis & Sampson, 2004). Though computationally elegant, this has been a profound failure from a learning perspective. The main reason is because pedagogically appropriate paths are not the same as expert opinions of the relationship between one topic and another. Even assuming a sufficient body of material can be effectively marked up and put in relation to others, subject discipline relationships seldom translate into good learning paths.
A promising approach is to combine recommendation methods with expert-generated curricula (Herder & Kärger, 2008) and these are relatively easy to generate in a constrained set of well-annotated resources within a group-oriented institution (Kilfoil, Xing, & Ghorbani, 2005; van den Berg et al., 2005).
Scheduling Learning
Closely related to the design of curriculum and learning paths is the means to synchronize activities and pacing. This has long been an important role for a teacher, often played by an institution in group-based learning, and is a common characteristic of group-based approaches, but it is usually difficult to achieve in network and set learning. However, collectives can take on some of that role. The simplest tools for this task allow an individual to specify a list of possible dates and others to indicate their availability. The tool aggregates potential times, and automatically or semi-automatically, suggests the most appropriate time when as many learners as possible are available. Plentiful free tools of this nature such as MeetingWizard, Doodle, Congregar, Setster, and Tungle are available on the Web and, in some cases, for cellphones.
Conveying Information
On the whole, collectives are not used to convey information from the ground up, but to collect, filter, refine, order, and display information that already exists. They provide ways to organize information rather than generating it in the first place. This organizational process can be quite powerful, however. Slashdot, for instance, is able to tailor content to specific needs, and allows relevant and reliable posts to provide nuanced insight into the topic under discussion that greatly surpasses what any individual teacher might be able to say on the subject, simply due to diversity and breadth of coverage. Other systems can help to visualize a complex subject area or social connections that might otherwise remain hidden (Buckingham-Shum, Motta, & Domingue, 1999; Donath et al., 1999; Vassileva, 2008).
Perhaps one of the most important sources of learning content today and a notable exception to the norm is Wikipedia. Wikipedia arguably uses stigmergic and similar collective processes, largely enacted in the minds of its contributors, underpinning and affecting ways that pages grow (Elliot, 2006; Heylighen, 2007; Yu, 2009). Basically, people are affected by signs left by other people in the environment but, for the most part, this is simply an anonymous mediated dialogue, a set-based interaction where each edit builds on the last, but without the distinctive self-organizing character of a true stigmergic system. However, there are a few genuinely stigmergic elements. Changes made by others affect not just content but also style, in ways that are analogous to stigmergic processes in nest-building ants or termites. Similarly, the use of wiki tags—metadata that relate to the content of pages—leads to predictable patterns of editing: the tags act like pheromones that guide others in their editing (den Besten, Gaio, Rossi, & Dalle, 2010).
Wikipedia also provides some embedded intentionally designed collective tools, such as pages showing trending articles that are truly stigmergic: frequency of use and editing affects the behaviour of others that follow. While it does include some collective elements, it is important to observe that Wikipedia is more of a farm than a self-organized jungle, and its power lies in its organizational and automated tools for assuring quality, not in collective processes. The collective aspects of the system simply help to shape its development rather than playing a major role in content production.
While difficult to generalize beyond specific contexts, there have been some interesting collective approaches to the creation of artwork, many of which have persisted and grown for ten years or more: www.absurd.org, www.potatoland. org, or snarg.net, for example. More recent systems like PicBreeder (PicBreeder. org), Darwinian Poetry (www.codeasart.com/poetry/darwin.html), and a wide variety of music evolution systems (Romero & Machado, 2008) use the crowd to choose between mutated forms of artworks, thus acting as an evolutionary selection mechanism. As a means of reflection on what creates value, this may be useful in an educational context. The potential for actually providing educational resources beyond such specific domains, however, seems limited.
Clarifying and Explaining Complex Topics
Collectives can be used to extract meaning and sense from a complex set of materials. For example, CoRead is a tool that allows collective highlighting of texts, in a manner similar to that employed on Amazon Kindle devices (Chiarella, 2009). Learners can see other learners’ highlights, and a simple color scheme is used to indicate which words and phrases have been highlighted the most. This allows those who come to a text to identify the words and phrases that others have found important or interesting. Similarly, tag clouds within a particular site or topic area can help learners to get a sense of the overall area and keywords associated with it. This can be particularly useful where the tag cloud is combined with a collaborative filter showing recommended tags that appear with selected tags more often, as can be found in Delicious. By viewing associated keywords, the learner is able to make connections and see generalizations that situate a topic within a network of ideas and concepts.
Assessing Learning
Several social systems provide rating tools. In many cases, these are simply variations on good versus bad: simple “thumbs-up” links such as Facebook “Likes” or Google +1s, for example. Unfortunately, this is seldom valuable to a learner seeking feedback on the success of his or her learning, unless the context is highly constrained, because there is not sufficient information to identify the reasons for the “like.” It can, however, work reasonably well within a group, especially in a large group such as one found in a MOOC, if the meaning of “good” and “bad” has been explicitly identified within that context. In sets or nets, there are few opportunities to provide such constraints.
Moving beyond simple ratings, some systems contextualize ratings within specific sets of qualities or interest areas. This can provide far more useful feedback on learning, though typically at the cost of far greater complexity for the people contributing ratings. CoFIND (Dron, Mitchell, Boyne, et al., 2000), for example, allows learners to not just rate a resource as good or bad, but to use fuzzy tags known as “qualities.” Qualities are tags with scalar values attached, allowing their users to both categorize a resource and say that it is more or less good for beginners, complex, detailed, accurate, reliable, authoritative, well-explained, or nicely structured. This kind of rich feedback can be very helpful. However, it is harder to use qualities to tag items than to use more conventional discrete tags, because their users must not only provide a category but also a rating for it. Other systems such as Slashdot provide a more constrained list: its basic comment filter allows users to identify whether comments are insightful, informative, interesting, or funny, which assists in filtering content and also helps the poster to know how others feel about the post. Though not intended for assessment, LinkedIn endorsements provide an intriguing and effective way to use collectives generated from networks to judge an individual’s skills. Skills that have been tagged in a user’s profile may be endorsed by those who are in that user’s network, thus providing a collective view of a person’s accomplishments that is both bottom-up, and in aggregate, trustworthy. LinkedIn makes good use of reciprocity, social capital, and individual vanity: when someone has endorsed you, it is hard to resist viewing your growing list of endorsements, and the site then prompts you to endorse others based on the skills identified in their profiles.
Selecting and Filtering Resources and Tools for Learning
The selection and filtering of resources and tools for learning is an important role for most teachers and is, in principle, what collectives do best. This is the role that Google plays when providing us with search results, using many collective processes to help assure quality and relevance of the results that it provides. Likewise, when Amazon provides recommendations of books we may want to read, it employs item- and user-based collaborative filtering techniques to make it likely that we will find something of value. Both are powerful learning tools, and this point has not been lost on the academic community. Over the past two decades, there have been many systems explicitly designed to use the crowd to recommend resources in a learning context (M. Anderson et al., 2003; Bateman, Brooks, & McCalla, 2006; Chiarella, 2009; Drachsler, 2009; Dron, Mitchell, Boyne, et al., 2000; Farzan & Brusilovsky, 2005; Freyne & Smyth, 2006; Goldberg, Nichols, Oki, & Terry, 1992; Grieco, Malandrino, Palmieri, & Scarano, 2007; Huberman & Kaminsky, 1996; Hummel et al., 2007; Jian, 2008; Kurhila et al., 2002; Tattersall et al., 2004; Terveen et al., 1997; van den Berg et al., 2005; Vassileva, 2008).
These systems include approaches such as social navigation, swarm-based methods, collaborative filtering, rating, and many more. When done well, crowdbased approaches to recommending resources, parts of resources, people, and tools have many benefits. Many hands make light work, and a crowd (especially a diverse set) can trawl through far more resources than an individual teacher. Depending on the way the collective is constructed, crowds can also be wiser than individuals (Surowiecki, 2004), succeeding in identifying facts or quality where individuals may fail.
Resource discovery is of great value in a formal setting. Because of the focused nature of closed groups in educational institutions, resource databases can become an extremely valuable facility, allowing the group to engage in developing a read/ write course with relatively little effort. This offers a wide assortment of learning and practical benefits:
- It reduces the cost of course production
- It keeps the course current and topical
- It gives students a strong sense of ownership, which in turn increases motivation
- It provides a simple means of learning by teaching: selection of resources, combined with some ranking and annotation, encourages reflection on both the resource and the learning process (i.e., how and in what ways it is helpful to the learner in his or her own learning process)
- It multiplies the possibilities of finding good and useful resources, leading to a far greater diversity and range than a single teaching team could hope to assemble alone.
It is best if such systems include at least some form of collective ranking, so that students can vote resources up or down, or provide implicit recommendations by clicking on links that can be fed back to the crowd through social navigation features. If such a system is not available, the next best thing is the capability to annotate or comment on links other learners have provided: the presence of comments can act as a simple stigmergic indicator of interest, positive or negative—both have value. If the system itself does not allow anything of this nature, then it is better to either use a more free-form system such as a wiki, or to go beyond the managed environment and make use of systems such as Delicious or Furl to create closed lists of bookmarks where commentary and tagging is allowed.
Tag clouds are a potentially powerful means of making resource discovery easier in a group, once resources have been added to the system. Within groups they are often different from and can sometimes offer greater value than those in large networks, because they adapt more quickly to the changing foci of the group. In a teacher-dominated environment, they can provide a more constrained and closed folksonomy than one allowed to develop without such control, a sort of hybrid of top-down control and bottom-up categorization. In some circumstances this can be useful: a shared vocabulary, if understood by all, helps to make sense of a subject area as well as making it easier to locate relevant resources. By categorizing the world, the teacher is enabling students to understand it better.
Caring for Students and Student Learning
There are some vital things teachers do that are far beyond the grasp of collectives. As our analysis of transactional distance in collectives suggests, the psychological gap between collective and learner is about as big as it can get. We know that other people have helped the collective to provide us with information, structure, process, or design, but that does not help us to feel closer to them and there are virtually no ways they can care for us or what we do. Collectives are only part of a solution to providing a rich and rewarding learning experience, and some things are, at least for now, best left to humans. Having said that, collectives can provide a gauge to let us know that unspecified others care about us: the “plus ones” or “likes” from popular social sites can improve a sense of social well-being and worth, albeit seldom with explicit pedagogical intent. They can also provide support for establishing connections with those humans. There are even aspects of the caring role a collective can play. For instance, they can be used to help nurture and guide learners to become more engaged and motivated (Glahn, Specht, & Koper, 2007).
The field of learning analytics has been experiencing rapid growth in recent years. It draws from a variety of fields: web analytics, educational data mining, adaptive hypermedia and social adaptation, and AI. Its purpose is to uncover indicators of learning, obstacles to learning, and information about learning pathways to help guide learners’ journeys. For teachers, it improves teaching methods and discovers weaknesses and risks before they become too dangerous. Some have extended this purpose to include analytics that interest administrators, institutions, and employers of teachers but, though such uses can and do have an impact on learning, we are of the opinion that it is no longer about learning when the process is applied this way: it is more a question of teaching analytics or institutional data mining.
The value of learning analytics to a teacher’s ability to provide care is that it allows him or her to become a part of a collective, in much the same way that asking for a show of hands to check if students have understood a problem in a classroom uses the crowd to change behavior. Processed results that inform a teacher of the progress of students leads to changes in his or her behavior, and thus can help the teacher to provide more assistance when needed. For example, if analytics show that, in aggregate, many students are having difficulty with particular lessons or concepts, the teacher can be more supportive in those areas. Analytics can also help to identify particular learners or groups of learners who are at risk. It can help to uncover patterns in behavior for disparate students or identify commonalities that lead to difficulties. For example, if it appears that most of those who submit work after a certain date or who lack particular qualifications have difficulties, then the teacher can intervene to advise them of the dangers. In effect, the teacher becomes part of a crowd-based recommender system.
Dangers of the Collective
While collectives can play several teacher roles in a system, they do not always make good teachers. There are many ways in which a wise crowd can become a stupid mob.
The Matthew Effect
The Matthew Effect, coined by Merton (1968) from the biblical aphorism attributed to Jesus “Whoever has will be given more, and he will have an abundance. Whoever does not have, even what he has will be taken from him” (Matthew 13:12). In the specific learning contexts examined here, this saying can be interpreted as a result of path dependencies and preferential attachments that set in early in a collective system’s development. If the system affects behavior (e.g., it encourages clicking of one resource or tag, or suggests people with whom to connect), then those who gain an early advantage are far more likely to retain it and be more influential than those who come later. The rich get richer while the poor get poorer. A classic example of this is presented by Knight and Schiff (2007), who discovered that early voters in US primary elections have around twenty times the influence of late voters on the results. This is because media reports the relative swings of voters, which in turn influence those who are undecided as to how to vote. Voters want to make a difference, usually by being on a winning side or, occasionally, to defend a candidate in danger of losing. Similarly, Salganik et al.’s (2006) study of artificial pop charts, mentioned in Chapter 6 shows strong Matthew Effects on music preference.
Many collective systems suffer from this problem. Google’s search results are a particularly prominent sufferer from the Matthew Effect. Because Google mines for links that are treated as implicit recommendations (L. Page, Brin, Motwani, & Winograd, 1999), and because people are far more likely to click on the first few links in the search results (Pan et al., 2007), this means that they receive greater exposure to pages that are already popular. Of course, it is only possible to provide links to sites that one already knows about (Gregorio, 2003) so such links are more likely to appear in the future. Because Google commands such a large share of search traffic, the overall effect is quite large. Many systems provide checks and balances to prevent rampant Matthew Effects from overwhelming new or equally valuable resources. Some use deliberate decay mechanisms (Dron, Mitchell, Boyne, et al., 2000; Wong & Looi, 2010), some introduce deliberate random serendipity, while others, including Google and Facebook, use a wide range of algorithms, collective and otherwise, to massage results so that there are no single persistent winners.
Unfortunately, many collectives occur without deliberate planning or forethought. For example, the presence of many or few messages in a discussion forum can act as an incentive or disincentive to others to contribute to a discussion, or a rating system can be used, as in Salganik et al.’s (2006) study that does not prevent runaway preferential attachment. The spread of viral memes in a population is another example of the Matthew Effect in action, where repeated exposure from multiple channels spreads through a network with increasing repetition (Blackmore, 1999).
Filter Bubbles and Echo Chambers
As Pariser (2011) observes, collectives play a very large role in the creation of filter bubbles. A recommender system, be it Google, Amazon, Slashdot, or any other system that filters and weights resources according to implicit or explicit preferences, runs the risk of preventing us from seeing alternative views to those we already hold or accept. This can function recursively and iteratively, especially where implicit preferences are mined on our behalves, creating a “bubble” over us that allows only similar ideas to those we already hold to penetrate. If what we see is limited to a subset of possibilities, then there are great risks that we will increasingly be channeled down an ever more refined path until we only see people we agree with and things we already know. For learners who, by definition, wish to move beyond their present boundaries, this can be a particular issue. As long as there are many alternative channels of knowledge this is not a major problem, but with increasing aggregation of data through things like tracking cookies, especially when we are using more personal devices like smartphones and tablets, the number of channels is quickly diminishing.
In a single browsing session, Felix (2012) reported that Facebook alone sets well over 308 tracking cookies without the user granting any explicit permissions, and these can be used by any subscribing sites to customize content and presentation. The lesson this teaches is that it is not always wise to join Facebook, but if one does, blocking tracking cookies using browser add-ons like TrackerBlock for Firefox, or AVG’s (currently free) do-not-track browser add-on may help to prevent many recommendations based on past activity. A simpler but less reliable approach is to ensure that one is not permanently logged in to a particular commercial social system. The penalty to be paid for such methods is, however, a loss of functionality: things such as Facebook “like” buttons will no longer work, for example. While one of the worst offenders, Facebook is far from alone in performing wide-ranging tracking. Google’s many services, for example, make extensive use of knowledge about who you are to shape the kind of results you receive from their search engine.
Sub-Optimal Algorithms
To err is human, but a collective can really make a mess of things. While the results of a Google search or a recommendation from Amazon or Netflix can be remarkably useful and accurate, they can equally be off the mark, unsuitable to our learning needs and, even if valuable, there may be better alternatives. The recommendations of collectives may be better than those that come from the reflective and critical skills of a human curator, but it depends on many things, notably the selection pool, the algorithm employed, the means of presentation, and the kind of problem being addressed. Despite the best efforts of many researchers and developers, we are some distance away from a perfect set of solutions for all learners and contexts.
Deliberate Manipulation
Another problem with collective systems is that it is hard to build them in a manner that prevents abuse by those who understand the algorithms and presentation techniques they employ. For example, author Dron had a student who added his own work to a self-organizing link-sharing collective system, and who then made use of the naïve social navigation methods the system employed to emphasize and de-emphasize tags, (which was little more sophisticated than a clickthrough counting system at the time), to promote his own website. Although the system did stabilize in the end as people realized where they were being sent and found it wanting, for a while his site became quite popular. More problematically, the experience left other students feeling less trust in the system. It would be nice to think that this problem had gone away with the increasing sophistication of social systems but, at the time of writing and for at least the past year, Flickr’s recent tags are dominated by advertisements and other more dubious content that fails to represent the wisdom of the crowd and results from intentional abuse. This particular collective within Flickr is to all intents and purposes useless but, sensibly, Flickr employs a wide range of other collectives at different time scales capturing different actions so that they may still be usefully employed to find things of good quality and interest to many.
Loss of Teacher and Learner Control
Like networks and sets, collectives pose issues of control that take away some of the traditional power of the teacher in an educational environment. Author Dron has been writing and using collective applications since 1998 and has experienced both more and less delightful results. For example, when he placed his own lecture notes in a collectively driven link-sharing system, (which used advanced tagging and annotation along with self-organizing algorithms to raise or lower resources in ranking according to perceived usefulness), he found that they did not always stay at the top of the list, and once vanished into the second page of results. While it is possible that his notes were terrible, previous evaluations of them had been good and they had been used internationally by other teachers. Instead, this seems to be a positive sign that the collective was better and made more useful recommendations, a supposition borne out through interviews and observations (Dron, 2002) but still potentially bruising to a teacher’s ego.
Lack of Pedagogical Intent
Most cybersystem users have “wasted” time following links suggested by systems. Learning is hard work, and more often than not requires focused effort. Collectives are not great at reinforcing such solitudes. The wisdom of the crowd requires the crowd to share a purpose of learning. For example, when using a system with a combination of wiki- and MOOC-like elements which are self-organized according to a combination of stigmergic principles and a design inspired by Jane Jacobs’s principles of city design (Dron, 2005b), postgraduate students studying the effects of using communication technologies actually wound up creating a set of resources about chocolate, which interested them more than the subject at hand. Apart from the students’ interest in chocolate, there were two main causes of this: on the one hand, this was group work and a poorly defined context and lack of direction made it unclear what was expected. On the other, the process was self-reinforcing and ran out of control, a common problem in stigmergic systems, whereby the rich get richer and the poor get poorer (the Matthew Effect). The combination was good for learning about chocolate, but less effective as a means to think about how we are affected by communication technologies. This was an experimental system, and the episode helped to establish and refine principles for limiting such divergence that we discuss in this chapter.
Shifting Contexts
A collective that has evolved for one purpose may be counter-productive when used for another. For example, collaborative filters that identify preferences based on past preferences may be of little or no value to learners because, having learned what they need to, they no longer require similar things (Drachsler et al., 2007; Dron, Mitchell, Boyne, et al., 2000). In a different context, we need a different collective.
Design Principles for Collective Applications
Collectives are predicated on the existence of collections of people, whether in groups or networks. A collective application, perhaps to a greater extent than network, set, or group applications, is potentially far more influenced by the designer, so it is no coincidence that this section of this chapter is larger than those on designing for social forms.
As a cyborg, a collective consists not only of the actions and decisions of individuals but also of the algorithms and interfaces designed by its creator. People are the engine that drives the vehicle, and on occasion perform most of the work in giving it form and function (for instance, in deciding whether the level of threading in a discussion forum is too great or too little to be of interest), but the vehicle itself usually plays a far more significant role in the application than in those designed for networks and groups.
It is important to identify those elements that relate to each of the stages of a collective application: selection, capture, aggregation, processing, and presentation. This must include the things that our programs will do, what we expect people to contribute, and which actions to monitor. Without such a guiding heuristic model, we are likely to be surprised by the results.
In the following subsection we provide a range of issues and heuristics to be considered when designing collective applications for learning. It is not difficult to create a collective application, but it is more complex to create one that helps people to learn. This is very much an overview of large design patterns rather than a guide to building collective applications for learning. Knowledge of collective intelligence mechanisms such as Pearson Correlation, Euclidean Distance, neural networks, and Bayesian probability is very useful, even essential if one is to seriously engage in building such systems, but we will not be covering these technical issues here. Instead, we refer programmers who are interested in the mechanics of collective applications to Segaran’s Programming Collective Intelligence (2007), which is an excellent primer on the topic and relates almost exclusively to the kind of collective we speak of here. The socially constructed wiki, “The Handbook of Collective Intelligence,” (scripts.mit.edu/~cci/HCI/index.php?title=Main_page) is a more formal but less practically oriented treatment of the topic that also covers related ways of thinking about collective intelligence.
Parcellation
As Darwin (1872, chapter XII-XIII) was the first to observe, parcellation is an important feature of an evolving system. This is especially significant when considering large sets, nets, or groups of a tribal form. Without some means of separating out smaller populations, path dependencies mean that the Matthew Effect keeps the successful at the top of the evolutionary tree and makes a system highly resilient to small perturbations, such as new or different ideas. To enable diversity, the evolutionary landscape must be parcellated in some way. This is why many of Darwin’s greatest insights came from his visit to the Galapagos Islands, where different species had evolved in isolation. In a learning context, a massive site like YouTube would be of little value if it were not possible to separate out subsections: videos of cats would likely overwhelm those of broader educational value. Similarly, it is possible to parcellate according to temporal scale, paying more attention to, for example, recent and topical items than to an entire body of posts spread over many years. To illustrate the issue, tagging systems in large networks have a tendency to display very uniform and bland sets of tags. For example, over the past six years, over 80% of the most popular Flickr tags have stayed the same, despite a massively growing and presumably changing collection of people that use the system.
The reinforcement caused by existing tags combined with a stable set of generic interests in photography—the tag list includes many obvious ones such as “portrait,” “landscape,” and “black & white.” This means that the list remains very stable over time. Of the less than 20% of tags that changed in that period, most were related to large-scale shifts in interest caused by external factors, such as the season of the year and the popularity of movies. In 2005, for example, New Zealand was a much more popular tourist destination as a result of the Lord of the Rings films than it is today. Smaller groups, conversely, will create tag clouds of popular tags that change as the needs of the group evolve, reflecting change as it occurs. Small populations are more dynamic, and follow the same pattern of parcellation that we see in populations rapidly evolving in natural environments. This situation points again to the importance of parcellation: the smaller the subset, the more likely it is that relevant content will be discovered because the collective will be operating within a more precise context. Evolution happens fastest in small, isolated populations (Darwin, 1872; Calvin, 1997). Natural ecosystems exist in a highly variegated landscape that is frequently divided by borders which species find hard or impossible to traverse.
Relationship of Collectives with Groups, Sets, and Networks
Collectives may form in any size group or network. However, while a number of collectives have equal applicability whether they arise in groups, sets, or networks, some kinds are more relevant to one than the other. For example, in closed groups it is rarely a significant issue to identify the trustworthiness, reliability, and roles of members: it is part of the definition of a group that there will be leaders, that people will know or could come to know other members, and that shared norms and supportive behavior will arise. In sets, this is far from the case, and there are many collective applications concerned with discovering and establishing reputation, from eBay to Slashdot. Conversely, the fact that we do know more about the goals and needs of people within a group makes some kinds of collective application more effective in groups than in sets. For instance, simple rating systems, especially in large networks, are seldom effective in sets because the needs of people across the set vary widely. However, in a closed group, simple ratings can give an accurate and useful reflection of a group’s opinions and beliefs that is valuable within that closed context. In networks, the greatest value of collectives is in mining connections between people to identify relevance. Often, such recommendations are hybrids that also consider set attributes. Facebook’s EdgeRank, for example, takes into account professed interests and keywords extracted from content users post or read.
Evolution
Because the content of social sites largely comes from users, they are shifting spaces and, in many set and net forms, there can be a great deal of content of extremely variable quality. Especially once we start to employ collective processes to organize this information, a social site may be seen as a bottom-up organization, an ecology of multiple postings, discussions, videos, podcasts, and more, all competing with one another. As in natural evolution, there is replication with variation. Good ideas spread and become refined, changing to fit the perceived needs and interests of their viewers and participants. When designing a collective system it is therefore important to mindfully introduce selection pressure, prevent out-of-control Matthew Effects, and allow the crowd to sculpt the collective as efficiently as possible. This can be achieved in many ways, through active culling of poorly rated resources, the use of weighted lists through tag clouds or ordered search results, capturing successful paths, and selective or weighted display, among other things.
Diversity
For evolution to occur there must be sufficient diversity so that novel solutions have a chance to compete. The Matthew Effect may stifle diversity but, especially in groups, there is also the risk of groupthink setting in. Parcellation is one way to assist diversity, but it is equally important to create isthmuses between populations, to allow ideas and problems to seep beyond isolated islands. A little randomness can go a long way: it is worthwhile to introduce random results here and there that allow novel and seldom-used resources to be shown.
Constraint
Like natural systems, the evolution in a social site exists within a landscape. Some aspects of this landscape are comfortably familiar—spatial layouts, structural hierarchies, colors, and pages. Others have more to do with process—the algorithms, formal or informal rules, and temporal constraints imposed by the software. How we build the landscapes in which collectives form can have a massive impact on their effectiveness. Whenever we make a design decision regarding the structure or behavior of our software, we are shaping the landscape in which the ecosystem will develop: if we create oceans, we will get fish. If we build mountains, we will get mountain goats. Constraints can be very useful, allowing the designer to consider not just a broad and unspecific crowd but also one that is using the system with the intent to learn. For example, it may be a valid and helpful constraint to deliberately filter out certain forms of content from the results based on the target audience, or to create top-down categories that relate to anticipated interests. Active shaping can also be used to specify the kinds of activity the user is expected to engage in and make learning more purposeful. For example, using wording like “provide tags that describe the value of this resource to you as a learner” can help maintain a focus on pedagogical rather than less valuable tags.
Very few attempts to use collectives thus far have embedded more than a passing attempt at pedagogy. Collectives have been used as tools within a broader pedagogically driven context, applied within a constrained traditional group context, or relied on as simplistic models of human learning. There is a desperate need for programmers to design systems that use collectives with pedagogic purpose and an architecture built for learning, and to do so in the open world of sets and nets rather than the closed academic groups that most adaptive systems have been created for, if they are to reach their full potential. Google is a wonderful learning technology, but it is not designed explicitly for learning and often recommends resources that are not ideal for a learner’s needs.
Context
Particularly in educational settings, the broader context in which we use our social software can play a crucial role in determining the shape it takes. For a collective to have value, it should be derived from and used in a context that relates to current learning needs. As we demonstrated with the group of communication studies students who taught one another about chocolate, it is very easy for a collective to bend to a different set of needs and interests than those that are of most value. In some cases, context can be flexible. Collaborative filters, for example, typically base their recommendations on past interests, which may be poor predictors of value when context changes; but with small adaptations that allow a learner to deliberately specify interests at the time of searching, these filters can still be useful as long as others in the crowd have also specified similar contexts. Unless a system is extremely tightly focused, tags and/or pre-specified categories or topics can help to make a context clear. Tags are most useful when there are alternative means of ensuring that ambiguities will be minimal, for instance by limiting results to those of a specified sub-community through categorizations or special-purpose sites, or by making use of collaborative filtering mechanisms to identify people with similar needs and interests. Another way to make context more relevant is to consider recent items preferentially to overall items rated, increasing the chance that the results are relevant to the current context. This helps to deal with the problem that, once we have learned something, we rarely need to see other resources to help us learn it some more. In some systems, such as CoFIND (Dron, Mitchell, Boyne, et al., 2000), a decay weighting, proportional to relative activity and use of the system, is applied to older resources so that they disappear from the list of recommendations.
Scrutability
Many of the algorithms that generate collectives in cyberspace are trade secrets, jealously guarded by their owners. Outside of Google, Amazon, Facebook, and similar commercial organizations, and beyond the relatively small amount of published work they produce, we can only guess at the means they use to aggregate the wisdom of the crowd to shape our experiences. Where possible, the behavior of algorithms and the decisions that they make should be explicit, or at least be discoverable. If possible, users should be able to adjust the workings of algorithms and what they display to suit their changing needs. For an end user, however, it is not necessarily a bad thing that some of the details are kept secret. As Kay and Kummerfeld (2006) and Dron (2002) have discovered, while scrutability of algorithms and the ability to adjust weightings is much to be wished for, it increases the complexity for the end user, often with little or no benefit. One way to reduce that complexity is to provide templates, wizards, or a fixed range of settings that fit most needs. However, for those willing to make the effort to fine-tune the collective to their needs, it should be possible to access a wider range of settings as well. Amazon provides a good example in making use of broad-brush algorithms by default, but allowing individuals to provide explicit ratings to improve their recommendations, and to specify items to exclude from the pool used for recommendations. In principle, it is better to allow people to make adjustments at the time when they are needed, rather than as a general setting, but this again increases cognitive complexity.
Conclusion
This has been a long chapter that, though it has covered much ground, has barely scratched the surface of the teaching and learning benefits of using collectives. We think it is worthwhile to spend time on it because collectives are central to opening up cost-effective, responsive, socially enabled lifelong learning. We have seen that nets and sets afford rich and varied opportunities for learning but, unlike groups, they are not technological forms and thus do not provide the supporting processes that have evolved over hundreds of years of educational group use. Collectives have the potential to be organizers of learning, teaching presences that can guide and assist learners according to their needs, while allowing them to retain control of the learning process and engage in rich, social learning. Although we have had collectives since the dawn of human civilization, the scale of cyberspace and the potential of social software to generate new and more complex forms of collective makes it perhaps the most significant distinguishing feature between the new generation of online learning and what came before it.
The capacity to examine large-scale networks, and especially sets, allows us to catch glimpses of the group mind that were invisible before, and exploit crowd wisdom in new and pedagogically valuable ways. The dangers of mob stupidity should not be underestimated, however. In entrusting our learning to the crowd we are also entrusting it to the algorithms, both within the minds of the people in the crowd and in the software that aggregates and transforms their use. Careful design of collective applications for learning and mindful awareness of their strengths and weaknesses can go a long way to increasing their reliability, but it is also important for learners and teachers to develop collective literacy: to know what collectives are doing, how their learning experience is being shaped by them, and to know where the dangers lie. In chapter 9 we explore these and other dangers of social software in greater depth.