
8.8: Situation, Vision, and Action
- Page ID
- 41279

Why is Pylyshyn’s (2003b, 2007) proposal of preattentive visual indices important? It has been noted that one of the key problems facing classical cognitive science is that it needs some mechanism for referring to the world that is preconceptual, and that the impact of Pylyshyn’s theory of visual cognition is that it provides an account of exactly such a mechanism (Fodor, 2009). How this is accomplished is sketched out in Figure 8-8, which provides a schematic of the various stages in Pylyshyn’s theory of visual cognition.
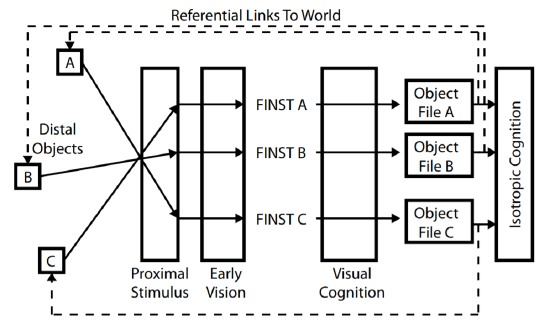
Figure 8-8. Pylyshyn’s theory of preattentive visual indexing provides referential links from object files to distal objects in the world.
The initial stages of the theory posit causal links from distal objects arrayed in space in a three-dimensional world and mental representations that are produced from these links. The laws of optics and projective geometry begin by creating a proximal stimulus—a pattern of stimulation on the retina—that is uniquely determined, but because of the problem of underdetermination cannot be uniquely inverted. The problem of underdetermination is initially dealt with by a variety of visual modules that compose early vision, and which use natural constraints to deliver unique and useful representations of the world (e.g., the primal sketch and the 2½-D sketch). Pylyshyn’s theory of visual cognition elaborates Marr’s (1982) natural computation view of vision. In addition to using Marr’s representations, Pylyshyn claims that early vision can individuate visual objects by assigning them one of a limited number of tags (FINSTs). Furthermore, preattentive processes permit these tags to remain attached, even if the properties of the tagged objects change. This result of early vision is illustrated in Figure 8-8 as the sequences of solid arrows that link each visual object to its own internal FINST.
Once objects have been individuated by the assignment of visual indices, the operations of visual cognition can be applied (Treisman, 1986, 1988; Ullman, 1984, 2000). Attention can be directed to individuated elements, permitting visual properties to be detected or spatial relations amongst individuated objects to be computed. The result is that visual cognition can be used to create a description of an individuated object in its object file (Kahneman, Treisman, & Gibbs, 1992). As shown in Figure 8-8, visual cognition has created an internal object file for each of the three distal objects involved in the diagram.
Once object files have been created, general knowledge of the world—isotropic cognitive processes (Fodor, 1983) can be exploited. Object files can be used to access classical representations of the world, permitting semantic categories to be applied to the visual scene.
However, object files permit another important function in Pylyshyn’s theory of visual cognition because of the preattentive nature of the processes that created them: a referential link from an object file to a distal object in the world. This is possible because the object files are associated with FINSTs, and the FINSTs themselves were the end product of a causal, non-cognitive chain of events:
An index corresponds to two sorts of links or relations: on the one hand, it corresponds to a causal chain that goes from visual objects to certain tokens in the representation of the scene being built (perhaps an object file), and on the other hand, it is also a referential relationship that enables the visual system to refer to those particular [visual objects]. The second of these functions is possible because the first one exists and has the right properties. (Pylyshyn, 2003b, p. 269)
The referential links back to the distal world are illustrated as the dashed lines in Figure 8-8.
The availability of the referential links provides Pylyshyn’s theory of visual cognition (2003b, 2007) with distinct advantages over a purely classical model. Recall that a top-down model operates by creating and maintaining internal descriptions of distal objects. It was earlier noted that one problem with this approach is that the projected information from an object is constantly changing, in spite of the fact that the object’s identity is constant. This poses challenges for solving the correspondence problem by matching descriptions. However, this also leads a classical model directly into what is known as the frame problem (Ford & Pylyshyn, 1996; Pylyshyn, 1987). The frame problem faces any system that has to update classical descriptions of a changing world. This is because as a property changes, a classical system must engage in a series of deductions to determine the implications of the change. The number of possible deductions is astronomical, resulting in the computational intractability of a purely descriptive system.
The referential links provide a solution to the frame problem. This is because the tracking of a FINSTed object and the perseverance of the object file for that object occur without the need of constantly updating the object’s description. The link between the FINST and the world is established via the causal link from the world through the proximal stimulus to the operation of early vision. The existence of the referential link permits the contents of the object file to be refreshed or updated—not constantly, but only when needed. “One of the purposes of a tag was to allow the visual system to revisit the tagged object to encode some new property” (Pylyshyn, 2003b, p. 208).
The notion of revisiting an indexed object in order to update the contents of an object file when needed, combined with the assumption that visual processing is embodied in such a way to be of limited order, link Pylyshyn’s (2003b, 2007) theory of visual cognition to a different theory that is central to embodied cognitive science, enactive perception (Noë, 2004). Enactive perception realizes that the detailed phenomenal experience of vision is an illusion because only a small amount of visual information is ever available to us (Noë, 2002). Enactive perception instead views perception as a sensorimotor skill that can access information in the world when it is needed. Rather than building detailed internal models of the world, enactive perception views the world as its own representation (Noë, 2009); we don’t encode an internal model of the world, we inspect the outer world when required or desired. This account of enactive perception mirrors the role of referential links to the distal world in Pylyshyn’s theory of visual cognition.
Of course, enactive perception assumes much more than information in the world is accessed, and not encoded. It also assumes that the goal of perception is to guide bodily actions upon the world. “Perceiving is a way of acting. Perception is not something that happens to us, or in us. It is something we do” (Noë, 2004, p. 1). This view of perception arises because enactive perception is largely inspired by Gibson’s (1966, 1979) ecological approach to perception. Actions on the world were central to Gibson. He proposed that perceiving agents “picked up” the affordances of objects in the world, where an affordance is a possible action that an agent could perform on or with an object.
Actions on the world (ANCHORs) provide a further link between Pylyshyn’s (2003b, 2007) theory of visual cognition and enactive perception, and consequently with embodied cognitive science. Pylyshyn’s theory also accounts for such actions, because FINSTs are presumed to exist in different sensory modalities. In particular, ANCHORs are analogous to FINSTs and serve as indices to places in motor-command space, or in proprioceptive space (Pylyshyn, 1989). The role of ANCHORs is to serve as indices to which motor movements can be directed. For instance, in the 1989 version of his theory, Pylyshyn hypothesized that ANCHORs could be used to direct the gaze (by moving the fovea to the ANCHOR) or to direct a pointer.
The need for multimodal indexing is obvious because we can easily point at what we are looking at. Conversely, if we are not looking at something, it cannot be indexed, and therefore cannot be pointed to as accurately. For instance, when subjects view an array of target objects in a room, close their eyes, and then imagine viewing the objects from a novel vantage point (a rotation from their original position), their accuracy in pointing to the targets decreases (Rieser, 1989). Similarly, there are substantial differences between reaches towards visible objects and reaches towards objects that are no longer visible but are only present through imagery or memory (Goodale, Jakobson, & Keillor, 1994). Likewise, when subjects reach towards an object while avoiding obstacles, visual feedback is exploited to optimize performance; when visual feedback is not available, the reaching behaviour changes dramatically (Chapman & Goodale, 2010).
In Pylyshyn’s (2003b, 2007) theory of visual cognition, coordination between vision and action occurs via interactions between visual and motor indices, which generate mappings between the spaces of the different kinds of indices. Requiring transformations between spatial systems makes the location of indexing and tracking mechanisms in parietal cortex perfectly sensible. This is because there is a great deal of evidence suggesting that parietal cortex instantiates a variety of spatial mappings, and that one of its key roles is to compute transformations between different spatial representations (Andersen et al., 1997; Colby & Goldberg, 1999; Merriam, Genovese, & Colby, 2003; Merriam & Colby, 2005). One such transformation could produce coordination between visual FINSTs and motor ANCHORs.
One reason that Pylyshyn’s (2003b, 2007) theory of visual cognition is also concerned with visually guided action is his awareness of Goodale’s work on visuomotor modules (Goodale, 1988, 1990, 1995; Goodale & Humphrey, 1998; Goodale et al., 1991), work that was introduced earlier in relation to embodied cognitive science. The evidence supporting Goodale’s notion of visuomotor modules clearly indicates that some of the visual information used to control actions is not available to isotropic cognitive processes, because it can affect actions without requiring or producing conscious awareness. It seems very natural, then, to include motor indices (i.e., ANCHORs) in a theory in which such tags are assigned and maintained preattentively.
The discussion in this section would seem to place Pylyshyn’s (2003b, 2007) theory of visual cognition squarely in the camp of embodied cognitive science. Referential links between object files and distal objects permit visual information to be accessible without requiring the constant updating of descriptive representations. The postulation of indices that can guide actions and movements and the ability to coordinate these indices with visual tags place a strong emphasis on action in Pylyshyn’s approach.
However, Pylyshyn’s theory of visual cognition has many properties that make it impossible to pigeonhole as an embodied position. In particular, a key difference between Pylyshyn’s theory and enactive perception is that Pylyshyn does not believe that the sole goal of vision is to guide action. Vision is also concerned with descriptions and concepts—the classical cognition of represented categories:
Preparing for action is not the only purpose of vision. Vision is, above all, a way to find out about the world, and there may be many reasons why an intelligent organism may wish to know about the world, apart from wanting to act upon it. (Pylyshyn, 2003b, p. 133)