Phonemic analysis is the process of analyzing a spoken language to figure out what its phonemes are, what the allophones are of those phonemes, and what each allophone’s distribution is. The resulting overall analysis is called a phonemicization of the language.
Note that a given phonemicization represents only one of many possible analyses. Languages do not generally have one single unique phonemicization, because there are many possible ways of dividing up the phones of a language into phonemes.
In addition, since phonemes are theoretical, abstract concepts, we have no direct way to see if our analysis is correct. Indeed, some linguists reject the notion of phonemes completely, since it is possible to analyze the phonology of a language without them. However, there is experimental evidence that speakers do make use of something phoneme-like, and until we are able to open up the human brain and find exactly how language is represented, phonemes are a reasonable analysis (see Chapter 13 for more information).
Simplicity
Even though we cannot know whether a given phonemicization, or any phonemicization at all, is correct, we can still compare different analyses and see which one is a better fit for the data and our assumptions.
In particular, if we have two competing phonemicizations that both account for all of the available data, we will generally prefer the simpler analysis (if there is one). This is the principle of simplicity. However, there is no single objective measure of simplicity, and it is sometimes possible to come up with two competing analyses that are seemingly equal in simplicity. In such cases, we might rely on other factors, but ultimately, we would normally be left in an ambiguous state.
Fortunately, the data sets you typically see in an introductory linguistics course have been carefully selected to have one obvious optimal phonemicization. But out in the real world, when we are working with raw linguistic data, there are often no obvious optimal analyses, so we may be less confident in whatever analyses we do come up with.
An example of phonemic analysis: Georgian laterals
To demonstrate phonemic analysis, consider the following data from Georgian, a Karto-Zan language of the Kartvelian family, spoken in Georgia (data adapted from Kenstowicz and Kisseberth 1979).
[vxlet͡ʃh]
‘I split’
[saxɫʃi]
‘at home’
[t͡ʃet͡ʃxli]
‘fire’
[kaɫa]
‘tin’
[zarali]
‘loss’
[pepeɫa]
‘butterfly’
[t͡ʃoli]
‘wife’
[kbiɫs]
‘tooth’
[xeli]
‘hand’
[ɫxena]
‘joy’
[kleba]
‘reduce’
[erthxeɫ]
‘once’
[leɫo]
‘goal’
[xoɫo]
‘however’
[ɫamazad]
‘prettily’
Step 1: Identify and organize the phones of interest
If we don’t have a particular set of phones in mind or want to phonemicize the entire language, we can start by searching for minimal pairs, or begin analyzing some small, simple natural class, such as the voiceless plosives or the front vowels. In introductory phonology assignments, you will normally be given the specific phones of interest.
For this demonstration, we have two specific phones of interest: an alveolar lateral approximant [l] (often called clear or light [l]) and a velarized alveolar lateral approximant [ɫ] (often called dark [ɫ]), which has the tongue back raised somewhat towards the velum as a secondary articulation along with the normal primary alveolar articulation. Many speakers of English have both of these two phones, with clear [l] at the beginning of a word and dark [ɫ] at the end, as in [lif] leaf versus [fiɫ] feel. For English, these two phones can be shown to be allophones of a single lateral approximant phoneme due to their complementary distribution and phonetic similarity, so we might wonder if the same holds true for Georgian.
Once we have selected a set of phones to study, we may want to organize them by natural classes. With only two or three, no grouping is normally necessary. But if we have four or more, we may find it helpful (we need to do this in Section 4.6 for an example from French).
For the Georgian lateral approximants, we should also keep in mind what makes them different. Here, the difference is between a raised tongue back for dark [ɫ], and no tongue back raising for clear [l]. Very often, we find that the distribution of a phone depends on properties related to its articulation, so if [l] and [ɫ] have complementary distribution, we might expect tongue backness of neighbouring phones to matter. Sometimes, however, there is no apparent phonetic relationship between phones and their environment, so we cannot rely on this as a universal strategy. Thus, while we should keep an eye on tongue backness in the environment, we should be open to other factors.
Step 2: Identify the individual environments of the phones of interest
With an understanding of how the phones of interest are related to each phonetically, we can create a diagram with the phones of interest listed across the top, and then, under each phone, we list out the individual environments it occurs in, word by word.
Most of the time, we can just look at what occurs immediately to the left and right of a phone to determine its environment, though sometimes, we may need to consider other information, such as syllabic position, stress, tone, or even phones that are farther away. The vast majority of the time, however, just looking at the immediate right and left will work.
For the purposes of compactness in notation when building such lists of environments, it is common to use the hash symbol # (a.k.a. number sign, pound sign, octothorpe, etc.) to mark a word boundary and an underline▁ to represent the position of the phone of interest. Thus, “#▁a” for [ɫ] indicates that there is some word in the data in which [ɫ] is at the beginning of the word and is followed by [a], in this case, [ɫamazad] ‘prettily’. Using this method for [l] and [ɫ] in Georgian, we would get the following lists of environments.
[l]
[ɫ]
x▁e
e▁o
x▁i
#▁a
a▁i
x▁ʃ
o▁i
a▁a
e▁i
e▁a
k▁e
i▁s
#▁e
#▁x
e▁#
o▁o
Each entry in these lists comes from one or more words. The very first word in the data is [vxlet͡ʃh] ‘I split’, which contains [l] in the environment x▁e, that is, it occurs between [x] and [e], so we enter x▁e in the column under [l]. The second word in the data is [t͡ʃet͡ʃxli] ‘fire’, which contains [l] in the environment x▁i, so we enter x▁i in the same column.
We continue in this way, word by word, entering all of the environments where we find each of the phones of interest. Note that if a word contains multiple instances of any of the phones of interest, we enter all relevant environments in the appropriate column. We see this with the word [leɫo] ‘goal’, which has the environment #▁e for [l] and e▁o for [ɫ], so both of those get entered into their respective lists.
Step 3: Determine overlap in environments
We first want to make sure that the phones are not in obvious contrastive distribution. If both phones have some of the exact same environments, then there is a good chance they are allophones of separate phonemes. Consider instead if we have constructed similar lists for English [p] and [k]. At some point, we would likely have entries like #▁ɪ and s▁u for both of them, due to words like pit, kit, spoon, and school. In that case, we would likely conclude that the phones are contrastive and should be analyzed as allophones of separate phonemes. We could then stop our analysis of those phones!
But for Georgian, we have to keep going, because there is no apparent overlap. We could still come to the conclusion that [l] and [ɫ] all allophones of separate phonemes, but we cannot base that decision on any overlap in environments in the data we have here.
Step 4: Simplify the environments
Looking at the left side of the environments for both phones, we see many of the same symbols: [x], [a], [e], [o], and #. There is not a lot of consistency on the left side, with no obvious natural classes in the left environment of one phone versus the other. However, on the right side of these phones, we see some repetition of phones and some natural classes within each phone’s list, rather than between the two lists, so it looks like the right environment may be crucial for discovering complementary distribution. Thus, we can simplify our analysis by ignoring the left environment. We can rewrite the lists by leaving off the left environment and removing any repeated entries, which gives us the following much simpler list of environments.
[l]
[ɫ]
▁e
▁o
▁i
▁a
▁ʃ
▁s
▁x
▁#
Now it is much easier to see what the distributions of these two phones are: [l] occurs only before the front vowels [e] and [i], while [ɫ] occurs only before the back vowel [o], the central vowel [a], the voiceless fricatives [ʃ], [s], and [x], and the end of the word. This is classic complementary distribution, because these are exactly opposite environments: front vowels are not back or central vowels, they are not voiceless fricatives, and they are not word boundaries. Neither phone of interest seems able to appear in the environment of the other.
Note how this pattern also fits our preliminary conjecture in Step 1 that the distribution of these two phones might have something to do with tongue backness, since that is precisely the property some of these environments differ in, specifically front versus back vowels.
Step 5: Organize the phones into phonemes
Since [l] and [ɫ] seem to be in complementary distribution, we might suspect they are allophones of the same phoneme. The question is, do they behave more like English [h] and [ŋ] (which speakers would normally conceptualize as belonging to different phonemes) or like English [iː] and [i] (which speakers would conceptualize as belonging to the same phoneme)? It is not always clear what to do in a given case, but we typically want to look for phonetic similarity.
The Georgian laterals have a lot of phonetic similarity: they have the same phonation (voiced), the same place of articulation (alveolar), and the same manner of articulation (lateral approximant); they differ only in secondary articulation (velarized or not). Thus, we have both complementary distribution and a high degree of phonetic similarity, so it seems reasonable to analyze [l] and [ɫ] as allophones of the same phoneme.
Step 6: Identify the default allophone and finalize the analysis
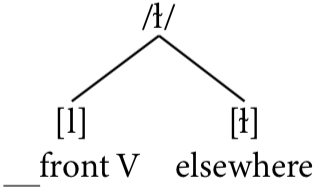
The default allophone of a phoneme is the one that occurs in the widest variety of environments, what we sometimes call the elsewhere case. For Georgian lateral approximants, the default is clearly [ɫ], since it occurs in many distinct environments that are all dissimilar from each other. By convention, we normally use the symbol of the default allophone to represent the phoneme unless there is good reason to do otherwise, so here, we would represent the phoneme containing [l] and [ɫ] as /ɫ/, since [ɫ] is the default allophone.
Note that the phoneme /ɫ/ and the phone [ɫ] are different kinds of objects, so this notation difference is crucial. Phonemes are theoretical abstractions that might also correspond to some kind of mental representation, while allophones are phones, which means they are concrete measurable sounds that are physically produced. The phoneme /ɫ/ corresponds to the set of allophones [l] and [ɫ], with [l] occurring before front vowels and the default [ɫ] occurring elsewhere.
Phonemes and their allophones are often depicted graphically in a tree-like diagram like the diagram for /ɫ/ in Figure \(\PageIndex{1}\). Here, we informally abbreviate “before front vowels” as ▁front V to save space in the tree.
Figure \(\PageIndex{1}\): Phoneme diagram for/ɫ/ in Georgian.
Predictions
This analysis makes predictions about laterals in Georgian beyond what we see in the given data. We would expect every clear [l] in Georgian to be followed by a front vowel, and we would expect every dark [ɫ] in Georgian to be followed by something other than a front vowel. All of the data we looked at agrees with these predictions, though we could still be wrong if we find new evidence that contradicts our analysis.
For example, we predict that [ɫ] should be able to occur before any consonant, not just voiceless fricatives, because it is the default case and should be appear in the widest variety of environment, while clear [l] is restricted to only appearing before front vowels. This is a testable prediction! We can look for more Georgian words and see what kind of lateral we find before other consonants. Fitting our prediction, we find only dark [ɫ] before consonants, as in [aɫq’a] ‘siege’, which cannot be pronounced *[alq’a] with a light [l].
Check your understanding
Query \(\PageIndex{1}\)
References
Kenstowicz, Michael, and Charles Kisseberth. 1979. Generative phonology: Description and theory. New York: Academic Press.