Constituents
We have seen that the situations in the world that people tend to notice and talk about are construed as states or events involving a small number of participants. We can expect the sentences that designate states or events to have a word that specifies the kind of state or event, usually a verb, and a phrase for each of the participants that the speaker chooses to refer to. Each of these makes up a part, orconstituent, of the whole sentence. Before we can look at how different languages put sentence constituents together to designate states and events, you will need to know more about what makes up a constituent. In this section we'll be focusing on the constituents that refer to the participants in the state or event. And for these constituents we'll be focusing on their internal structure, what words can make them up.
Let's return to where we left our Grammies. Once they have the insight that it is to their advantage to be able to talk about events and states, the next step might be to come up with words for the different categories of states and events, verbs, that is. In the simplest case, then, we can imagine describing events and states with verbs alone, for example, recovered for a recovery event or gave for a giving event. In some modern languages, such as English, the grammatical conventions don't permit sentences like this consisting only of a verb, but in languages such as Japanese, they are possible. So the following are grammatical Japanese sentences.
- naotta 'recovered'
- ageta 'gave'
The first sentence means that somebody recovered; the second means that somebody gave something to somebody else.
But even in Japanese, these one-word sentences can only go so far. Unless it is clear from the context, the hearer may have trouble figuring out who the patient (the person recovering) is for sentence 1 and who the agent and the recipient and what the patient is for sentence 2. Such sentences are massively ambiguous and only interpretable when the context makes it very clear who the participants in the events are. Something else is needed.
Noun Phrases
Exercise \(\PageIndex{1}\)
Look at the function of the word Clark and the phrase the guy who is out to save the world in these sentences.
- Clark got sick.
- The guy who is out to save the world got sick.
Even though these expression look quite different, how are they similar in their function?
Compositionality Applies to Sentences as Well as to Modifier + Noun Combinations
Faced with this sort of ambiguity, the Grammies hit upon the same idea that they had used earlier on to make it easier to refer to things, the principle of compositionality. Remember from the last chapter how this works. Words combine into phrases, and the meaning of the whole phrase depends on the meanings of the individual words. Here's a simple English example.
- Fred recovered.
We know from Chapter 2 that a proper noun like Fred can refer directly to an individual, making this the easiest way to make the Hearer aware of who is being talked about. By compositionality, we get the meaning of sentence 3 by figuring out the conventional meanings of each of the words, Fred and recovered, which are available in our lexicon, and then applying the appropriate grammatical rule to combine the meanings. We'll talk about the grammatical rule in the next section. For now, the important point is that the meaning of sentence 3 can be derived from the meanings of Fred and recovered and what we know as speakers of English about the grammar of English sentences.
But we also know from Chapter 2 that it is impractical to have a name for every thing we might want to refer to, and in any case, no speaker can know all of the names there are. So if the speaker of sentence 1 hadn't known Fred's name, the sentence would have come out differently, perhaps like this one.
- The teacher recovered.
Even though the phrase the teacher in sentence 4 and the word Fred in sentence 3 consist of completely different words, they are doing the same work in the two sentences, referring to a particular individual. But there are many other ways the Speaker could refer to Fred, depending on the utterance context, what the Speaker knows about Fred, and what the Speaker believes the Hearer knows about Fred. Here are a few possibilities.
- He recovered.
- That teacher recovered.
- My teacher recovered.
- That tall teacher recovered.
- The teacher behind me recovered.
- The teacher who got fired recovered.
Expressions Referring to Things Have Their Own Internal Structure
In each sentence the part before recovered refers to the person who recovers (the patient). These phrases do not all mean the same thing, but in one sense they all dothe same thing. And with respect to just form and not meaning, we can see that they all share the property of being possible phrases before a verb like recovered in a sentence. All such phrases are called noun phrases (abbreviated "NP"). An NP need not actually contain a noun; for example, the NP in sentence 5, he, does not. But the prototypical NP does contain a noun. This noun is called the head of the NP; this is a term we already saw in the last chapter.
English Noun Phrases
Exercise \(\PageIndex{2}\)
How are the words in boldface in the following phrases similar to one another?
- a friend
- a new friend
- the friend
- the old friend
- that friend
- that particular friend
- your friend
- your crazy friend
What else can an English NP contain? One possibility is an adjective, for example, in the tall teacher. In English this always comes before the noun. In fact an NP can have more than one adjective: the tall sick teacher. We can think of an NP as having a set of positions or slots in which words can appear. There is a position for the head noun, and a position for one or more optional adjective modifiers. We can denote these possibilities as follows, where adjective and noun are abbreviated as "Adj" and "N".
Adj* N
The "*" after "Adj" means that some number of adjectives, including zero, are possible.
But note that tall teacher is not really a grammatical NP; it requires a word such as the or a before the adjective. If we looked at a lot of English noun phrases, we'd discover that these words always precede the adjectives in a noun phrase if there are any adjectives. We'd also discover that there are a number of other words that can appear in this same position, that is, at the beginning of an NP and before any adjectives. These words include that, this, some, my, and your. We'd also discover that English doesn't permit more than one of these words in a given NP. We can't say things like the my boss (though such combinations are possible in some other languages). This position in the NP is called the determiner position, and we can also use this word to refer to the words that can fill that position. So now we can denote the structure of NPs that have a common noun such as teacher as follows, using "Det" to mean determiner.
Det Adj* N
Semantic Roles and Syntactic Roles
In plain English, this expression says that an NP can consist of a determiner followed by some number of adjective modifiers (including none) followed by a head noun.
We are by no means finished characterizing the structure of English NPs, but it is useful to summarize what we have so far. English NPs have three positions in them that can be filled by words. Just as we can speak of the roles in an event or state, we can speak of the roles in a phrase. But since with a phrase we are concerned with linguistic form rather than meaning, these are syntactic roles, rather than semantic roles. As with semantic roles, we can distinguish the role from the category of things that fills the role. For example, the source and the goal in an instance of move are both filled by things belonging to the category place. For phrases, we can talk about either the categories of the words that make up the phrase or the roles that the words play in the phrase. For NPs, the roles we have seen so far are the following, where "PreMod" means "pre-modifier", a modifier that comes before the head. Note that for the determiner, we use the same word for the role and the category.
Det PreMod* Head
If we look at more NPs, we will see that this structure doesn't fit them. In sentence 9 above, the NP takes the form the teacher behind me. Here the phrase behind mefunctions as a modifier within the NP. Just as an adjective can modify a noun by narrowing down the category of things to those with a particular attribute, a phrase such as behind me can narrow down the category of things to those members of the category that are in a particular location.
In sentence 10 there is another example of a modifier following the head noun. In this sentence the NP is the teacher who got fired. Within the NP the phrase who got fired behaves like a modifier; it narrows down the category of things designated to members who got fired (that is, who are the patients of a firing event).
The NPs in 9 and 10, then, can both be denoted as follows, where "PostMod" means post-modifier, a modifier that follows the head noun.
Det Head PostMod
How Syntax and Semantics are Different and the Same
There are two important points to note about the syntactic roles in NPs. First, unlike for semantic roles, there is a sequential order to these roles. The expression above does not only mean that an NP can have a determiner, a head noun, and a post-modifier; it means that they appear in that order. Second, the roles can be filled either by single words — the determiner in the teacher who got fired — or by whole phrases — the post-modifier in the teacher who got fired. That is, the constituents of phrases can themselves be words or phrases. In fact, an NP can have another NP inside it; for example, the NP the teacher in front of me contains the NP me. Since an NP can contain an NP, we should not be surprised to see NPs that contain NPs that contain NPs, for example, the teacher next to the door that leads to the exit. In fact there is no obvious limit to this process.
We can also make more complex NPs in English by adding additional post-modifiers, as in the teacher that got fired that I told you about. It is also possible to combine pre-modifiers and post-modifiers in the same NP, as in the tall teacher that I told you about. If we want to capture all of these possibilities in one schema, we can write the following.
Det PreMod* Head PostMod*
This says that an NP can consist of a determiner followed by some number of pre-modifiers (including none) followed by the head noun followed by some number of post-modifiers (including none). We can also diagram this as we did with schemas for events and states. The dotted lines indicate constituents that can be absent, and the arrows indicate the order of the constituents.
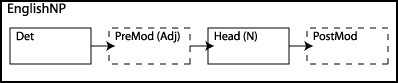
Let's summarize what we've learned about English NPs. They serve as constituents in sentences, where (in one of their functions) they refer to the participants of the state or event that the sentence designates. That is, they have a particular function to perform within sentences. They can consist of as few words as one, and there is no clear limit on their maximum length. They can be described as consisting of constituents, parts that are either words or phrases in their own right and that fill particular syntactic roles in the structure of the NPs. For compositionality to work, there should be a grammatical rule for each of these roles that specifies how the meaning of the whole phrase depends on that role. In the last chapter, we saw informally what some of these rules would look like.
Note how NP form and meaning resemble each other. On the meaning end, we have the thing referred to with a number of properties, all of them localized in a single bounded region of space. On the form end, we have a group of words occurring together within a sentence, that is, not separated by words that belong to other constituents. This is a weak example of iconicity because it involves an aspect of form (coherence) that applies to meaning as well. The tendency for the words that make up a constituent to occur together is quite strong among the languages of the world, though there are some exceptions where other principles can override this tendency. The tendency for words that behave as units on the form end to behave as units on the meaning end of language is what I will call constituency.
Before we leave English NPs until the next section, it is worth saying that we are far from characterizing adequately the structure of English NPs. The schema above implies that all NPs with a noun head have a determiner, but there are perfectly grammatical English NPs such as fresh cheese and rocks that do not. It is also possible for a pre-modifier to be a phrase itself, as in the extremely tall, slighly bald teacher. Finally, the determiner can also be a phrase, as in my sister's teacher. But all of this goes beyond the scope of this book.
Lingala Noun Phrases
All languages seem to resemble each other in having phrases for referring to the participants of events. Most languages have a category of common nouns that can play the role of head in these phrases; that is, these languages have NPs like English. Many, but not all, languages also have a category of adjectives that can modify nouns. And probably all languages have at least some determiners, though many languages have no words corresponding to the English words the and a.
Let's look at NPs in Lingala as an example of a language that differs considerably from English. Here are the Lingala sentences that correspond to two of the English sentences above.
| 11 |
Fred |
abiki |
| Fred |
he/she:recovered |
| 'Fred recovered.' |
| 12 |
molakisi |
molai |
yango |
abiki |
| teacher |
tall |
that |
he/she:recovered |
| 'That tall teacher recovered.' |
Languages Tend to Have the Same Sorts of Constituents But to Differ in Their Conventional Order Within Phrases
From sentence 11, we see that Lingala is like English in allowing proper nouns to refer to things. From sentence 12, we see that Lingala is like English in allowing NPs with adjectives and determiners. It turns out that Lingala has very few adjectives, using alternative expressions in many places where English uses adjectives, but this won't concern us here. It also turns out that Lingala has no determiners corresponding to English the or a, but, as in the example, it does have words corresponding to English determiners like this and that.
Note how the order of the constituents in Lingala differs from English, however. We would have to look at a lot of NPs to make sure, of course, but the order of the constituents in 12 holds throughout the language. It also turns out that, unlike in English, there are never modifiers before the head noun. So the structure of Lingala NPs, at least those with common nouns as heads, appears to be as follows. The determiner is dashed to indicate that this constituent is often absent in NPs.

So one important way in which languages can differ is in the conventional order of the constituents. Each language will tend to have a preferred order, but the order may vary from language to language.
Armed with some idea of what NPs look like, we are ready to return to events and states. In the next section, we'll be concerned with how verbs combine with NPs to designate events and states.

